标签:技术分享 出图 ges 全局 png 分类 不难 max http
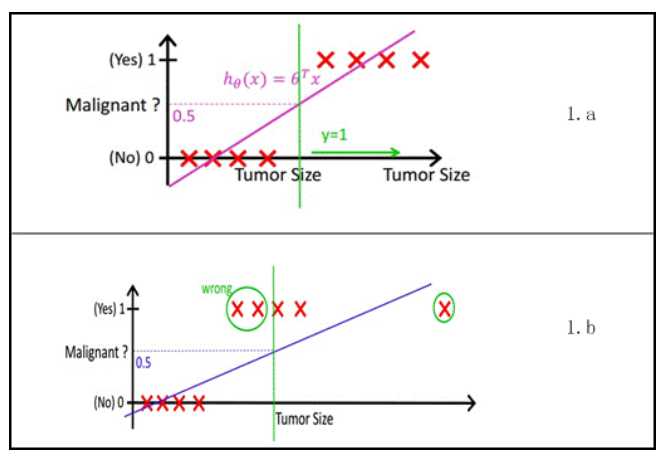
Logistic回归是目前最常用的一种分类算法。之前讨论了线性回归 http://www.cnblogs.com/futurehau/p/6105011.html,采用线性回归是不能解决或者说不能很好解决分类问题的,很直观的一个解释如下图所示,这里介绍Logistic回归。
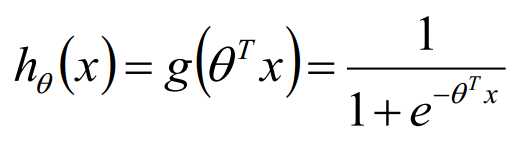
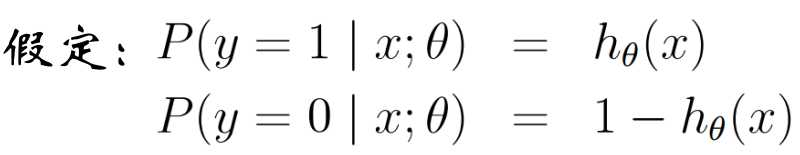
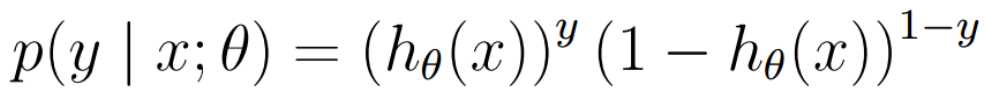
似然函数:
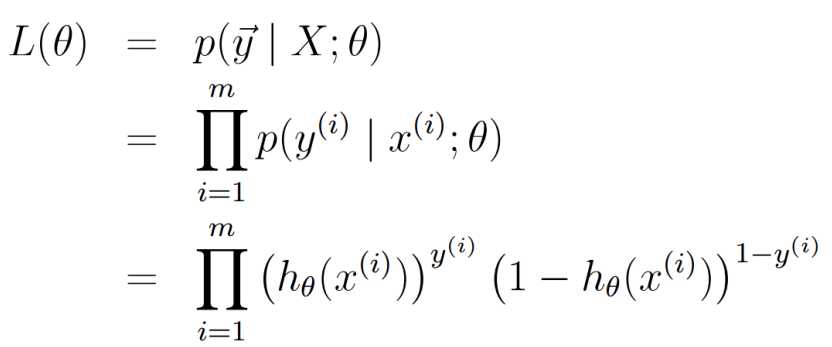
对数似然函数及其求导:
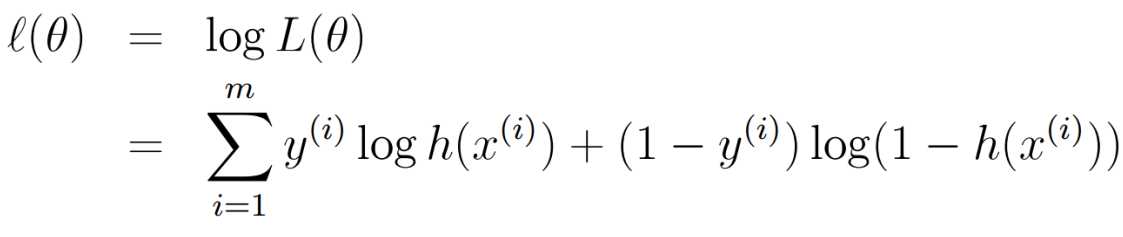
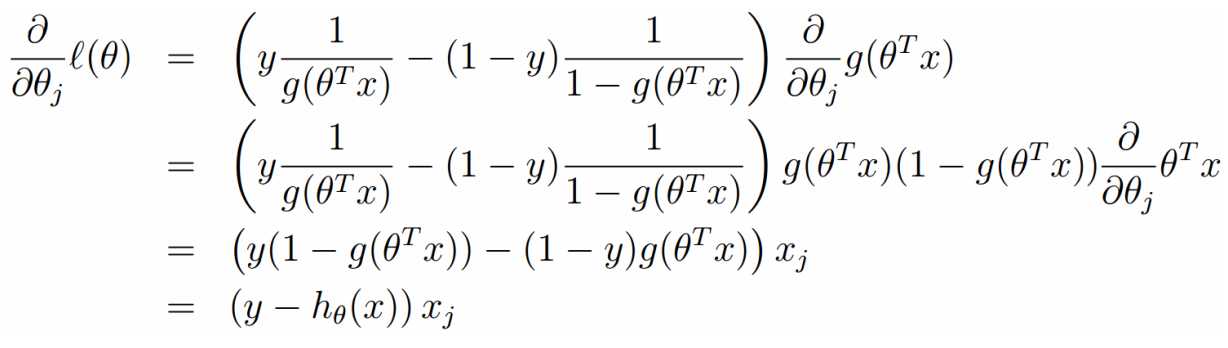
在线性回归中,我们得到代价函数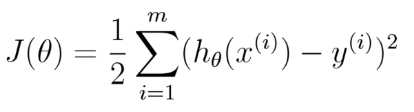 ,但是在Logistic 回归中,由于h(x)是一个复杂的非线性函数,这就导致J(theta)变为一个非凸函数,梯度下降算法不能收敛到它的全局最小值,所以这里我们需要重新引入别的代价函数。
,但是在Logistic 回归中,由于h(x)是一个复杂的非线性函数,这就导致J(theta)变为一个非凸函数,梯度下降算法不能收敛到它的全局最小值,所以这里我们需要重新引入别的代价函数。
我们上文推到了似然函数为,那么我们这里取代价函数为似然函数的负,这样对于代价函数的最小化就相当于似然函数的最大化。我们不难得到下面的代价函数:
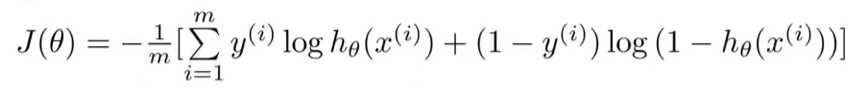
我们拆分开来看看是什么样子:
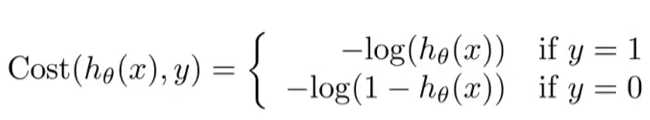
画出图来可以分析。如果 y= 1, 那么你预测 h(x) = 0 的代价就会非常高,预测h(x) = 1的代价就是 0。y = 0的情况同理。
二、Logistic回归的求解
线性回归中我们提出两种方法来求解theta,解析法和梯度下降算法。在Logistic回归中,没有解析解,我们使用梯度下降算法来求解。
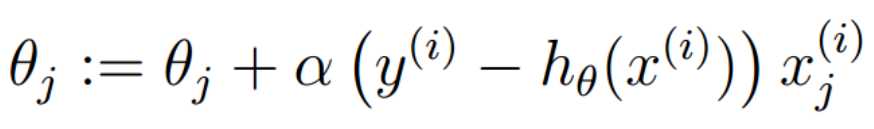
注意到这里是加号。其实上式既可以看为似然函数的正梯度上升,也可以把括号里面的负号拿出来之后变为损失函数的梯度下降。
我们发现,梯度下降算法求解Logistic回归和求解线性回归的梯度下降的式子形式上式一样的,区别在于两者的h(x)是不同的,那么这之中隐含什么东西呢?
我们现在考虑这样一个概念:
几率:一个事件的几率,是指该事件发生的概率与该事件不发生的概率的比值。
对数几率:几率取对数
所以,我们求几率如下:
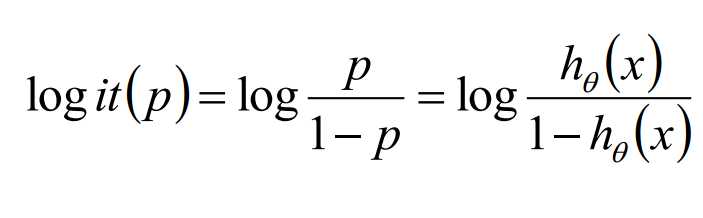
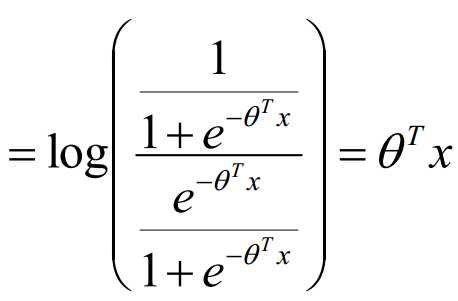
我们发现,Logistic的对数是线性的,这就相当于Logistic回归是一个广义的线性回归。对数线性模型。
当h(x) 大于 0.5时,我们判决为1,小于0.5时,我们判决为假。接下来我们看看这意味着什么。
h(x) > 0.5 需要 theta * x > 0。当theta确定之后,这会得到关于x1,x2(只考虑二维)的一条曲线,把整个平面分为两部分,满足theta * x > 0的部分就取为1。
我们引入 theta * x = 0 为决策边界。决策边界和训练集没有关系,训练集是用来拟合参数theta的,theta确定之后,决策边界就确定了。
之前我们讨论的都是二分类问题,多分类问题一方面可以使用多个one Vs all 做二分类,分别训练每个h(x),分类的时候找出最大的那个h(x)。
理解还不是很清楚,关于这部分的一个解释:http://deeplearning.stanford.edu/wiki/index.php/Softmax%E5%9B%9E%E5%BD%92
标签:技术分享 出图 ges 全局 png 分类 不难 max http
原文地址:http://www.cnblogs.com/futurehau/p/6107113.html