File(File parent, String child); // 根据父抽象路径和子路径创建文件对象
File(String pathname); // 指定文件路径创建文件对象 File file = new File("E:\\1.txt"); 并不是创建文件
File(String parent, String child) // 两部分构建
(5)获取文件的父路径
(6)最后一次修改时间
5、文件夹相关
(1)列出所有的根目录
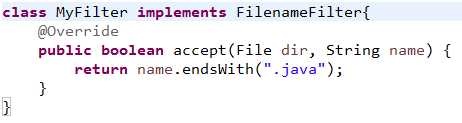
(2)把当前文件夹下面的所有子文件名与子文件夹名(不包括孙)存储到一个String数组中返回
(3)把当前文件夹下的所有子文件和子文件夹都使用一个File对象描述,然后把File对象存储到File数组中

(4)
list(FilenameFilter filter);
(5)自定义文件名过滤器
listFiles(FilenameFilter filter);
输入输出划分:
--------输入流:相对本程序
--------输出流
处理单位划分:
--------字节流:读取文件中二进制数据,不会结果任何处理(FileInputStream )
--------字符流:以字符为单位,读取文件中二进制数据,将其转换为我们能识别的字符,字符流 = 字节流+解码,(FileReader )
二、字节流
1、输入字节流:
---------------| InputStream 所有输入字节流的基类
--------------------| FileInputStream:读取文件数据的输入字节流
FileInputStream读取文件的步骤
1、找到目标文件
2、建立数据的输入通道(管道)
3、建立缓冲数组,读取文件数据
4、关闭资源(释放资源)
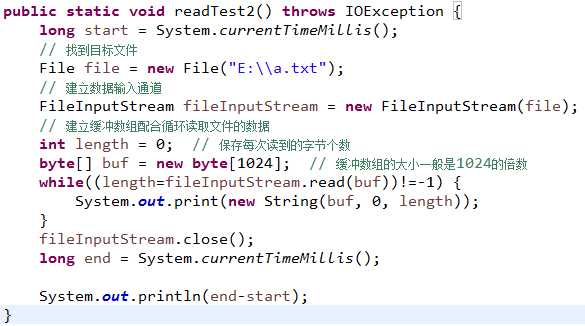
注意:用缓冲数组读取效率更高
要是缓冲数组只有4时,每次读完数据第二次是覆盖到前面的数组
2、输出字节流
-----------| OutputStream 所有输出字节流的基类
---------------| FileInputStream 向文件输出数据的字节流
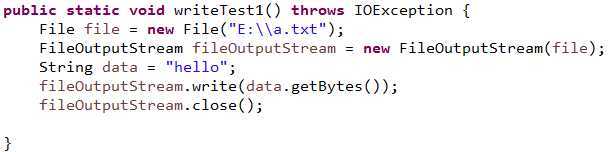
1、使用FileInputStream的时候,如果目标文件不存在,会自动创建目标文件对象
2、写数据的时候,目标文件存在会先清空目标文件的数据,再写入数据
3、已经存在,需要在原来的后面追加数据,应该使用FileOutputStream(file, true);
4、write方法写数据的时候,虽然接收的是int型的数据,但是真正写出的只是一个字节(8位)的数据,把低八位二级制数据写出,其他二十四位数据全部丢弃
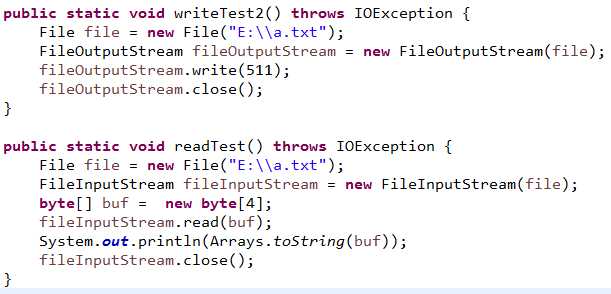
输出[-1, 0, 0, 0];255(11111111)以补码形式存在
拷贝图片
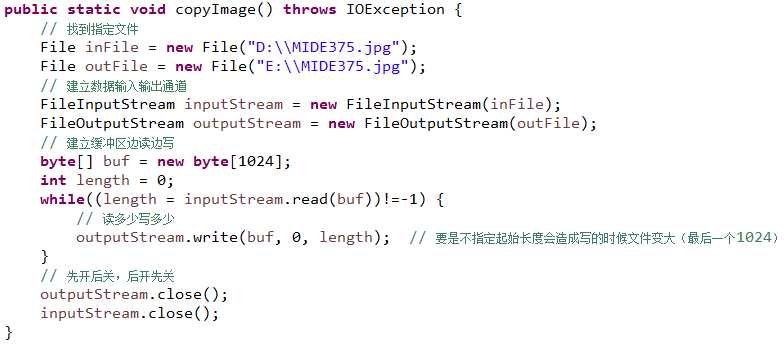
注意:每新创建一个FileOutputStream的时候,默认情况下FileOutputStream的指针指向文件开始位置,每写出一次指向都会相应移动(写的时候加不加true问题)
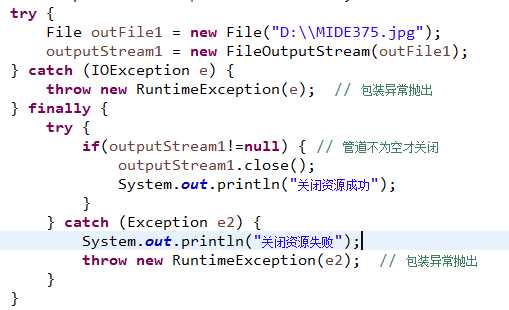
3、异常处理

将IOException传递给RuntimeException包装一层,然后再抛出,让调用者使用更加灵活,可以处理也可以不处理
将异常throw的时候,阻止后面代码执行(要是return的话,能阻止代码执行,但是不会通知外界出了问题)
4、缓冲输入字节流BufferedInputStream(其实跟自定义内存数组byte[] buf的原理一样,不常用 )
代替自定义的缓冲数组buf
-------------| InputStream
---------------------| FileInputStream
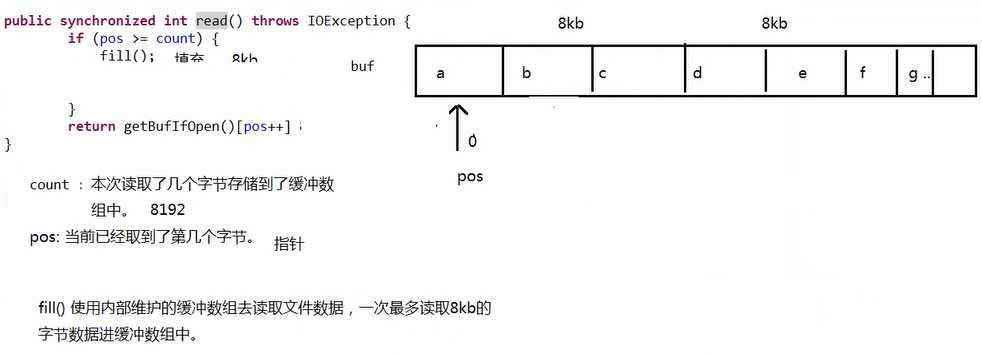
---------------------| BufferedInputStream 缓冲输入字节流,提高读取文件数据效率,内部维护了一个8K 的字节数组,效果和自定义缓冲数组一样
使用步骤
1、找到目标文件
2、建立数据输入通道
3、建立缓冲输入字节流
4、关闭资源
缓冲流都不具备读写的能力,BufferedInputStream借助FileInputStream实现读写; 调用BufferedInputStream的close方法实际关闭FileInputStream
BufferedInputStream读取效率高的原因:每次从内存中BufferedInputStream维护的数组读取8K的数据(FileInputStream 则是从硬盘中读取)
5、缓冲输出字节流BufferedOutputStream
内部维护了一个8K的缓冲字节数组
注意:
1、写数据时,write是写到在内部维护的字节数组中
2、要想写到硬盘中,需要调用flush或者close方法或者内部字节数组已经填满的时候
用缓冲输入输出流拷贝图片
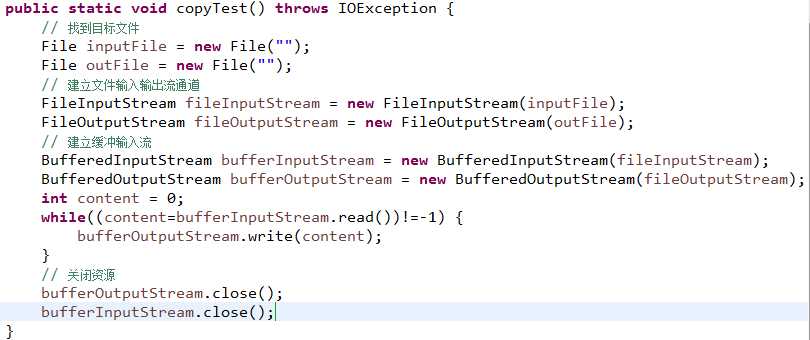
bufferedInputStream.read()方法中,要是传入了buf缓冲数组返回值是存储到缓冲数组字节个数;要是没有传入,则返回的是读取到的内容
三、字符流
字符流 = 字节流+解码(字节流读取文件中二进制数据,一次读取一个字节),可以读取中英文,一次读取一个字符
ASCII码表:一个字节7位(256)表示,26个英文字母对应各自码值,很多空出,2(8)
ISO8859-1:填上了ASCII的空位
GBK2312:英文1个字节,中文2字节,GBK升级版,2(16)=65536
Unicode:
UTF-8:世界通用,英文1个字节,中文3个字节
输入字符流(默认使用GBK编码表)
---------------| Reader 输入字符流的基类
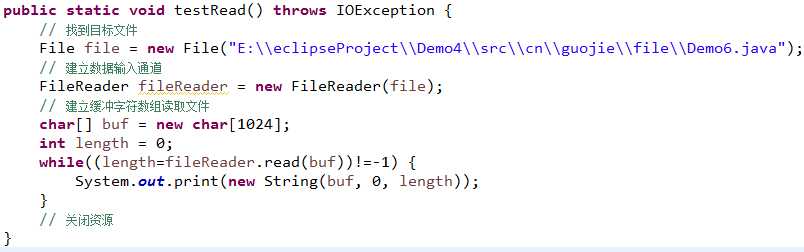
---------------------| FileReader 读取文件的输入字符流,每次读一个字符(char),不论中英文都可以读(byte字节,char字符)
1、FileWriter输出字符流
写数据的时候,FileWriter内部维护了1024字节的数组,写数据的时候会先写到数组中,要写到硬盘上时,需要调用flush或者是close方法或者是填满内部字符数组

使用字符流拷贝图片时,会造成图片变小且打不开
FileReader默认使用GBK编码表,每次读取数据时会在码表里面找,找得到就存储中文两位(将二进制数据转换为字符),找不到就返回一个未知字符对应的数字,未知字符占一个字节,导致有些数据丢失
字符流的应用场景
如果是读写字符数据的时候就是用字符流(看得到的1、我......)
字节流的应用场景
读写的数据不需要转换为字符的时候使用
用字节流配合缓冲数组读取字符的时候,要是缓冲数组比较小(byte[4]),而字符为中英文混合(我de妈呀),会造成读取乱码;用字符流就每次读取一个字符,不会出错
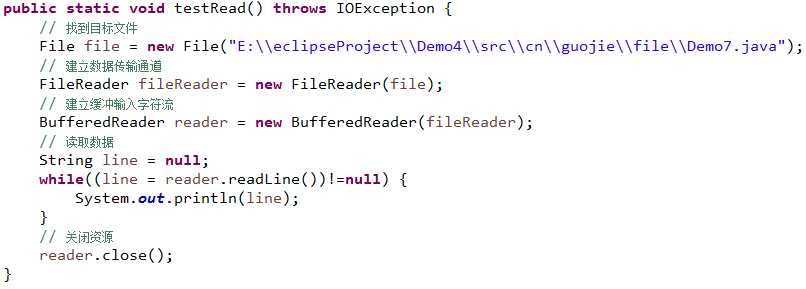
2、输出字符缓冲流(常用,比缓冲数组好,常用)BufferedReader
----------------| Reader 所有输入字符流的基类,抽象
----------------------| FileReader 输入字符流
----------------------| BufferedReader 字符缓冲输入流,提高文件读取效率和扩展了FileReader的功能,其内部维护了一个4K的数组(缓冲流都不具备读写文件的能力,每次读取的是一个字符)
readline()方法可以读取一行,文件末尾返回null,读取的一行不包含/r/n(以/r/n 为结束符)
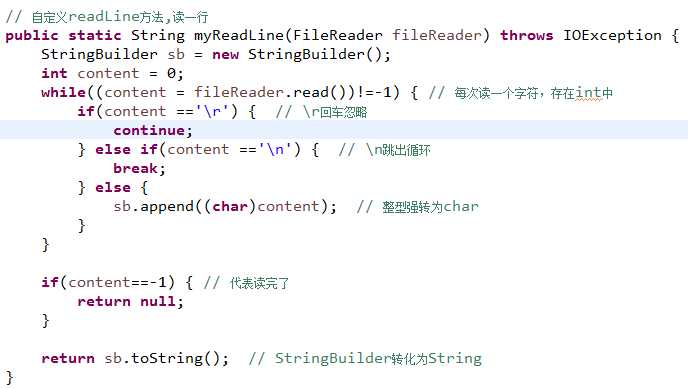
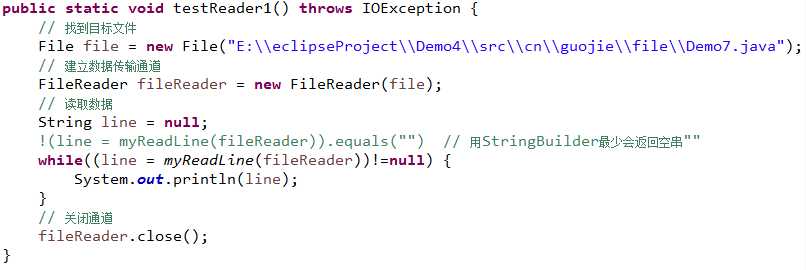
自定义BufferedReader的readLine方法
3、缓冲输出字符流(提高FileWriter的读写效率和扩展功能)(常用)
----------------| Writer 所有输入字符流的基类,抽象
----------------------| FileWriter 输入字符流
----------------------| BufferedWriter:内部提供了8K的字符数组作为缓冲区
提供了newLine()方法,换行

四、装饰者设计模式
增强一个类的功能,还可以让这些类互相装饰
通过继承增强一个类的功能:
优点:代码结构清晰易懂
缺点:使用不灵活,会导致继承的体系过于庞大
步骤:
1、在装饰类内部维护一个被装饰类的引用
2、让装饰类有共同的父类或者父接口
父类有无参的构造方法时默认调用,要是没有无参的构造方法则需要指定有参构造方法
修饰模式实战增强类:
优点:内部可以通过多态对多个需要增强的类进行增强,让这些修饰类达到互相装饰的效果,使用灵活
缺点:需要内部通过多态维护需要被增强类的实力,使代码复杂

