标签:nod failed enabled 数据库 package 数据 logstash sha jdk
节点可以通过指定集群名字来加入到集群中。默认情况下,每个节点被设置成加入到elasticsearch集群。如果启动了多个节点,假设能自动发现对方,他们将会自动组建一个名为 elasticsearch的集群。
E: elasticsearch
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。
也就是将logstach收集上来的日志储存,建立索引(便于查找),搜索(提供web展示)
l:logstash
收集日志
数据源:各种log,文本,session,silk,snmp
k:kibana
数据展示,web页面,可视化
可以完成批量分析
数据集之间关联
产生图表
报警 (python / R 语言 )
ES python api的文档
1、下载tar包直接解压(灵活)
2、配置yum源直接安装(方便)
服务器部署:
logstatsh : 部署在想收集日志的服务器上。
elasticsearch:主要是用于数据收集,索引,搜索提供展示,随意安装在那台服务器上都可以,重要的是es支持分布式,而且再大规模的日志分析中必须做分布式集群。这样可以跨节点索引和搜索。提高吞吐量与计算能力。
kibana:数据展示,部署在任意服务器上。
这里我们做实验使用的是两台服务器
node1.wawa.com : 192.168.31.179 node2.wawa.com : 192.168.31.205
a、准备环境:
配置hosts两台服务器网络通畅
node1 安装es,node2安装es 做成集群,后期可能还会用到redis,redis提供的功能相当于kafka,收集logstatsh发来的数据,es从redis中提取数据。
node1 安装kibana 做数据展示
node2 安装logstatsh 做数据收集
创建 elasticsearch 用户
b、安装:
由于es logstatsh kibana基于java 开发,所以安装jdk ,jdk版本不要过低,否则会提醒升级jdk。
安装elasticsearch(node1,node2全都安装es)
下载并安装GPG key
[root@linux-node1 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
添加yum仓库
[root@linux-node2 ~]# vim /etc/yum.repos.d/elasticsearch.repo [elasticsearch-2.x] name=Elasticsearch repository for 2.x packages baseurl=http://packages.elastic.co/elasticsearch/2.x/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1
安装elasticsearch
[root@hadoop-node2 ~]# yum install -y elasticsearch
安装kibana(这里使用的tar包安装,es、log tar包方法一样)
[root@linux-node2 ~]#cd /usr/local/src [root@linux-node2 ~]#wget https://download.elastic.co/kibana/kibana/kibana-4.3.1-linux-x64.tar.gz tar zxf kibana-4.3.1-linux-x64.tar.gz [root@linux-node1 src]# mv kibana-4.3.1-linux-x64 /usr/local/ [root@linux-node2 src]# ln -s /usr/local/kibana-4.3.1-linux-x64/ /usr/local/kibana
安装logstatsh (node2安装)
下载并安装GPG key
[root@linux-node2 ~]# rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
添加yum仓库
[root@linux-node2 ~]# vim /etc/yum.repos.d/logstash.repo [logstash-2.1] name=Logstash repository for 2.1.x packages baseurl=http://packages.elastic.co/logstash/2.1/centos gpgcheck=1 gpgkey=http://packages.elastic.co/GPG-KEY-elasticsearch enabled=1
安装logstash
[root@linux-node2 ~]# yum install -y logstash
c、配置管理elasticsearch
[root@linux-node1 src]# grep -n ‘^[a-Z]‘ /etc/elasticsearch/elasticsearch.yml 17:cluster.name: chuck-cluster 判别节点是否是统一集群,多台统一集群的es名称要一致 23:node.name: linux-node1 节点的hostname 33:path.data: /data/es-data 数据存放路径 37:path.logs: /var/log/elasticsearch/ 日志路径 43:bootstrap.mlockall: true 锁住内存,使内存不会再swap中使用 54:network.host: 0.0.0.0 允许访问的ip 58:http.port: 9200 端口 [root@linux-node1 ~]# mkdir -p /data/es-data [root@linux-node1 src]# chown elasticsearch.elasticsearch /data/es-data/
d、启动 elasticsearch
[root@node2 ~]# /etc/init.d/elasticsearch status elasticsearch (pid 23485) 正在运行... You have new mail in /var/spool/mail/root [root@node2 ~]# ps aux| grep elasticsearch 505 23485 2.1 53.1 2561964 264616 ? Sl 17:09 6:07 /usr/bin/java -Xms256m -Xmx1g -Djava.awt.headless=true -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError -XX:+DisableExplicitGC -Dfile.encoding=UTF-8 -Djna.nosys=true -Des.path.home=/usr/share/elasticsearch -cp /usr/share/elasticsearch/lib/elasticsearch-2.4.2.jar:/usr/share/elasticsearch/lib/* org.elasticsearch.bootstrap.Elasticsearch start -p /var/run/elasticsearch/elasticsearch.pid -d -Des.default.path.home=/usr/share/elasticsearch -Des.default.path.logs=/var/log/elasticsearch -Des.default.path.data=/var/lib/elasticsearch -Des.default.path.conf=/etc/elasticsearch root 26425 0.0 0.1 103260 844 pts/0 S+ 21:57 0:00 grep elasticsearch [root@node2 ~]# ss -tunlp | grep elasticsearch [root@node2 ~]# ss -tunlp | grep 23485 tcp LISTEN 0 50 :::9200 :::* users:(("java",23485,132)) tcp LISTEN 0 50 :::9300 :::* users:(("java",23485,89))
e、测试
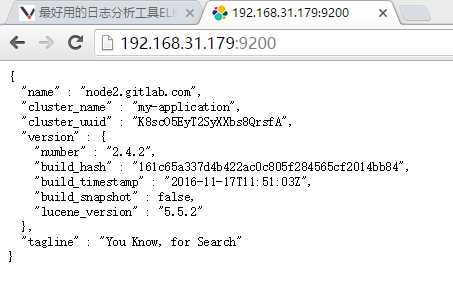
交互方式:
1、我们使用RESTful web接口
[root@linux-node1 src]# curl -i -XGET ‘http://192.168.56.11:9200/_count?pretty‘ -d ‘{
"query" { #查询
"match_all": {} #所有信息
}
}‘
HTTP/1.1 200 OK
Content-Type: application/json; charset=UTF-8
Content-Length: 95
{
"count" : 0, 索引0个
"_shards" : { 分区0个
"total" : 0,
"successful" : 0, 成功0个
"failed" : 0 失败0个
}
}
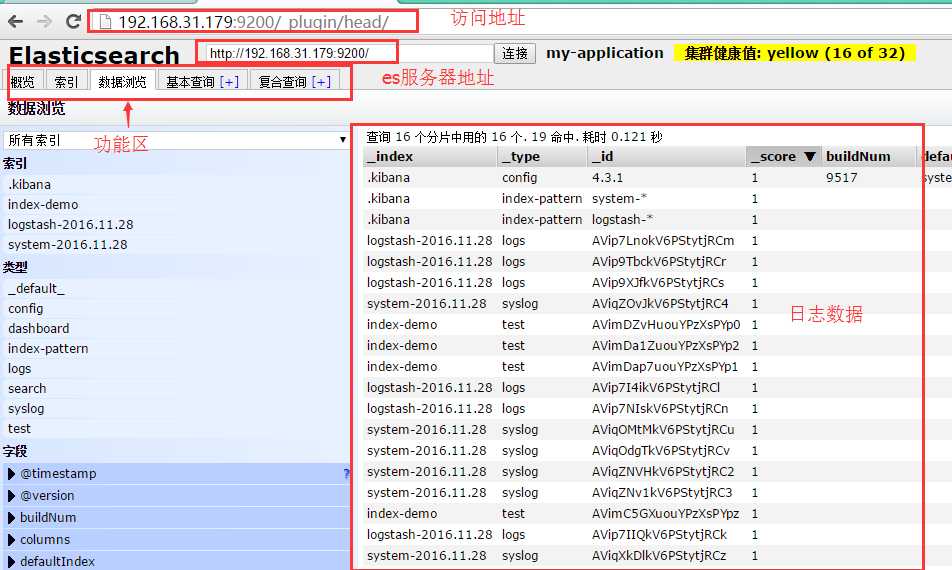
2、使用es 强大的插件 : head插件显示索引和分片情况
f、安装插件
[root@linux-node1 src]# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head [root@linux-node1 src]# /usr/share/elasticsearch/bin/plugin list 可以查看当前已经安装的插件

访问刚刚安装的head插件
http://192.168.31.179:9200/_plugin/head/
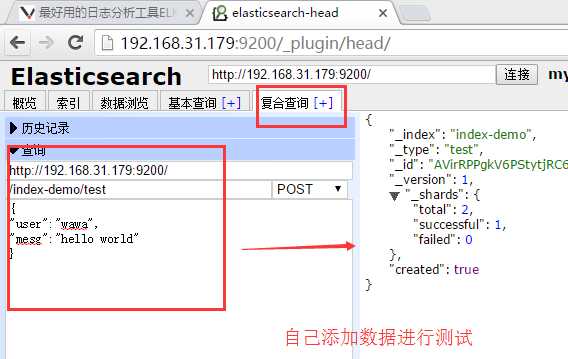
添加数据测试
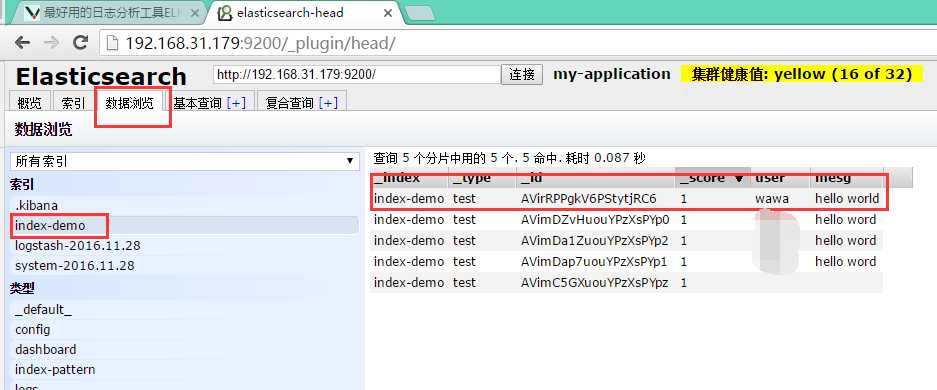
node2安装好以后配置集群模式
[root@node1 src]# scp /etc/elasticsearch/elasticsearch.yml 192.168.56.12:/etc/elasticsearch/elasticsearch.yml [root@node2 elasticsearch]# sed -i ‘23s#node.name: linux-node1#node.name: linux-node2#g‘ elasticsearch.yml [root@node2 elasticsearch]# mkdir -p /data/es-data [root@node2 elasticsearch]# chown elasticsearch.elasticsearch /data/es-data/
node1与node2中都配置上(单播模式,听说还有组播默认,可以尝试一下)
[root@linux-node1 ~]# grep -n "^discovery" /etc/elasticsearch/elasticsearch.yml 79:discovery.zen.ping.unicast.hosts: ["linux-node1", "linux-node2"] [root@linux-node1 ~]# systemctl restart elasticsearch.service
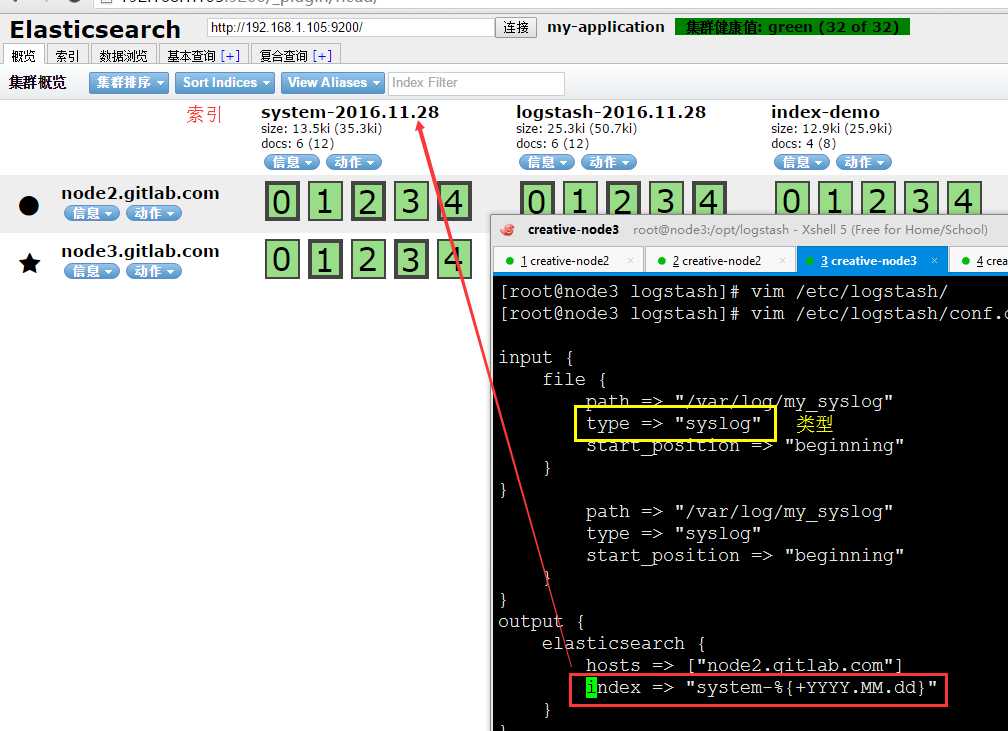
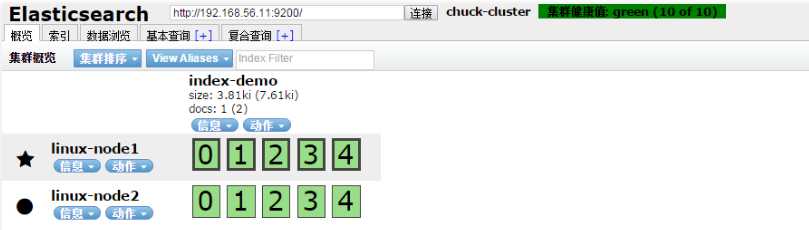
在浏览器中查看分片信息,一个索引默认被分成了5个分片,每份数据被分成了五个分片(可以调节分片数量),下图中外围带绿色框的为主分片,不带框的为副本分片,主分片丢失,副本分片会复制一份成为主分片,起到了高可用的作用,主副分片也可以使用负载均衡加快查询速度,但是如果主副本分片都丢失,则索引就是彻底丢失。
标签:nod failed enabled 数据库 package 数据 logstash sha jdk
原文地址:http://www.cnblogs.com/python-way/p/6110736.html