标签:内存泄露 src tin img 定义 成功 逻辑 lex exec
本章例程
//12.3 #include <stdio.h> #include <stdlib.h> typedef struct NODE{ struct NODE *link; int value; }Node; #define FALSE 0 #define TRUE 1 int sll_insert(register Node **linkp, int new_value) { register Node *current; register Node *new; while((current = *linkp) != NULL && current->value < new_value) linkp = ¤t->link; new = (Node *)malloc(sizeof(Node)); if(new == NULL) return FALSE; new->value = new_value; new->link = current; *linkp = new; return TRUE; } //12.7 int dll_insert(register Node *rootp, int value) { register Node *this; register Node *next; register Node *newnode; for(this = rootp; (next = this->fwd) != NULL; this = next){ if(next->value == value) return 0; if(next->value > value) break; } newnode = (Node *)malloc(sizeof(Node)); if(newnode == NULL) return -1; newnode->value = value; newnode->fwd = next; this->fwd = newnode; if(this != rootp) newnode->bwd = this; else newnode->bwd = NULL; if(next != NULL) next->bwd = newnode; else rootp->bwd = newnode; return 1; }
本章问题
1.程序12.3是否能进行改写,不使用current变量?如果可以,把你的答案和原先的函数作一比较。
answer:
int sll_insert(register Node **linkp, int new_value) { register Node *new; while(*link != NULL && (*linkp)->value < new_value) linkp = &(*linkp)->link; new = (Node *)malloc(sizeof(Node)); if(new == NULL) return 0; new->value = new_value; new->link = *linkp; *linkp = new; return 1; }
This version of the program uses one fewer variable,but it has three extra indirections so it will take slightly(稍微) longer to execute,It is also harder to understand,which is its major drawback.
(这个程序的版本使用了更少的变量,不过它增加了三个额外的间接访问,所以它执行的时候要更长一些,它最大的缺点就是它的可读性更差)
2.有些数据结构课本建议在单链表中使用“头节点”,这个哑节点始终是链表的第一个元素,这就消除了插入到链表起始位置这个特殊状况,讨论这个技巧的利与弊。
answer:

(和不用处理任何特殊情况代码的sll_insert函数相比,这种使用头节点的技巧没有任何优越之处,而且自相矛盾的是,这个声称用于消除特殊情况的技巧实际将引入用于处理特殊情况的代码,当链表被创建时,必须添加哑节点,其他操纵这个链表的函数必须跳过这个哑节点,最后,这个哑节点还会浪费空间)
3.在程序12.3中,插入函数会把重复的值插入到什么位置?如果把比较操作符由<改为<=会有什么效果?
answer:Ahead of other nodes with the same value,if the comparison were changed,duplicate values would be inserted after other nodes with the same value.
(相同节点之前,如果条件发生改变,重复的值则插入在相同的值之后)
4.讨论一些技巧,怎样省略双链表中根节点的值字段?
answer:


如果根节点是动态分配内存的,我们可以通过只为节点的一部分分配内存来达到目的。
一种更安全的声明一个只包含指针的结构。根指针就是这类结构之一,每个节点只包含这类结构中的一个,这种方法的有趣之处在于结构之间的相互依赖,每个结构都包含了一个对方类型的字段。这种相互依赖性就在声明它们时产生了一个“先有鸡还是先有蛋”的问题:哪个结构先声明呢?这个问题只是通过其中一个结构标签的不完整声明来解决。
5.如果程序12.7中对malloc的调用在函数的起始部分执行会有什么结果?
answer: Each attempt to add a duplicate(重复的) value to the list would result in a memory leak:A new node would be allocated,but not add to the list.
(每尝试添加一个重复的值都会使内存泄露,一个新的节点被分配,但是没有添加到链表中)
6.能不能对一个无序的单链表进行排序?
answer:Yes,but it is very inefficient .the simplest strategy(策略) is to take the nodes off the list one by one and insert them into a new,ordered list.
(可以,不过相当低效,最简单的策略是把它们一个一个插入一个已经排好序的链表之中)
7.索引表是一种字母链表,表中的节点是出现于一本书或一篇文章中的单词,你可以使用一个有序的字符串单链表实现索引表,使用插入函数时不插入重复的单词,和这种实现方法有关的问题是搜索链表的时间将随着链表规模的扩大而急剧增长。
图12.1说明了另一种存储索引表的数据结构,它的思路是把一个大型的链表分解成26个小型链表--每个链表中的所有单词都以同一个字母开头,最初链表中的每个节点包含了一个字母和一个指向有序的以该字母开头的单词的单链表(以字符串的形式存储)的指针。
使用这种数据结构,搜索一个特定的单词所花费的时间与使用一个存储所有单词的单链表相比,有没有什么变化?
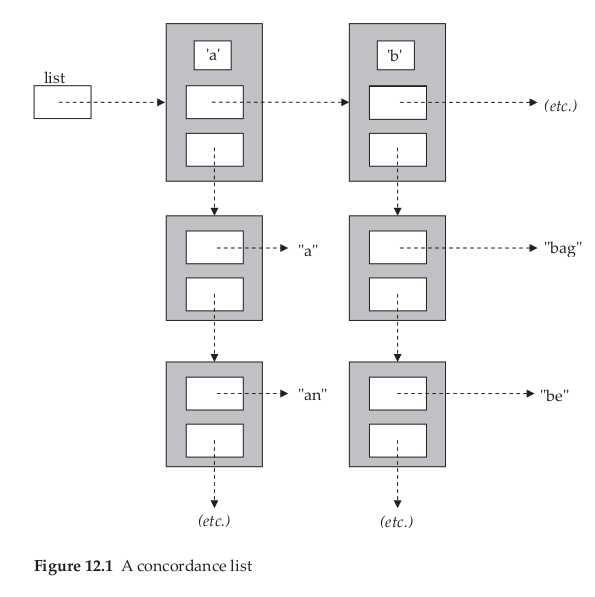
answer:

在多个链表的方案中进行查找比在一个包含所有单词的链表中查找效率要高得多,例如,查找一个以字母b开头的单词,我们就不需要在那些以a开头的子母中进行查找,在26个字母中,如果每个字母开头的单词出现的频率相同,这种多个链表方案的效率几乎可以提高26倍,不过实际改进的幅度要比这小一些。
本章练习
1.编写一个函数,用于计数一个单链表的节点个数,它的唯一参数是一个指向链表第一个节点的指针,编写这个函数时,你必须知道哪些信息?这个函数还能用于执行其他任务吗?
answer:
//自己的答案
int countnode(type *p) { int count = 0; while(p != NULL){ count++; p = p->link; } return count; }
这个函数很简单,虽然它只能用于它被声明的那种类型的节点--你必须知道节点的内部结构,下一张将讨论解决这个问题的技巧。
如果这个函数被调用时传递给它的指针是一个指向链表中间位置某个节点的指针,那么它将对链表中这个节点以后的节点进行计数。
2.编写一个函数,在一个无序的单链表中寻找一个特定的值,并返回一个指向该节点的指针。你可以假设节点数据结构在头文件singly_linked_list_node.h中定义。如果想让这个函数适用于有序的单链表,需不需要对它做些修改?
answer:
#include <stdio.h> #include <singly_linked_list_node.h> Node *search(Node *head, type value) { Node *p = head; while(p != NULL){ if(p->data == value) break; p = p->link; } return p; }
Technically,no change is required to search an ordered list,though the function can be made more efficient with a minor change,if nodes are found whose value are greater than the desired value,there is no need to continue searching,this is implemented by changing the test in the for loop to
p != NULL && p->data <= value
(从技术上说,在一个有序链表中查找是不需要作什么改变的,不过如果稍微做一点改变将会更高效,如果节点找到一个值比期望的值还要大,就不需要继续查找了,可以把循环语句中的测试部分改为...)
3.重新编写程序12.7的dll_list函数,使头和尾指针分别以一个单独的指针传递给函数,而不是作为一个节点的一部分,从函数的逻辑而言,这个改动有何效果?
answer:
//使用头尾指针指向第一个和最后一个节点,指针类型为Node *,链表为空时,两个指针都指向空
#include <stdio.h> #include <stdlib.h> #include "double_linked_list_node.h" int dll_insert(Node *head, Node *rear, int value) { register Node *this; register Node *next; register Node *new; if(head != NULL){ for(this = head; (next = this->fwd) != NULL; this = next){ if(value == next->value) return 0; if(next->value > value) break; } }else{ this = next = NULL; } new = (Node *)malloc(sizeof(Node)); if(new == NULL) return -1; new->value = value; if(this == head) head = new; else this->fwd = new; if(head == NULL || next == NULL) rear = new; else next->bwd = new; new->fwd = next; new->bwd = this; return 0; }
this makes the function more complex,primarily because the root pointers can no longer be manipulated in the same way as the node pointers.
(使得函数更加复杂,根指针不再以节点指针的方式进行操作)
//标准答案,头尾指针分别为指向第一个元素fwd和最后一个元素的bwd int dll_insert(Node **frontp, Node **rearp, int value) { register Node **fwdp; register Node *next; register Node *newnode; fwdp = frontp; while((next = *fwdp) != NULL){ if(next->value == value) return 0; if(next->value > value) break; fwdp = &next->fwd; } newnode = (Node *)malloc(sizeof(Node)); if(newnode == NULL) return -1; newnode->value = value; newnode->fwd = next; *fwdp = nexnode; if(fwdp != frontp) if(next != NULL) newnode->bwd = next->bwd; else newnode->bwd = *rearp; else newnode->bwd = NULL; if(next != NULL) next->bwd = newnode; else *rearp = newnode; return 1; }
4.编写一个函数,反序排列一个单链表中所有的节点。函数应该具有下面的原型:
struct NODE *sll_reverse(struct NODE *first);
在头文件singly_linked_list_node.h中声明节点数据结构。函数的参数指向链表的第一个节点。当链表被重排之后,函数返回一个指向链表新头节点的指针,链表最后一个节点的link字段的值应设置为NULL,在空链表(first = = NULL)上执行这个函数将返回NULL。
answer:
//方法一 #include <stdio.h> #include <stdlib.h> #include <singly_linked_list_node.h> struct NODE *sll_reverse(struct NODE *first) { Node *newfirst; Node *p = first; Node *q = first; if(first == NULL) return NULL; //让p指向最后一个元素,q指向倒数第二个 while(p->link != NULL){ q = p; p = p->link; } newfirst = p; //箭头反转 while(q != first){ p->link = q; p = q; } q->link = NULL; return newfirst; }
//方法二 #include <stdio.h> #include <stdlib.h> #include <singly_linked_list_node.h> //直接进行反转 struct NODE *sll_reverse(struct NODE *first) { Node *current; Node *next; if(first != NULL){ for(current = NULL; first != NULL; first = next){ next = first->link; first->link = current; current = first; } } return first; }
5.编写一个程序,从一个单链表中移除一个节点,函数的原型如下:
int sll_remove(struct NODE **rootp, struct NODE *node);
你可以假设节点数据结构在头文件singly_linked_list_node.h中定义,函数的第一个参数是一个指向链表根指针的指针,第二个参数是一个指向欲移除的节点的指针,如果链表并不包含该指针,函数就返回假,否则它就移除这个节点并返回真,把一个欲移除的节点的指针而不是欲移除的值作为参数传递给函数有哪些优点?
answer:
首先,接受一个指向我们希望删除的节点的指针可以使函数和存储在链表中的类型无关,相同的代码可以作用于不同类型的值,另一方面,如果我们并不知道哪个节点包含了需要被删除的值,我们首先必须对它进行查找。
#include <stdio.h> #include <stdlib.h> #include <singly_linked_list_node.h> int sll_remove(struct NODE **rootp, struct NODE *node) { Node *p; assert(node != NULL); while((p = *rootp) != NULL){ if(p == node){ *rootp = p->link; free(node); return 1; } rootp = &p->link; } return 0; }
注意让这个函数用free函数删除节点会限制它只能适用动态分配节点的链表,另一种方案是如果函数返回真,由调用函数负责删除节点,当然如果调用程序没有删除动态分配的节点,将导致内存泄露。
6.编写一个程序,从双链表中移除一个节点,函数的原型如下
int dll_remove(struct NODE *rootp, struct NODE *node);
你可以假设节点数据结构在头文件double_linked_list_node.h文件中定义,函数第一个参数是一个指向包含链表根指针的节点的指针(和程序12.7相同),第二个参数是个指向欲移除的节点的指针,如果链表并不包含欲移除的指针,函数就返回假,否则函数移除该节点并返回真。
answer:
#include <stdio.h> #include <assert.h> #include <stdlib.h> #include <doubly_linked_list_node.h> int dll_remove(struct NODE *rootp, struct NODE *node) { Node *p; assert(node != NULL); while((p = rootp->fwd) != NULL){ if(p == node){ if(p->bwd == NULL) rootp->fwd = p->fwd; else p->fwd->bwd = p->bwd; if(p->fwd != NULL) p->fwd->bwd = rootp; else rootp->bwd = p->bwd; free(node); return 1; } rootp = p; } return 0; }
7.编写一个函数,把一个新单词插入到问题7所描述的索引表中。函数接受两个参数,一个指向list指针的指针和一个字符串,该字符串假定包含单个单词,如果这个单词原先并未存在索引表中,它应该复制一块动态分配的节点并插入到这个索引表中,如果成功插入返回真,如果该字符原先已经存在于索引表中,或字符串不是以字符开头或其他错误返回假。函数应该维护一个一级链表,节点的排序以字母为序,其余的二级链表则以单词为序排列。
answer:
//对这个链表比较感兴趣,所以把创建链表以及插入的整个过程都写下来 #include <stdio.h> #include <stdlib.h> #include <string.h> struct FIRSTNODE; //单词结构 typedef struct SECONDNODE{ char *string; struct SECONDNODE *next; }SecondNode; //字母索引结构 typedef struct FIRSTNODE{ char ch; struct FIRSTNODE *alpha; struct SECONDNODE *word; }FirstNode; char delta[] = "abcdefghijklmnopqrstuvwxyz"; //在字母索引结构的尾部插入新的结构 FirstNode* insert_end(FirstNode *list, char ch) { FirstNode *newnode = (FirstNode *)malloc(sizeof(FirstNode)); if(newnode == NULL) return NULL; newnode->ch = ch; newnode->alpha = NULL; newnode->word = NULL; if(list == NULL) list = newnode; else{ FirstNode *p; p = list; while(p->alpha != NULL) p = p->alpha; p->alpha = newnode; } return list; } //创建一个新的索引链表 FirstNode* createlist() { int i; int len = strlen(delta); FirstNode *list = NULL; for(i = 0; i < len; i++) list = insert_end(list,delta[i]); return list; } //打印索引链表 void PrintNode(FirstNode *list) { FirstNode *p = list; while(p->alpha != NULL){ printf("%c\n",p->ch); if(p->word != NULL){ SecondNode *q = p->word; while(q != NULL){ printf("->%s\n",q->string); q = q->next; } } printf("--------\n"); p = p->alpha; } } //插入新的单词 int insert_word(FirstNode **listp, char *str) { char c = *str; FirstNode *p = *listp; if(listp == NULL || str == NULL) return 0; while(p != NULL){ if(p->ch == c) break; p = p->alpha; } if(p == NULL) return 0; SecondNode *q = p->word; SecondNode *s = NULL; while(q != NULL){ if(strcmp(q->string,str) == 0) return 0; if(strcmp(q->string,str) > 0) break; s = q; q = q->next; } SecondNode *newnode = (SecondNode *)malloc(sizeof(SecondNode)); if(newnode == NULL) return 0;
newnode->string = str;
//strcpy(newnode->string,str); error newnode->next = q; if(s == NULL) p->word = newnode; else s->next = newnode; return 1; } int main() { FirstNode *list = createlist(); insert_word(&list,"b2"); insert_word(&list,"b4"); insert_word(&list,"b1"); insert_word(&list,"b3"); PrintNode(list); free(list); return 0; }
运行结果:
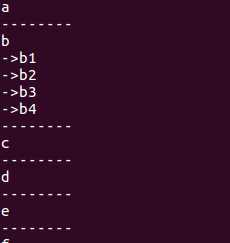
...
上面的代码是用指向节点的指针来完成,要考虑特殊情况,而下面标准答案里的实现则是用指向结构指针的指针来完成,不需要考虑特殊情况。



标签:内存泄露 src tin img 定义 成功 逻辑 lex exec
原文地址:http://www.cnblogs.com/monster-prince/p/6108142.html