标签:src vc维 分类器 com 理论 enter 它的 实现 分类
一、定义:
有n个训练样本Zn={zi(xi,yi), i=1,2,...,n},定义N(Zn)为函数集中的函数能对样本分类的数目。
解释:xi 代表特征向量如d维特征向量,yi代表一个标记如0或1, 因此zi就是对一个特征的标记,Zn中有n个样本,可能的标记方式2n种,一种标记方式就生成一种样本集;
N(Zn)为Zn的标记空间中能被正确分类的标记数量。
举例:在二维特征空间中,不共线的3个二维特征向量,其标记方式有23=8种,每一种标记方式都能被指示函数集二维线性分类器正确分类,因此这3个特征组成的集合的N(Z3)=8,如图1所示;但是共线的3个二维特征向量,其标记方式也有23=8种,但只有两种方式能够被指示函数集二维线性分类器正确分类,因此这3个特征组成的集合的N(Z3)=2,如图2所示。
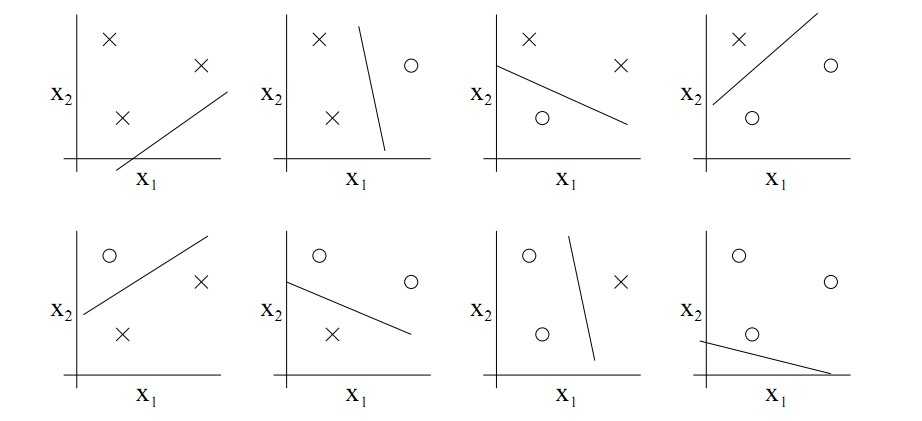
图1:不共线的3个二维特征的8种标记都能够被二维线性分类器分类
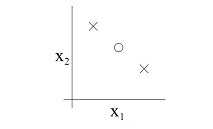
图2:共线的3个二维特征的8种标记中有6种标记不能被二维线性分类器分类
1、随机熵:指示函数集能够实现分类组合数的自然对数,称为函数集在样本上的随机熵,表示为H(Zn)=lnN(Zn)。
显然对于二维线性分类器,图1中的三个特征样本集的随机熵H(Z3)=lnN(Z3)=ln23=3ln2;图2中的三个特征样本集的随机熵为H(Z3)=lnN(Z3)=ln2=ln2;
2、VC熵:n个样本的随机熵的期望值H(n)=E(lnN(Zn))。
显然对于二维线性分类器,三个特征样本集的VC熵为H(3)=1/2 x 3ln2 + 1/2 x ln2 =2ln2;
3、退火的VC熵:Hann(n)=ln E(N(Zn))。
显然对于二维线性分类器,三个特征样本集的VC熵为Hann(3)=ln(1/2 x 8 + 1/2 x 2) =ln5;
4、生长函数:函数集的最大随机熵,G(n)=ln maxZnN(Zn)。
显然对于二维线性分类器,三个特征样本集的生长函数为G(3)=3ln2;
5、打散:在由n个特征组成的集合中(这种集合无限多),只要存在一种集合,它的所有2n种记方式都能够被标记函数集分类,那么就称n个特征构成的样本集能够被该标记函数集打散。
显然3个二维特征构成的样本集能够被二维线性分类器打散,因为3个二维特征存在一种不共线的情况,它的8终标记方式能够被二维线性分类器正确分类。
6、VC维:指示函数集能打散的最大样本数。
显示对于二维线性分类器,3个特征的样本集是能够被打散的,但是4个特征的样本集不能够被打散,因为4个特征构成的所有特征集中,任何一个特征集都不存在24=16种标记方式能被正确分类,即对于所有的N(Z4)< 16。因此二维线性分类器的VC维是3。
二、性质
1、三者之间关系:H(n) <= Hann(n)<= G(n)<=nln2;(证明忽略,以二维线性分类器为例理解)
2、标记函数集的生长函数或者与样本数成正比,即G(n)=nln2,或者以样本数的某个对数函数维上界,即G(n)<=h*(ln(n/h) + 1), n>h,h是VC维。(证明忽略,以二维线性分类器为例理解)
3、d维空间中的N个样本线性可分的数目,即N(Zn)=D(n,d)=2n,当 n<=d 时;N(Zn)=D(n,d)=2n2(sigma{C(n-1,i)},i=0,...,d),当n>d时。sigma以为是从i=0到i=d对组合数C(n-1,i)累加。
4、从性质2中,可以看出随着样本数目增加,生长函数G(n)不是线性增加的。
统计机器学习理论:随机熵、vc熵、退火VC熵、生长函数、VC维定义理解
标签:src vc维 分类器 com 理论 enter 它的 实现 分类
原文地址:http://www.cnblogs.com/xiehbpku/p/6114799.html