标签:自己 ima 资源 合并 初创公司 增删改 紧急 中断 背景
2016sdcc中国开发者大会参后感
sdcc大会可以理解是中国整个IT行业技术大牛的一个分享会,有幸参加此会,首先要感谢我的好兄弟阿辉,他给我推荐此大会赠我入场券并且督促我参与,真的非常感谢。
sdcc分享会是由csdn从2007年开始每年举办的一次技术嘉年华,邀请行业内近百名技术大牛倾力分享所在公司运用的前沿IT技术,其中大多来自阿里巴巴、京东、腾讯、百度等高科技互
联网公司,其中还一些初创公司的ceo的创业经历的分享。
其实我知道这次去肯定要被虐惨,毕竟我还是知道自己属于哪个层次,但是不管怎么样,既然有机会参与这次分享会,我还是十分乐意去长长见识。
大会总共三天,有四个会场同时进行,分享内容以专题做区分:包含电商架构专题、架构师进阶之路专题、前端开发专题、自动化运维与容器实践专题、高吞吐数据库架构专题、微信开发、
高可用架构、架构演进、移动视频技术实践专题等,我也根据自己的个人感兴趣的内容选择会场参与其中,这篇文章我主要是想给大家分享以下三位老师的演讲的题目(其余老师的内容规格太高,还没完全听懂,正在研究中...)
蚂蚁金服阳振坤老师的“关系数据库的困境与出路”
京东搜索与大数据平台部的王春明老师的“京东搜索架构演进之路”
京东金融-数据库中间件研发高级技术经理王义林的“分布式数据库CDS-原理与实践”
一:亿级数据秒处理架构设计
阳振坤老师主要讲述了阿里OceanBase数据库产生背景和OceanBase的特点,我主要归纳以下内容:
产生背景:阿里业务发展需要,阿里多部门合作共同完成
OceanBase特点:
OceanBase摒弃关系型数据库不紧急的DBMS功能,把有限的资源集中到关键点上
主要解决更新一致性、高性能、跨表读事务、范围查询、join、数据全量及增量的dump、批量数据导入
淘宝目前应用于收藏夹、用户爱好、订单、购物车等信息
OceanBase逻辑架构:
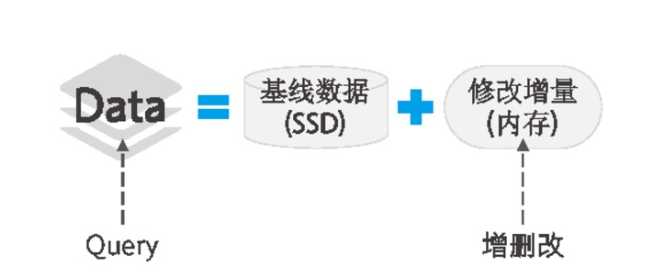
数据分类 存放数据库服务器 存储介质/场景/作用
基准数据 chunkServer ssd
动态数据 updateServer 内存
合并数据 mergeServer 1用户查询、2动态数据转储形成新的基准数据
RootServe RootServe 了避免软件硬件故障导致的服务中断,RootServer记录commit log并通常采用双机热备
单元过程
冻结 动态数据达到一定规模,停止该块的修改
转储 访问量波谷时(一般是夜间凌晨)持久化到SSD生成新的基准数据
数据合并 合并数据
阿里的秒级峰值14万订单
10GB内存服务于100M记录(约1亿条数据)修改
row key 分段形成表(类似于水平拆分表)
模拟过程:
。
1部署完成
2最开始: (RootServe资源调度管理)用户进行增删改的数据写入chunkServer内存块,即动态数据存入内存
3数据累计到一定规模,即内存块占用达到一定大小(如:200MB),冻结该内存块,开始写入新内存块(新块满后继续冻结,然后开新块,依此。),即冻结
4用户查询,mergeServer将chunkServer和updateServer查询出来合并成完整数据,返回给用户,即数据合并
5用户修改或删除数据,跟踪updateServer用户数据所在的内存块(全部:冻结中、未冻结)并修改对应数据。
6闲时(夜间)mergeServer将chunkServer中冻结块和updateServer查询出来合并成完整数据,形成新的基准数据并回写到chunkServer服务器的SSD上持久化,即转储
7如此循环处理。
核心总结:OceanBase最重要的架构设计思路是,内存执行CRUD,增量处理,定时更新到SSD持久化存储
GitHub源代码地址:https://github.com/alibaba/oceanbase
2016sdcc中国开发者大会参后感(一):亿级数据秒处理架构设计
标签:自己 ima 资源 合并 初创公司 增删改 紧急 中断 背景
原文地址:http://www.cnblogs.com/xiachuangfu/p/6119328.html