标签:其他 文件系统 点击 最大 mapreduce roo 练习 工作量 客户
Hadoop Day3

MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题.
这两个函数的形参是key、value对,表示函数的输入信息。
map、reduce键值对格式:
|
函数 |
输入键值对 |
输出键值对 |
|
Map() |
<K1,V1> |
<K2,V2> |
|
Reduce() |
<K2,{V2}> |
<k3,V3> |
2.MapReduce执行过程概要描述(***必须理解掌握****
为了更简单的理解MapReducer的执行过程,先对它来个总体的过程图如下:
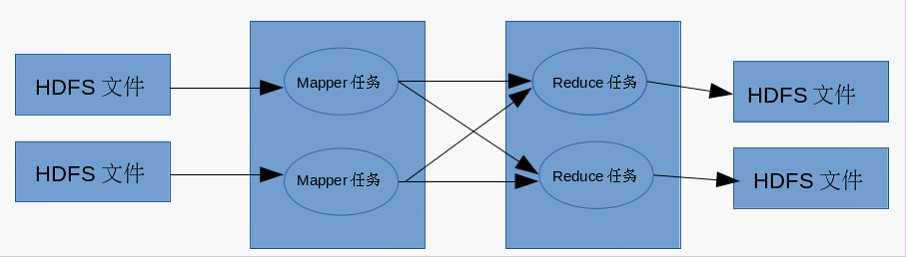
概要说明:
MapReduce运行的时候,通过Mapper运行的任务读取HDFS中的数据文件,然后调用自己的map方法,处理数据,最后输出。Reducer任务会接收Mapper任务输出的数据,作为自己的输入数据,调用自己的方法reduce,最后输出到HDFS的文件中。
每个Mapper任务是一个java进程,它会读取HDFS中的文件,解析成很多的键值对,经过我们覆盖的map方法处理后,转换为很多的键值对再输出。整个Mapper任务的处理过程又可以分为以下几个阶段,如图所示:
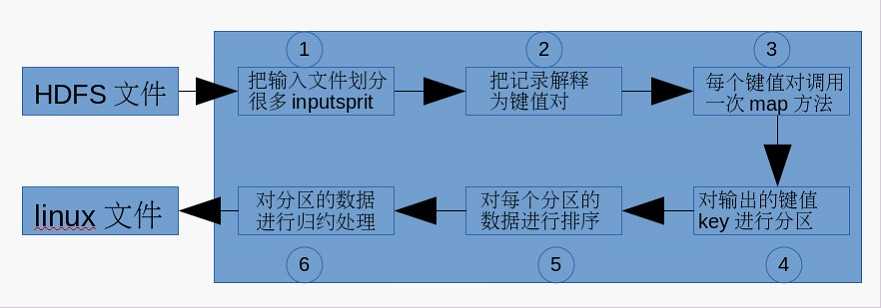
每个Reducer任务是一个java进程。
Reducer任务接收Mapper任务的输出,归约处理后写入到HDFS中,可以分为如下图所示的几个阶段。
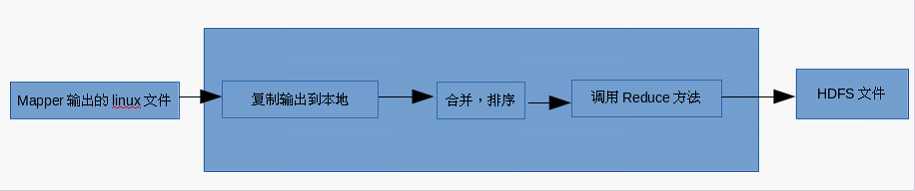
注意:在整个MapReduce程序的开发过程中,我们最大的工作量是覆盖map函数和覆盖reduce函数。
例子说明:统计hdfs文件系统中的words.txt单词个数。
vim words.txt
hadoop fs –put /root/words.txt /
hadoop fs –ls /
导入${HADOOP-HOME}/share/hadoop/mapreduce红色中部分的包。
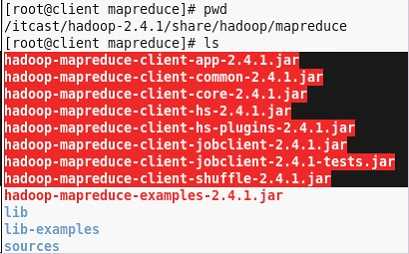
和导入${HADOOP-HOME}/share/hadoop/mapreduce/lib/*
在客户端创建
public class WcMapper extends Mapper<LongWritable, Text, Text, LongWritable>{
@Override
protected void map(LongWritable key, Text value,
Mapper<LongWritable, Text, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
//接收数据
String line = value.toString();
//切分数据
String [] words = line.split(" ");
//循环
for(String w : words){
//出现一次,记个1,输出
context.write(new Text(w), new LongWritable(1));
}
}
}
public class WcReducer extends Reducer<Text, LongWritable, Text, LongWritable>{
@Override
protected void reduce(Text key, Iterable<LongWritable> v2s,
Reducer<Text, LongWritable, Text, LongWritable>.Context context)
throws IOException, InterruptedException {
//定义一个计算器
long counter = 0;
//循环v2s
for (LongWritable v : v2s) {
counter +=v.get();
}
//输出
context.write(key, new LongWritable(counter));
}
}
public class WordCount {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Job job = Job.getInstance(new Configuration());
//注意:加载main方法所在的类
job.setJarByClass(WordCount.class);
//设置Mapper与Reducer的类
job.setMapperClass(WcMapper.class);
job.setReducerClass(WcReducer.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.0.2:9000/words.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.0.2:9000/output"));
//设置输入和输出的相关属性
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
job.waitForCompletion(true);
}
}
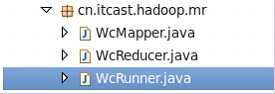
在项目中点击右键“export...”,如下图所示
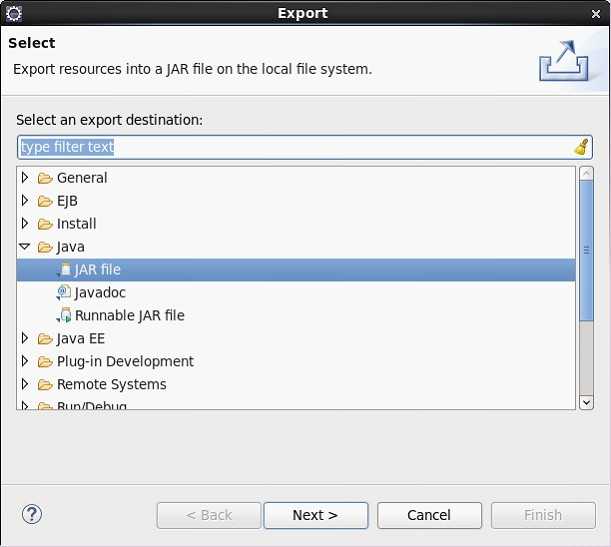
点击“next”,择jar file导出的位置。
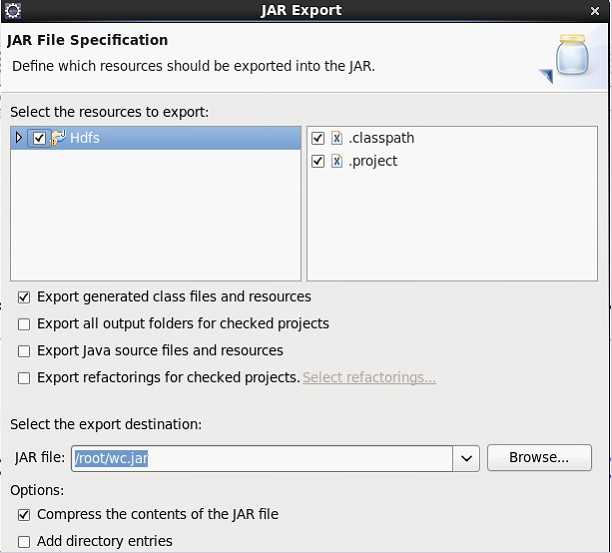
点击“next”再点击“next”择main函数的类后点ok ,完毕!
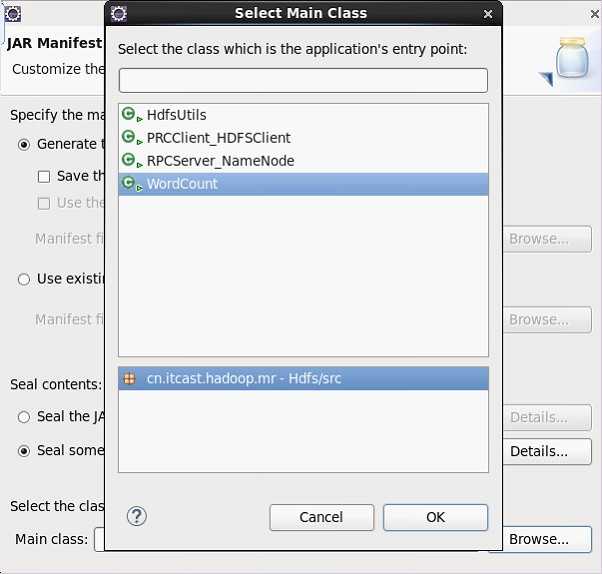
把wc.jar上传到服务器测试。
scp –r /root/wcRunner.jar 192.168.174.21:/root/

删除最后两行
hadoop jar /root/wcRunner.jar
hadoop fs –ls /
也可以直接在本地模式下运行,需要把yarn下的所jar包导入工程,

需在输入,输出里加入前缀“file://”
Hadoop的运行模式以下种:
牋(1独立模式(即本地模式(standalone或local mode
牋牋? 无需运行任何守护进程(daemon,所程序都在单个JVM上执行。由于在本机模式下测试和调试MapReduce程序较为方便,因此,这种模式适宜用在开发阶段。
牋(2伪分布模式(pseudo-distributed model
牋牋? Hadoop守护进程运行在本地机器上,模拟一个小规模的集群。
牋(3全分布模式(fully distributed model
牋牋? Hadoop守护进程运行在一个集群上,此模式以后会详细介绍。
在特定模式下运行Hadoop需要关注两个因素:正确设置属性和启动Hadoop守护进程。
下表列举了配置各种模式所需要的最小属性集合:
|
组件名称 |
属性名称 |
独立模式 |
伪分布模式 |
全分布模式 |
|
Common |
fs.default.name |
file:///(默认 |
hdfs://localhost/ |
hdfs://namenode/ |
|
HDFS |
dfs.replication |
N/A |
1 |
3(默认 |
|
MapReduce |
mapred.job.tracker |
local(默认 |
localhost:8021 |
namenode:8021 |
牋?在独立模式下,将使用本地文件系统和本地MapReduce作用运行期;在分布式模式下,将启动HDFS和MapReduce守护进程。
4.深入MapReduce执行过程细节源码分析
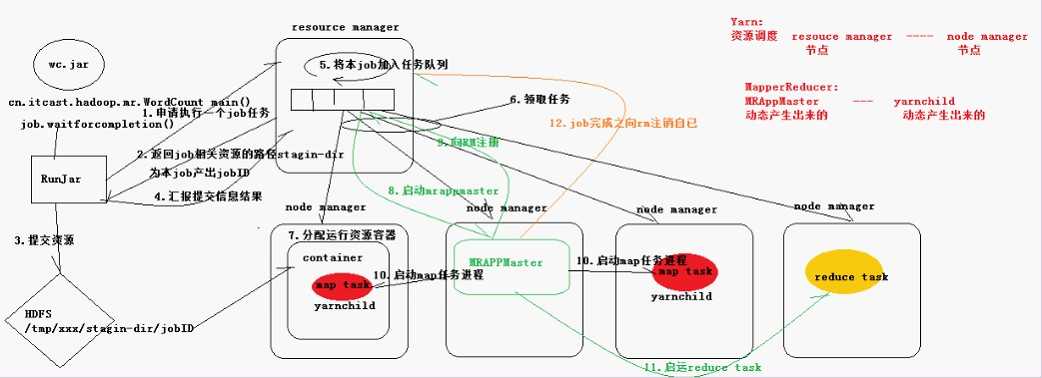
MR执行流程
(1).客户端提交一个mr的jar包给JobClient(提交方式:hadoop jar ...)
(2).JobClient通过RPC和JobTracker进行通信,返回一个存放jar包的地址(HDFS和jobId
(3).client将jar包写入到HDFS当中(path = hdfs上的地址 + jobId)
(4).开始提交任务(任务的描述信息,不是jar, 包括jobid,jar存放的位置,配置信息等等)
(5).JobTracker进行初始化任务
(6).读取HDFS上的要处理的文件,开始计算输入分片,每一个分片对应一个MapperTask
(7).TaskTracker通过心跳机制领取任务(任务的描述信息
(8).下载所需的jar,配置文件等
(9).TaskTracker启动一个java child子进程,用来执行具体的任务(MapperTask或ReducerTask
(10).将结果写入到HDFS当中
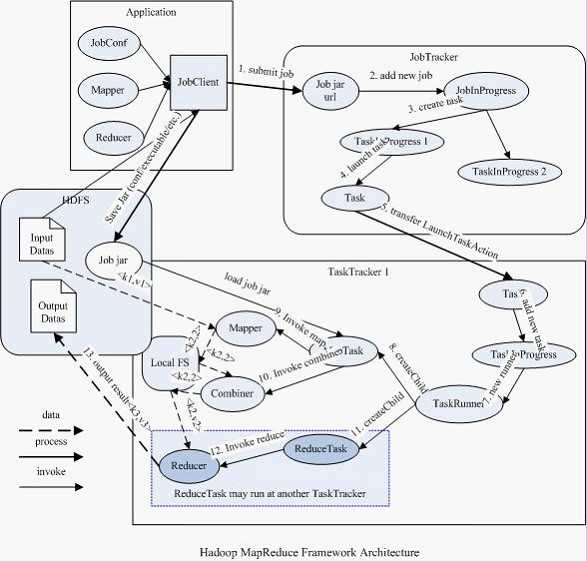
备注:
配置完成后,通过JobClient提交
存在单点故障,hadoop2.0解决了这个问题
思考题与练习
标签:其他 文件系统 点击 最大 mapreduce roo 练习 工作量 客户
原文地址:http://www.cnblogs.com/9yuegoodnight/p/6119744.html