标签:逻辑 fsync Lucene 优化 方式 field tab 搜索 write
Elasticsearch 是最近两年异军突起的一个兼有搜索引擎和NoSQL数据库功能的开源系统,基于Java/Lucene构建。最近研究了一下,感觉 Elasticsearch 的架构以及其开源的生态构建都有许多可借鉴之处,所以整理成文章分享下。本文的代码以及架构分析主要基于 Elasticsearch 2.X 最新稳定版。
Elasticsearch 看名字就能大概了解下它是一个弹性的搜索引擎。首先弹性隐含的意思是分布式,单机系统是没法弹起来的,然后加上灵活的伸缩机制,就是这里的 Elastic 包含的意思。它的搜索存储功能主要是 Lucene 提供的,Lucene 相当于其存储引擎,它在之上封装了索引,查询,以及分布式相关的接口。
Elasticsearch 中的几个概念
集群(Cluster)一组拥有共同的 cluster name 的节点。
节点(Node) 集群中的一个 Elasticearch 实例。
索引(Index) 相当于关系数据库中的database概念,一个集群中可以包含多个索引。这个是个逻辑概念。
主分片(Primary shard) 索引的子集,索引可以切分成多个分片,分布到不同的集群节点上。分片对应的是 Lucene 中的索引。
副本分片(Replica shard)每个主分片可以有一个或者多个副本。
类型(Type)相当于数据库中的table概念,mapping是针对 Type 的。同一个索引里可以包含多个 Type。
Mapping 相当于数据库中的schema,用来约束字段的类型,不过 Elasticsearch 的 mapping 可以自动根据数据创建。
文档(Document) 相当于数据库中的row。
字段(Field)相当于数据库中的column。
分配(Allocation) 将分片分配给某个节点的过程,包括分配主分片或者副本。如果是副本,还包含从主分片复制数据的过程。
搜索引擎 Search
Elasticsearch 除了支持 Lucene 本身的检索功能外,在之上做了一些扩展。 1. 脚本支持
Elasticsearch 默认支持groovy脚本,扩展了 Lucene 的评分机制,可以很容易的支持复杂的自定义评分算法。它默认只支持通过sandbox方式实现的脚本语言(如lucene expression,mustache),groovy必须明确设置后才能开启。Groovy的安全机制是通过java.security.AccessControlContext设置了一个class白名单来控制权限的,1.x版本的时候是自己做的一个白名单过滤器,但限制策略有漏洞,导致一个远程代码执行漏洞。 2. 默认会生成一个 _all 字段,将所有其他字段的值拼接在一起。这样搜索时可以不指定字段,并且方便实现跨字段的检索。 3. Suggester Elasticsearch 通过扩展的索引机制,可以实现像google那样的自动完成suggestion以及搜索词语错误纠正的suggestion。
NoSQL 数据库
Elasticsearch 可以作为数据库使用,主要依赖于它的以下特性:
默认在索引中保存原始数据,并可获取。这个主要依赖 Lucene 的store功能。
实现了translog,提供了实时的数据读取能力以及完备的数据持久化能力(在服务器异常挂掉的情况下依然不会丢数据)。Lucene 因为有 IndexWriter buffer, 如果进程异常挂掉,buffer中的数据是会丢失的。所以 Elasticsearch 通过translog来确保不丢数据。同时通过id直接读取文档的时候,Elasticsearch 会先尝试从translog中读取,之后才从索引中读取。也就是说,即便是buffer中的数据尚未刷新到索引,依然能提供实时的数据读取能力。Elasticsearch 的translog 默认是每次写请求完成后统一fsync一次,同时有个定时任务检测(默认5秒钟一次)。如果业务场景需要更大的写吞吐量,可以调整translog相关的配置进行优化。
强大,其生态圈里的 Kibana 主要就是依赖aggregation来实现数据分析以及可视化的。
典型应用场景一:云分析业务
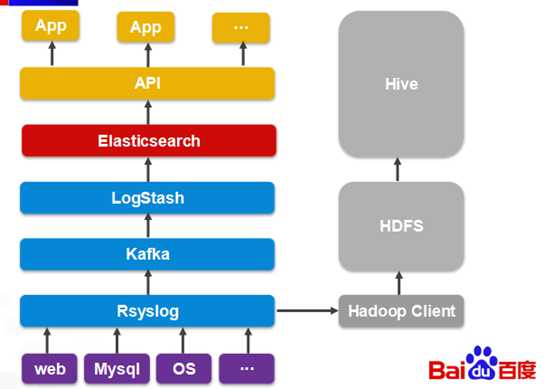
解决方案:根据索引大小分别设置分片数,充分利用type合并索引
除分词字段外,其他字段全部存储为doc value、master node、data node、client node 分离部署保守设置fielddata内存占用软硬限,及其他内存占用限制
设置fielddata有效期。
典型应用场景二:casio业务
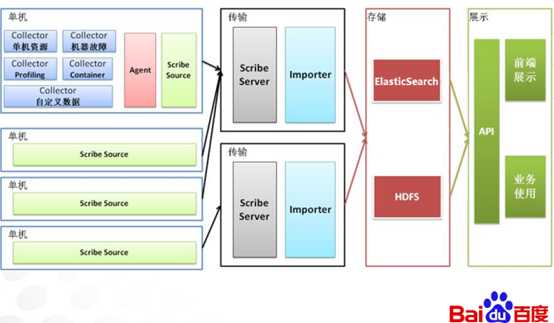
解决方案:
使用动态mapping自动匹配未知字段
数据分发到所有节点批量导入
全部使用doc value存储,减少内存消耗
使用模板,分天级、小时级自动创建索引
SSD与SATA分组,冷数据定期自动迁移
标签:逻辑 fsync Lucene 优化 方式 field tab 搜索 write
原文地址:http://www.cnblogs.com/zhangxiaokai/p/6127348.html