标签:本地 job span 常用操作 等级 apache 令行 ack 比较
我用一个集团公司对人事信息处理场景的简单案例,来作为入门,详细分析DataFrame上的各种常用操作,包括集团子公司的职工人事信息的合并,职工的部门相关信息查询、职工信息的统计、关联职工与部门信息的统计,以及如何将各种统计得到的结果存储到外部存储系统等。
在此入门案例里,涉及的DataFrame实例内容包括从外部文件构建DataFrame,在DataFram上比较常用的操作,多个DataFrame之间的操作,以及DataFrame的持久化操作等内容。
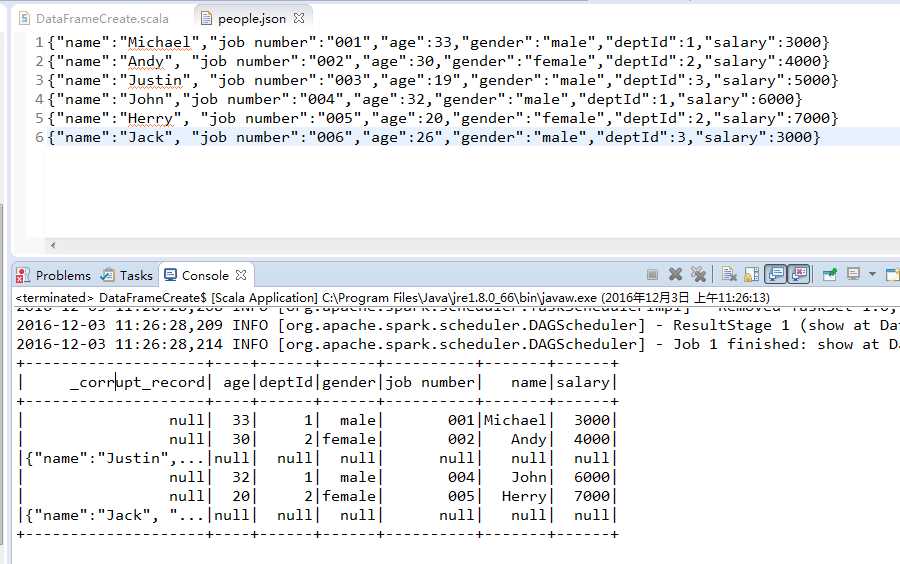
注意,如果文件中存在换行回车符,以及文件中的一些错误,都会出现“corrupt_record"错误。如果没有则能够正常导入。
修正后
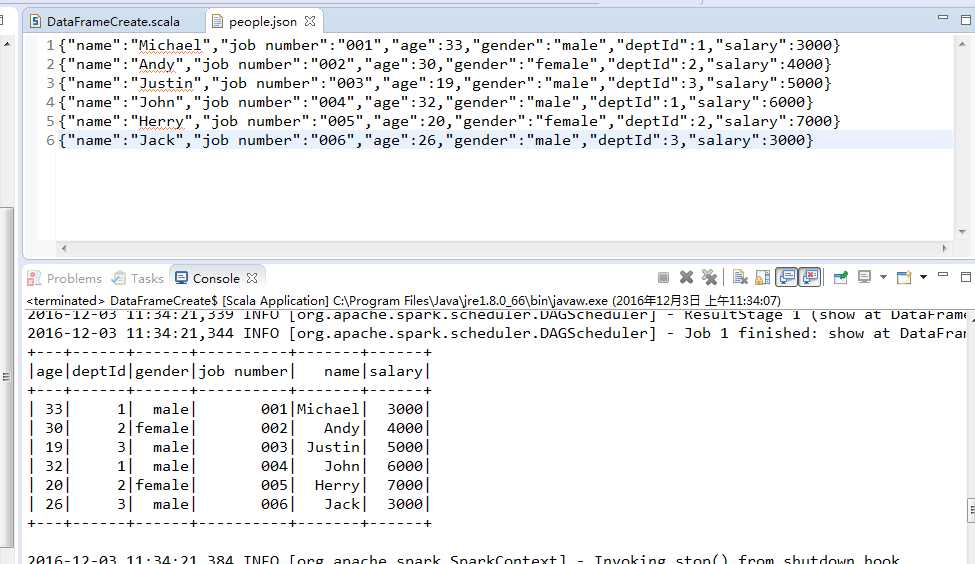
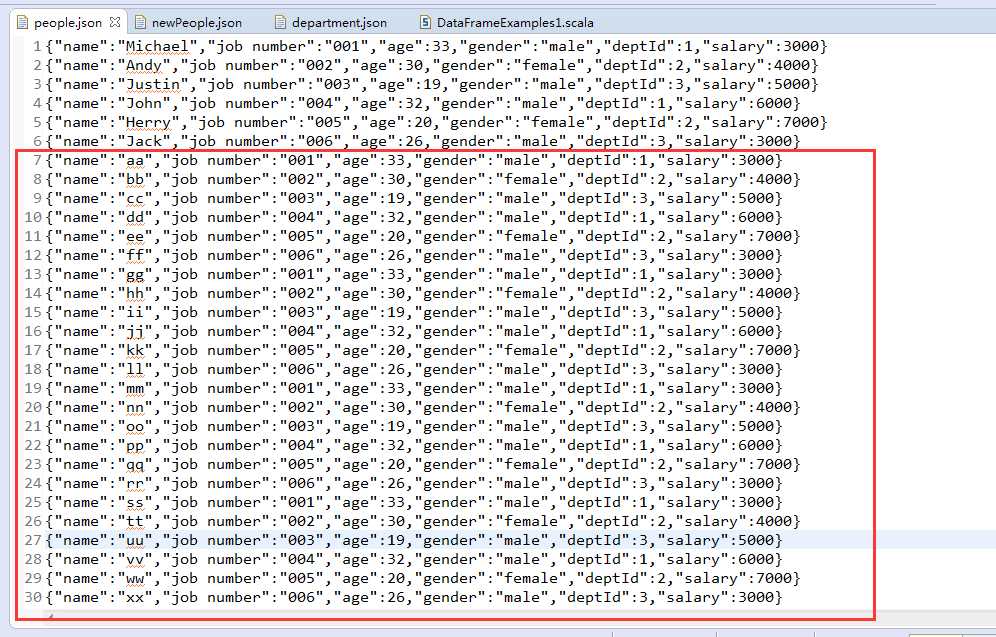
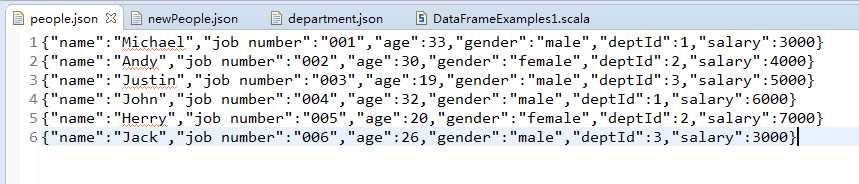
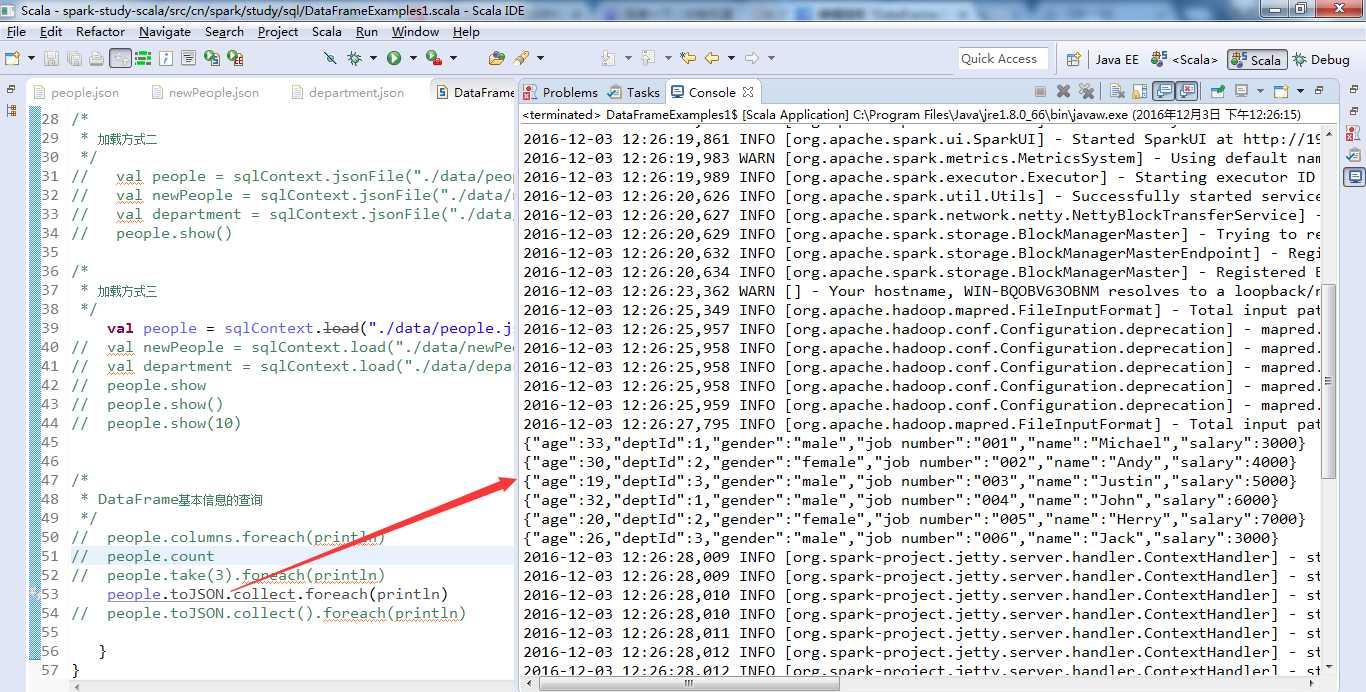
people.json
{"name":"Michael","job number":"001","age":33,"gender":"male","deptId":1,"salary":3000}
{"name":"Andy","job number":"002","age":30,"gender":"female","deptId":2,"salary":4000}
{"name":"Justin","job number":"003","age":19,"gender":"male","deptId":3,"salary":5000}
{"name":"John","job number":"004","age":32,"gender":"male","deptId":1,"salary":6000}
{"name":"Herry","job number":"005","age":20,"gender":"female","deptId":2,"salary":7000}
{"name":"Jack","job number":"006","age":26,"gender":"male","deptId":3,"salary":3000}
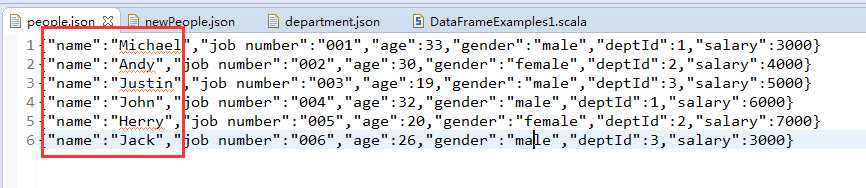
people.json文件包含了员工的相关信息,每一列分别对应:员工姓名、工号、年龄、性别、部门ID以及薪资。
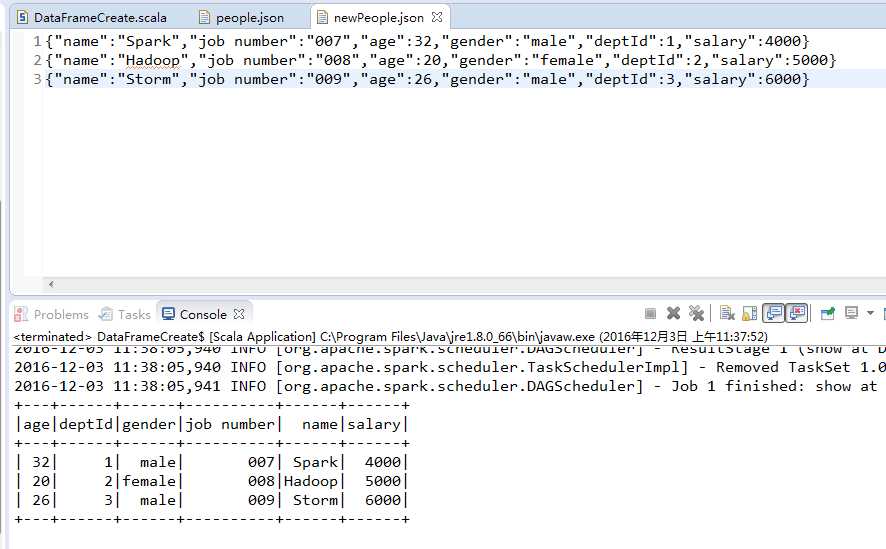
newPeople.json
{"name":"Spark","job number":"007","age":32,"gender":"male","deptId":1,"salary":4000}
{"name":"Hadoop","job number":"008","age":20,"gender":"female","deptId":2,"salary":5000}
{"name":"Storm","job number":"009","age":26,"gender":"male","deptId":3,"salary":6000}
该文件对应新入职员工的信息
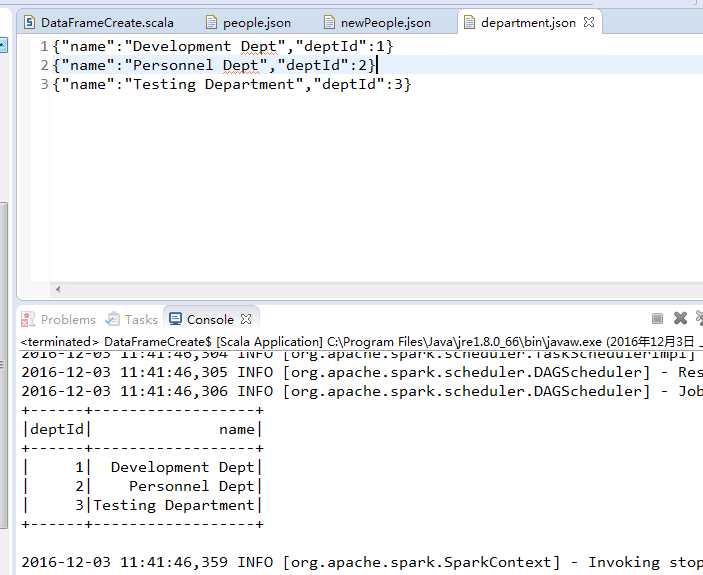
department.json
{"name":"Development Dept","deptId":1}
{"name":"Personnel Dept","deptId":2}
{"name":"Testing Department","deptId":3}
该文件是员工们的部门信息,包含部门的名称和部门ID。其中,部门ID对应员工信息中的部门ID,即员工的deptId列
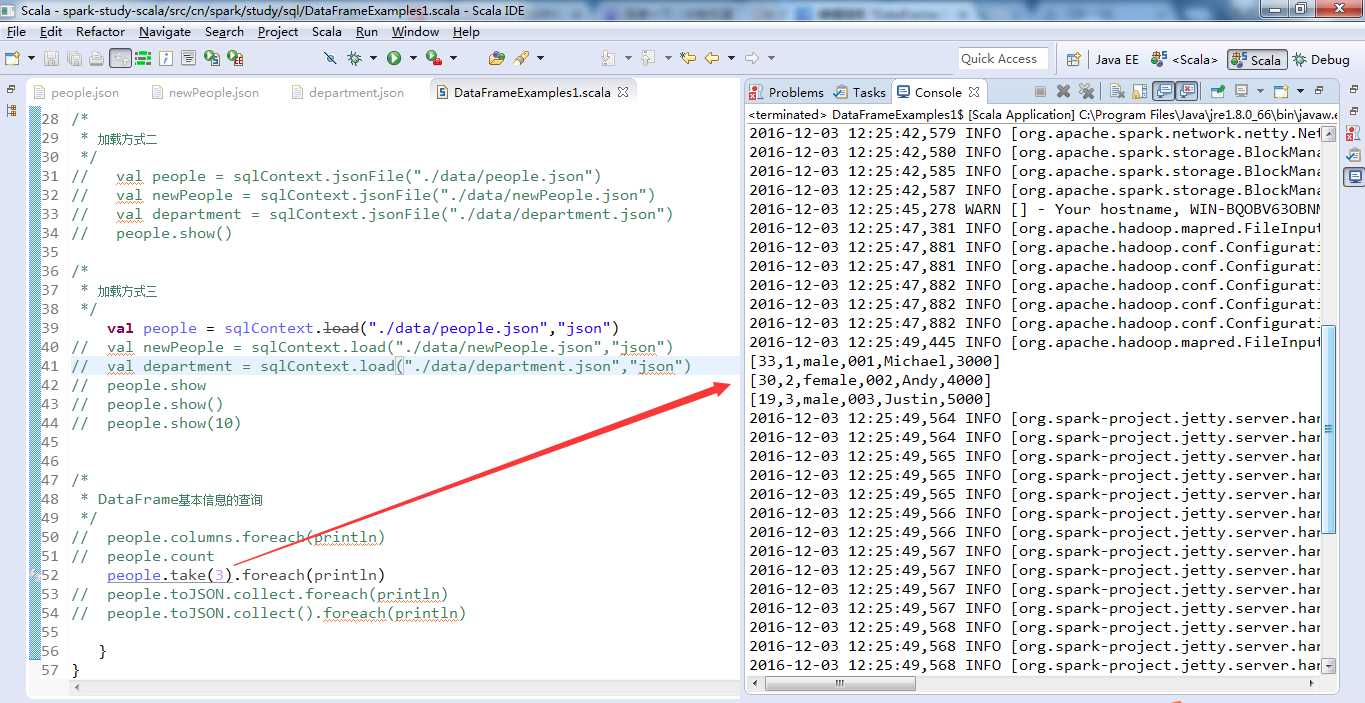
编写代码
加载方式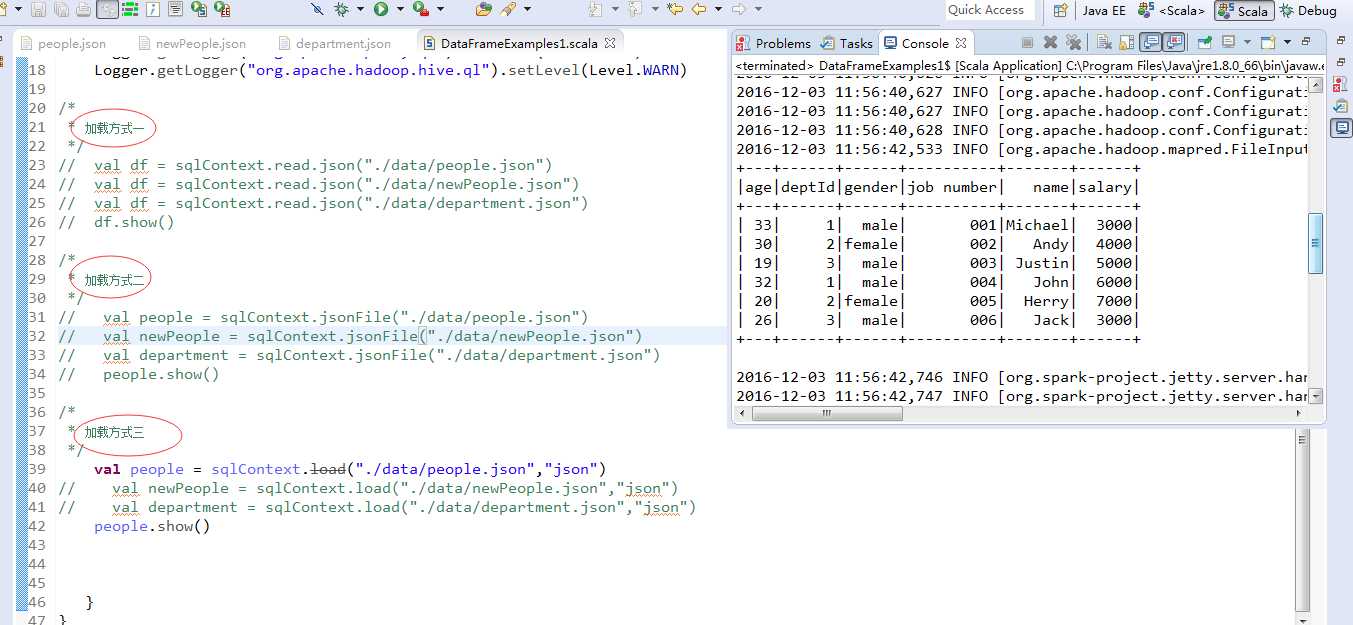
以上,我提供了3种方式加载本地文件,当然HDFS上的文件,差不多啦。
people、newpeople、department是生成的3个DataFrame实例,同时根据文件内容自动地推导出三个DataFrame实例的schema信息,schema信息包含了列的名字以及对应的数据类型,如dept的schema信息为[deptId : bigint,name,string]
以表格形式查看DataFrame信息
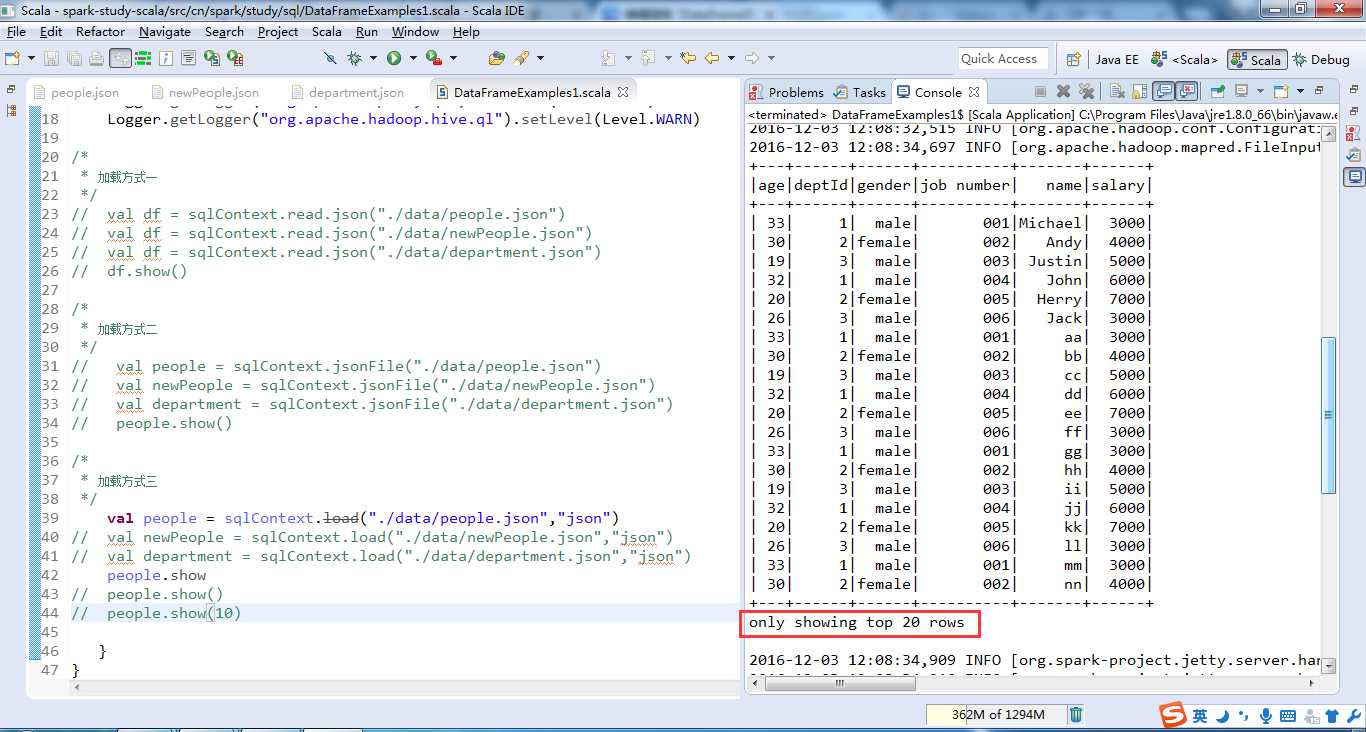
people.show()
通过show方法,可以以表格形式输出各个DataFrame的内容。默认情况下会显示DataFrame的20条记录,可以通过设置show方法的参数来指定输出的记录条数。
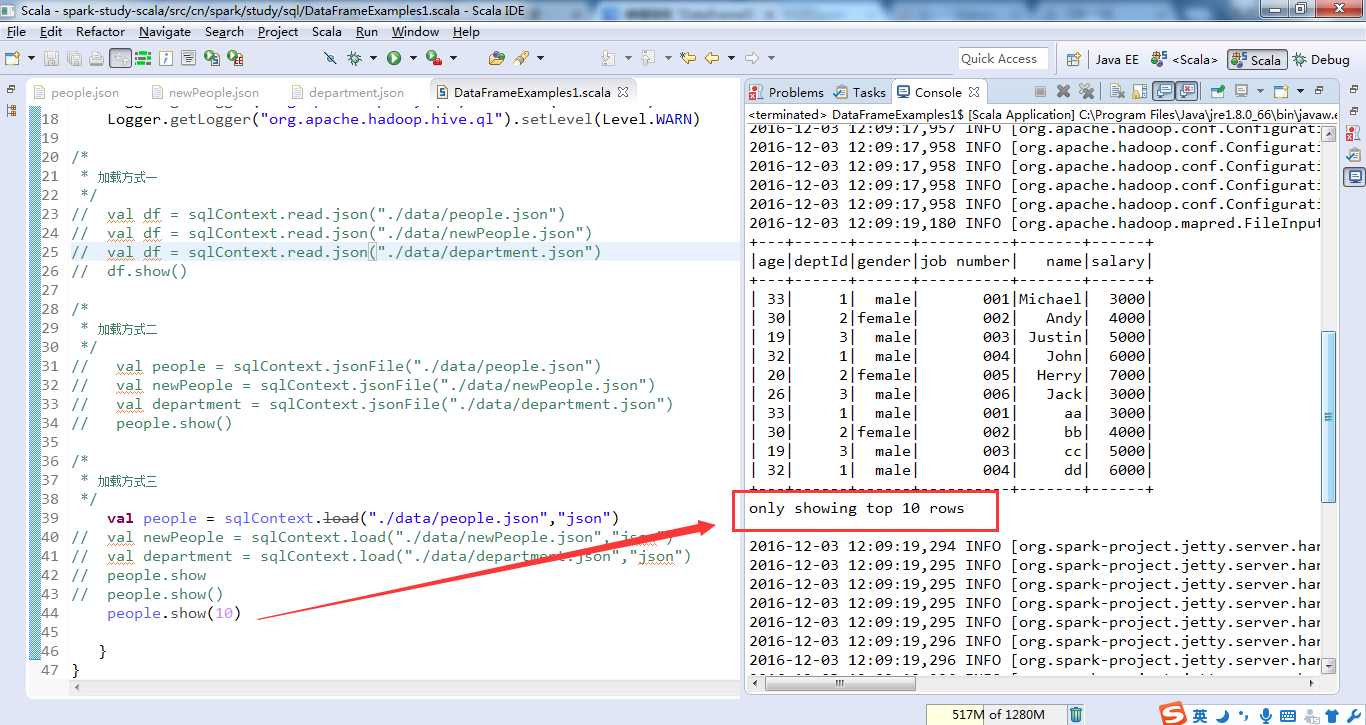
如people.show(10),显示前10条记录。
为了模拟,加大people.json文件里的数据
{"name":"Michael","job number":"001","age":33,"gender":"male","deptId":1,"salary":3000}
{"name":"Andy","job number":"002","age":30,"gender":"female","deptId":2,"salary":4000}
{"name":"Justin","job number":"003","age":19,"gender":"male","deptId":3,"salary":5000}
{"name":"John","job number":"004","age":32,"gender":"male","deptId":1,"salary":6000}
{"name":"Herry","job number":"005","age":20,"gender":"female","deptId":2,"salary":7000}
{"name":"Jack","job number":"006","age":26,"gender":"male","deptId":3,"salary":3000}
{"name":"aa","job number":"001","age":33,"gender":"male","deptId":1,"salary":3000}
{"name":"bb","job number":"002","age":30,"gender":"female","deptId":2,"salary":4000}
{"name":"cc","job number":"003","age":19,"gender":"male","deptId":3,"salary":5000}
{"name":"dd","job number":"004","age":32,"gender":"male","deptId":1,"salary":6000}
{"name":"ee","job number":"005","age":20,"gender":"female","deptId":2,"salary":7000}
{"name":"ff","job number":"006","age":26,"gender":"male","deptId":3,"salary":3000}
{"name":"gg","job number":"001","age":33,"gender":"male","deptId":1,"salary":3000}
{"name":"hh","job number":"002","age":30,"gender":"female","deptId":2,"salary":4000}
{"name":"ii","job number":"003","age":19,"gender":"male","deptId":3,"salary":5000}
{"name":"jj","job number":"004","age":32,"gender":"male","deptId":1,"salary":6000}
{"name":"kk","job number":"005","age":20,"gender":"female","deptId":2,"salary":7000}
{"name":"ll","job number":"006","age":26,"gender":"male","deptId":3,"salary":3000}
{"name":"mm","job number":"001","age":33,"gender":"male","deptId":1,"salary":3000}
{"name":"nn","job number":"002","age":30,"gender":"female","deptId":2,"salary":4000}
{"name":"oo","job number":"003","age":19,"gender":"male","deptId":3,"salary":5000}
{"name":"pp","job number":"004","age":32,"gender":"male","deptId":1,"salary":6000}
{"name":"qq","job number":"005","age":20,"gender":"female","deptId":2,"salary":7000}
{"name":"rr","job number":"006","age":26,"gender":"male","deptId":3,"salary":3000}
{"name":"ss","job number":"001","age":33,"gender":"male","deptId":1,"salary":3000}
{"name":"tt","job number":"002","age":30,"gender":"female","deptId":2,"salary":4000}
{"name":"uu","job number":"003","age":19,"gender":"male","deptId":3,"salary":5000}
{"name":"vv","job number":"004","age":32,"gender":"male","deptId":1,"salary":6000}
{"name":"ww","job number":"005","age":20,"gender":"female","deptId":2,"salary":7000}
{"name":"xx","job number":"006","age":26,"gender":"male","deptId":3,"salary":3000}
DataFrame基本信息的查询
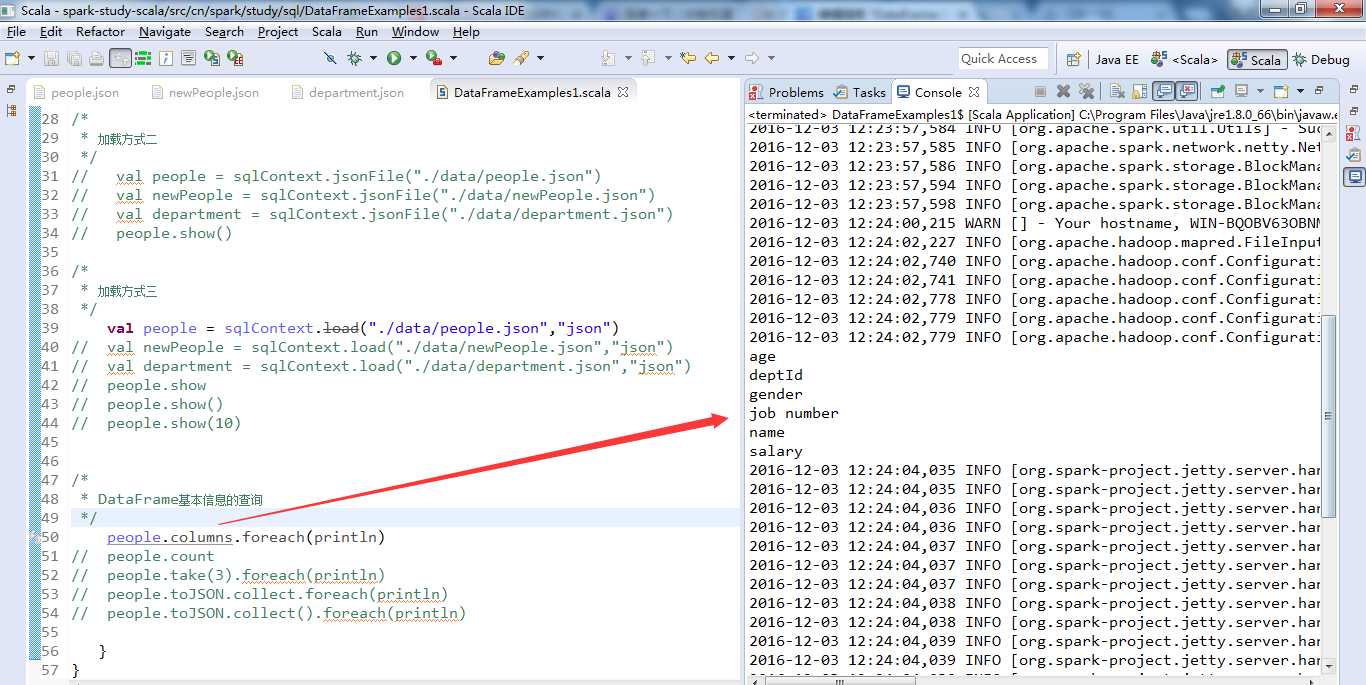
使用DataFrame的columsns方法,查询people包含的全部列信息,以数组的形式返回列名组。
Array[String]=Array(age,deptId,gender,job number,name,salary)
使用DataFrame的count方法,统计people包含的记录条数,即员工个数。
Long=6
使用DataFram的take方法,获取前三条员工记录信息,并以数组形式呈现出来。
Array[org.apache.spark.sql.Row] = Array( [33,1,male,001,Michael,3000],[30,2,female,002,Andy,4000],[19,3,male,003,Justin,5000] )
使用DataFrame的toJSON方法,将people转换成JsonRDD类型,并使用RDD的collect方法返回其包含的员工信息。
Array[String] = Array( {"age":33,"deptId":1,"gender":"male","job number":"001","name":"Michael","salary":3000},{"age":30,"deptId":2,"gender":"female","job number":"002","name":"Andy","salary":4000},{"age":19,"deptId":3,"gender":"male","job number":"003","name":"Justin","salary":5000},{"age":32,"deptId":1,"gender":"male","job number":"004","name":"John","salary":6000},{"age":20,"deptId":2,"gender":"female","job number":"005","name":"Herry","salary":7000},{"age":26,"deptId":3,"gender":"male","job number":"006","name":"Jack","salary":3000})
对员工信息进行条件查询,并输出结果

在命令行里,执行这些
使用count方法统计了"gender”列为"male”的员工数量
Long = 4

基于“age”和“gender”这两列,使用不同的查询条件,不同的DataFrame API,即where和filter方法,对员工信息进行过滤。最后使用show方法,将查询结果以表格形式呈现出来。
Long = 4
age depId gender job number name salary
33 1 male 001 Michael 3000
30 2 female 002 Andy 4000
32 1 male 004 John 6000
26 3 male 006 Jack 3000
age depId gender job number name salary
33 1 male 001 Michael 3000
30 2 female 002 Andy 4000
32 1 male 004 John 6000
26 3 male 006 Jack 3000

age depId gender job number name salary
33 1 male 001 Michael 3000
32 1 male 004 John 6000
26 3 male 006 Jack 3000
age depId gender job number name salary
33 1 male 001 Michael 3000
30 2 female 002 Andy 4000
32 1 male 004 John 6000
26 3 male 006 Jack 3000
对员工信息进行,以指定的列名,以不同方式进行排序

先以“job number”列升序,再以“deptId”列降序
age depId gender job number name salary
33 1 male 001 Michael 3000
30 2 female 002 Andy 4000
19 3 male 003 Justin 5000
32 1 male 004 John 6000
20 2 female 005 Herry 7000
26 3 male 006 Jack 3000
以“job number”列进行默认排序(升序),并显示排序后的3条记录
age depId gender job number name salary
33 1 male 001 Michael 3000
30 2 female 002 Andy 4000
19 3 male 003 Justin 5000
以“job number”列进行默认排序(升序),并显示排序后的3条记录
age depId gender job number name salary
33 1 male 001 Michael 3000
30 2 female 002 Andy 4000
19 3 male 003 Justin 5000
age depId gender job number name salary
26 3 male 006 Jack 3000
20 2 female 005 Herry 7000
32 1 male 004 John 6000
19 3 male 003 Justin 5000
30 2 female 002 Andy 4000
33 1 male 001 Michael 3000
为员工信息增加一列:等级(“level”)

通过wihtColumns方法增加了新的一列等级信息,列名为“levle”,其中withColumns方法的"level”参数指定了新增列的列名,第二个参数指定了该列的实例,即通过“age”列转换得到新列,而people("age")方法则调用了DataFrame的apply方法,返回"age”列名对应的列。
age depId gender job number name salary level
33 1 male 001 Michael 3000 3.3
30 2 female 002 Andy 4000 3.0
19 3 male 003 Justin 5000 1.9
32 1 male 004 John 6000 3.2
20 2 female 005 Herry 7000 2.0
26 3 male 006 Jack 3000 2.6
修改工号列名
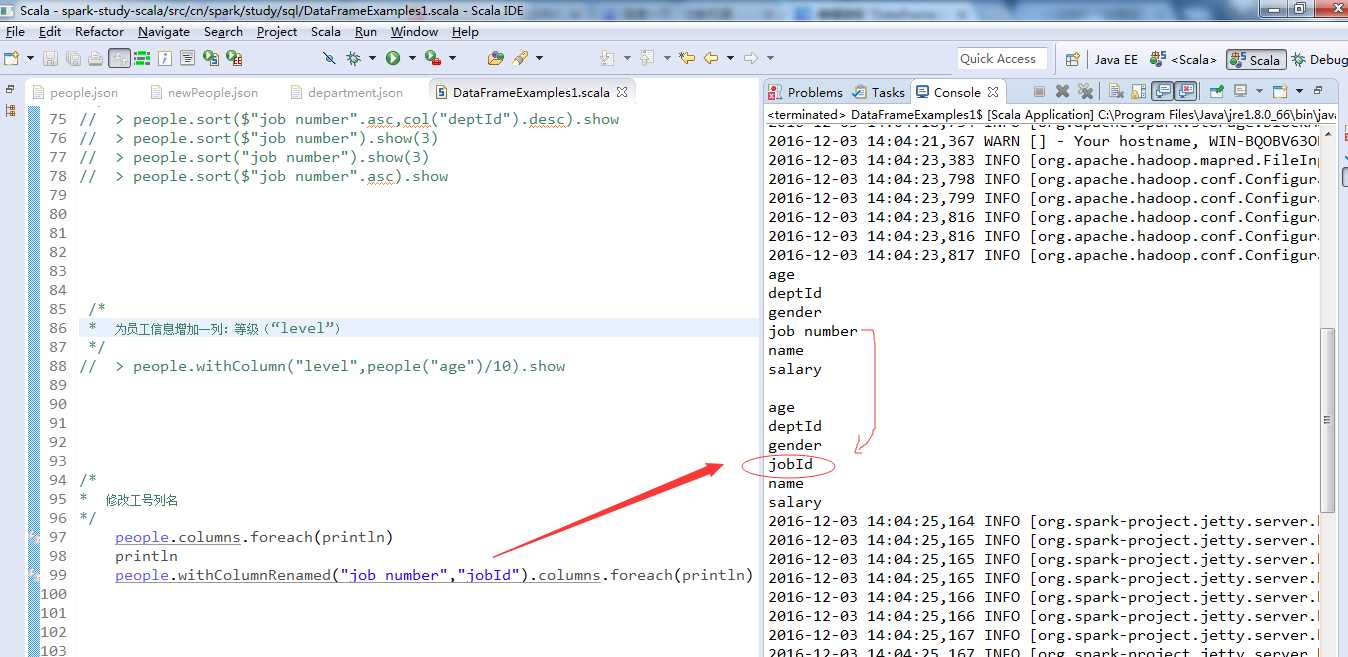
注意,修改的列名必须存在,如果不存在,不会报错,但列名不会修改。
Array[String] = Array( age,deptId,gender,job number,name,salary)
Array[String] = Array( age,deptId,gender,job Id,name,salary)
增加新员工
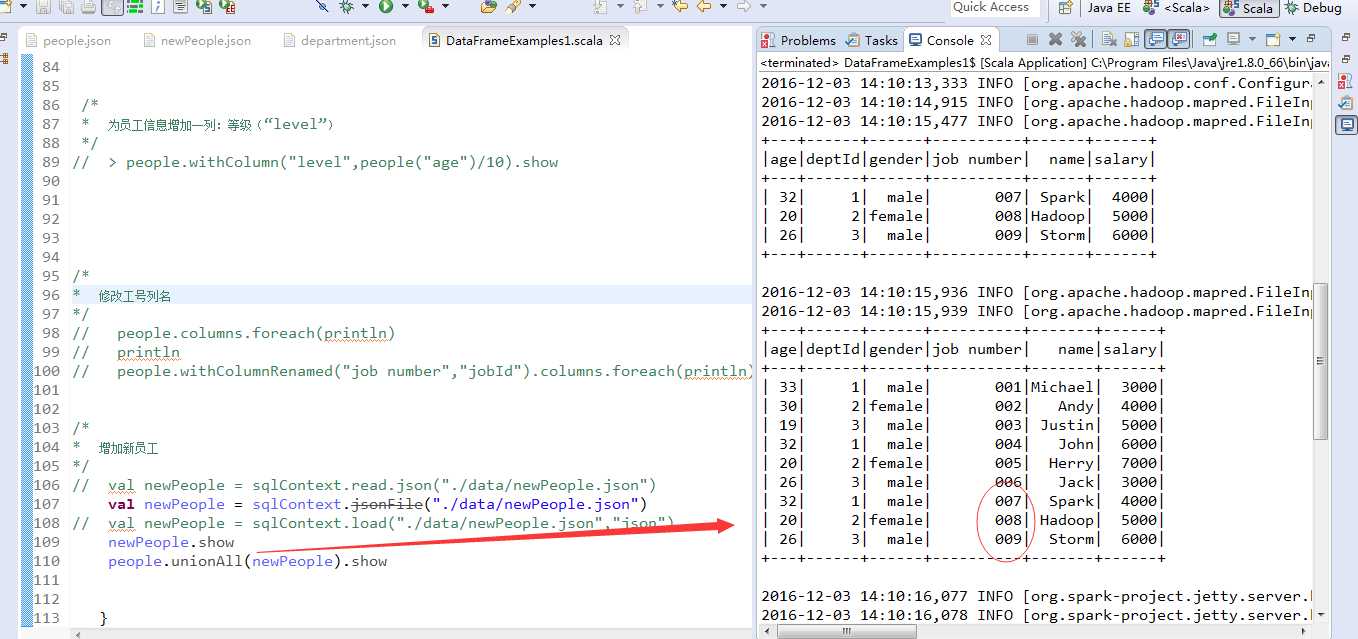
使用jsonFile方法加载了新员工信息的文件,然后调用people的unionAll方法,将新加载的newPeople合并起来。
查同名员工
这里,我更改下数据,故意有存在同名员工的情况。


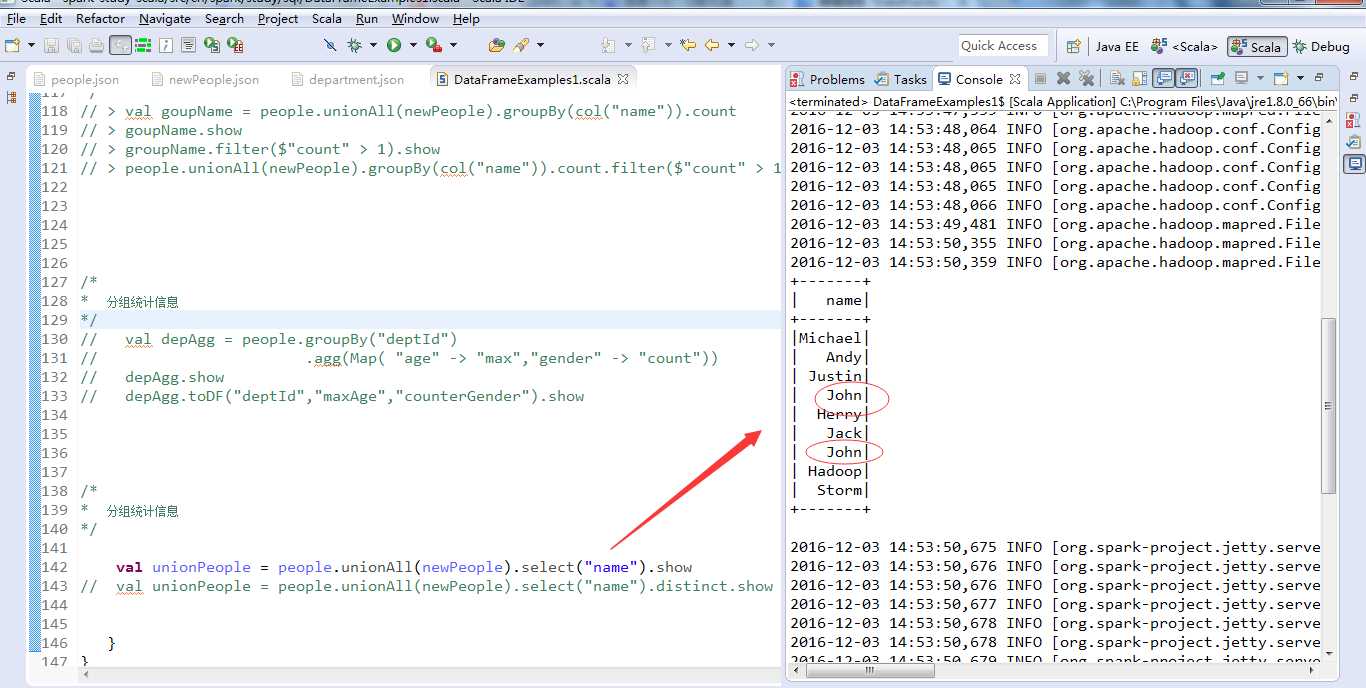
首先通过unionAll方法将people和newPeople进行合并,然后使用groupBy方法将合并后的DataFrame按照"name"列进行分组,分组操作会得到一个GroupData类型提供了一组非常有用的统计操作,这里继续调用它的count方法,最终实现对员工名字的分组计数。
groupName:org.apache.spark.sql.DataFrame=[name:string,count:bigint]
name count
Justin 1
Jack 1
John 2
Andy 1
Michael 1
Herry 1
Hadoop 1
Storm 1
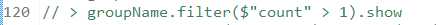
接着对groupName这个实例,进行过滤操作,使用filter方法,获取“name”列的计数大于1的内容,并以表格形式呈现。
name count
John 2
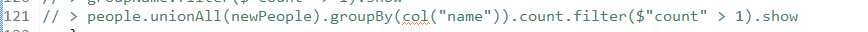
使用函数式编程范式,对前两个的合并,得到的结果是一样的
name count
Johb 2
分组统计信息
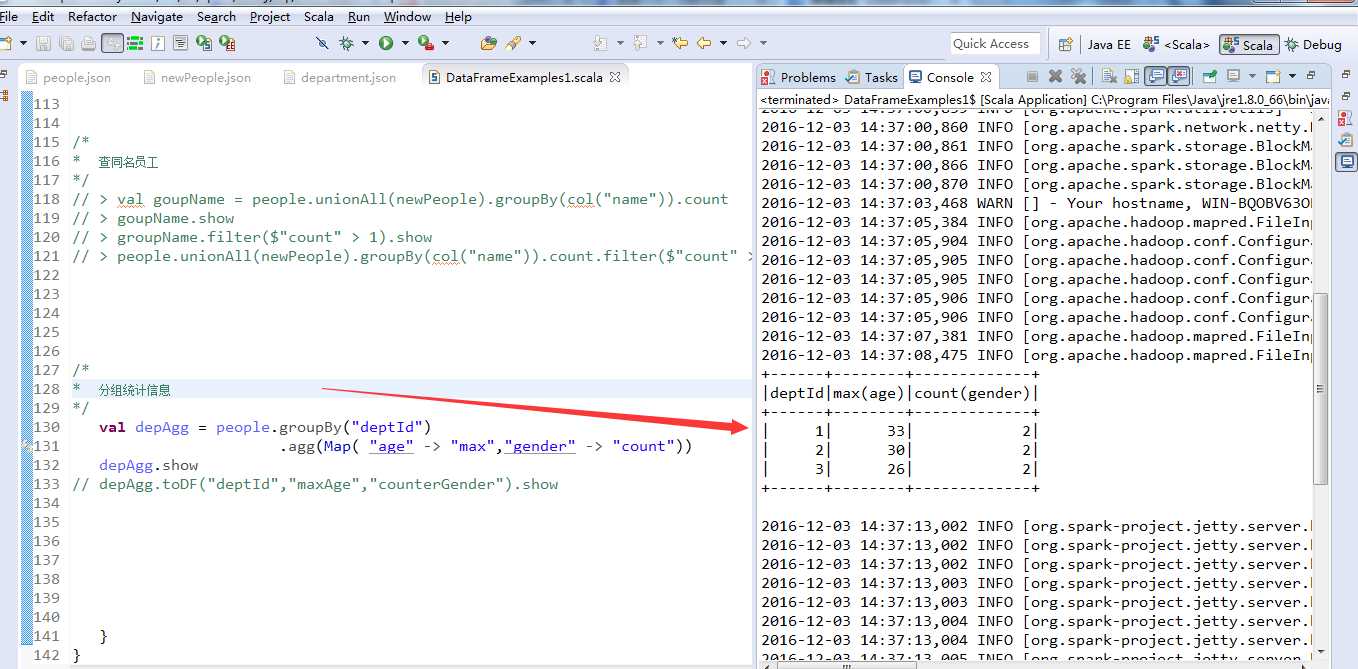
首先针对people的"deptId"列进行分组,分组后得到的GroupData实例继续调用agg方法,分别对"age"列求最大值,对"gender"进行计数。
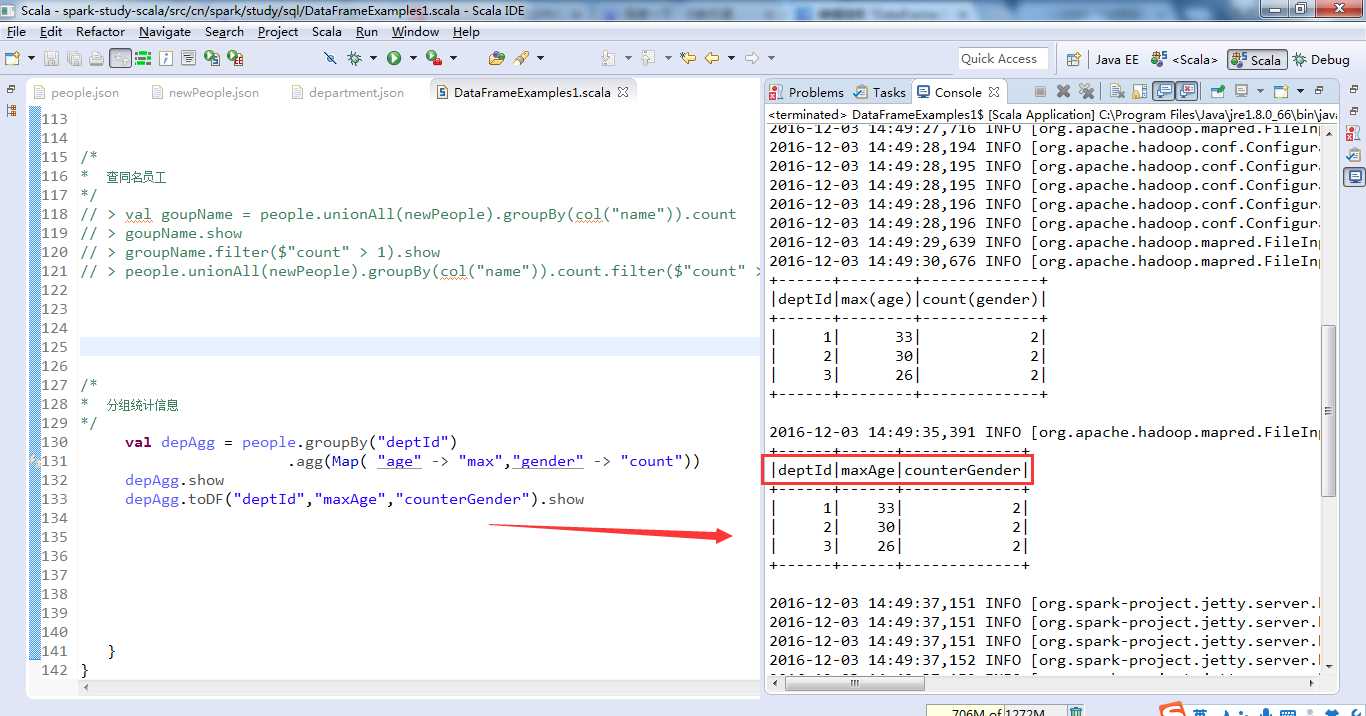
调用DataFrame的toDF方法,重新命名之前聚合得到的depAgg的全部列名,增加了列名的可读性。
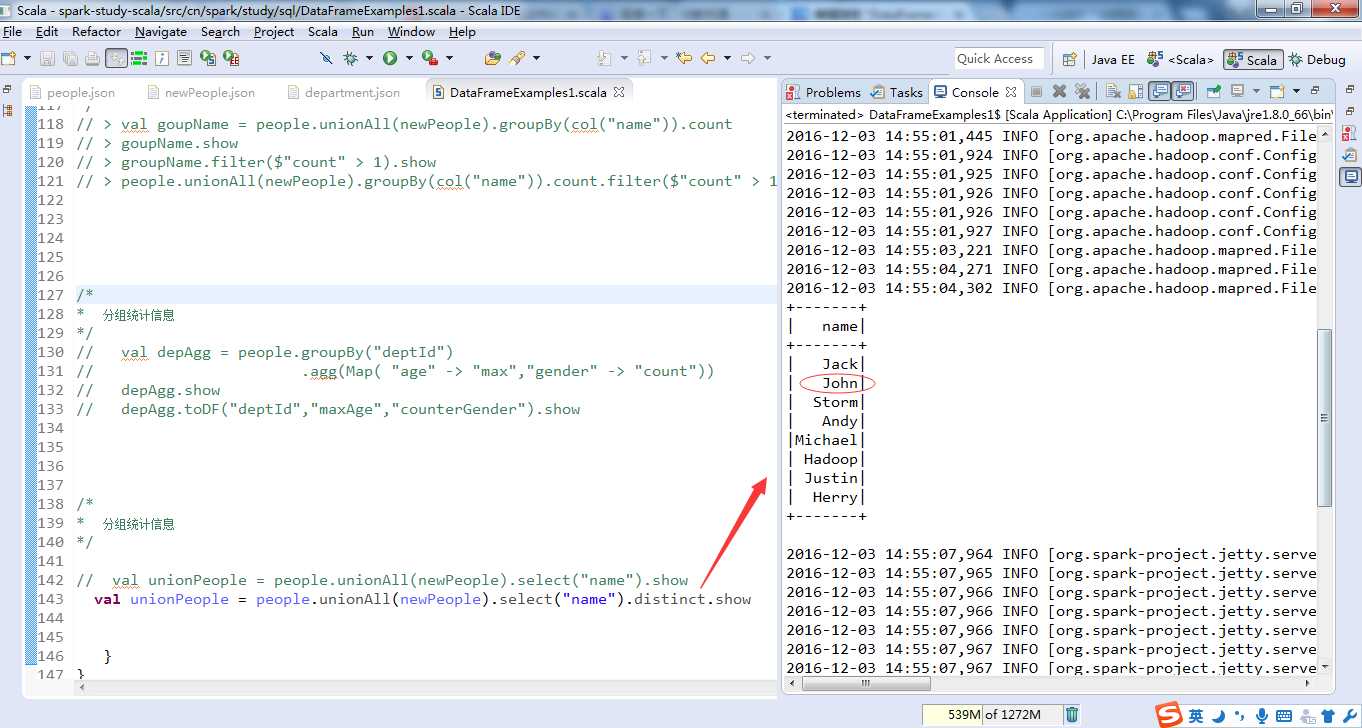
名字去重
标签:本地 job span 常用操作 等级 apache 令行 ack 比较
原文地址:http://www.cnblogs.com/zlslch/p/6128353.html