标签:style blog http color io strong for ar
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <stdlib.h>
#include "cublas_v2.h"
#define BLOCK_SIZE 16
/***************/
用cuBlas的内置函数API,cublasSgemm
cudaError_t multiWithcuBlase(float *c, float *a, float *b, unsigned int aH, unsigned int aW, unsigned int bH, unsigned int bW);
{
………………
cublasHandle_t handle;
cublasStatus_t ret;
ret = cublasCreate(&handle);
const float alpha = 1.0f;
const float beta = 0.0f;
ret = cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, aH, bW, aW, &alpha, gpu_a, aH, gpu_b, bH, &beta, gpu_c, aH);
………………
}
/***************/
用shared内存辅助
__global__ void multiKernel(float *c, float *a, float*b, unsigned int aW, unsigned int bW)
{
int xBlock = blockIdx.x;
int yBlock = blockIdx.y;
int xThread = threadIdx.x;
int yThread = threadIdx.y;
unsigned int aWidth = aW;
unsigned int bWidth = bW;
float Cvalue= 0;
for(int i=0; i< aWidth/BLOCK_SIZE; ++i)
{
__shared__ int aSub[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int bSub[BLOCK_SIZE][BLOCK_SIZE];
aSub[yThread][xThread] = a[(yBlock*blockDim.y + yThread)*aWidth + i*blockDim.x + xThread];
bSub[yThread][xThread] = b[(i*blockDim.y + yThread)*bWidth + xBlock*blockDim.x + xThread];
__syncthreads();
for(int e=0; e<BLOCK_SIZE; ++e)
{
Cvalue += aSub[yThread][e]*bSub[e][xThread];
}
__syncthreads();
}
int cIndex = (yBlock*blockDim.y + yThread)*bWidth + xBlock*blockDim.x + xThread;
c[cIndex] = Cvalue;
}
/***************/
用shared内存辅助,并将循环打开
__global__ void multiKernel_NoLoop(float *c, float *a, float*b, unsigned int aW, unsigned int bW)
{
int xBlock = blockIdx.x;
int yBlock = blockIdx.y;
int xThread = threadIdx.x;
int yThread = threadIdx.y;
unsigned int aWidth = aW;
unsigned int bWidth = bW;
float Cvalue= 0;
for(int i=0; i< aWidth/BLOCK_SIZE; ++i)
{
__shared__ int aSub[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int bSub[BLOCK_SIZE][BLOCK_SIZE];
aSub[yThread][xThread] = a[(yBlock*blockDim.y + yThread)*aWidth + i*blockDim.x + xThread];
bSub[yThread][xThread] = b[(i*blockDim.y + yThread)*bWidth + xBlock*blockDim.x + xThread];
__syncthreads();
Cvalue += aSub[yThread][0]*bSub[0][xThread] + aSub[yThread][1]*bSub[1][xThread] + \
aSub[yThread][2]*bSub[2][xThread] + aSub[yThread][3]*bSub[3][xThread] + \
aSub[yThread][4]*bSub[4][xThread] + aSub[yThread][5]*bSub[5][xThread] + \
aSub[yThread][6]*bSub[6][xThread] + aSub[yThread][7]*bSub[7][xThread] + \
aSub[yThread][8]*bSub[8][xThread] + aSub[yThread][9]*bSub[9][xThread] + \
aSub[yThread][10]*bSub[10][xThread] + aSub[yThread][11]*bSub[11][xThread] + \
aSub[yThread][12]*bSub[12][xThread] + aSub[yThread][13]*bSub[13][xThread] + \
aSub[yThread][14]*bSub[14][xThread] + aSub[yThread][15]*bSub[15][xThread] ;
__syncthreads();
}
int cIndex = (yBlock*blockDim.y + yThread)*bWidth + xBlock*blockDim.x + xThread;
c[cIndex] = Cvalue;
}
矩阵大小:320*320:
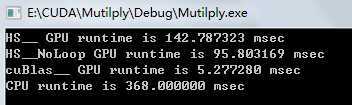
512*512:
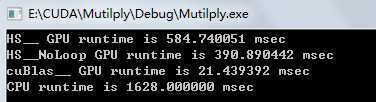
ps 机器太差没办法
标签:style blog http color io strong for ar
原文地址:http://www.cnblogs.com/huangshan/p/3916905.html