标签:read compile 重复 ror urlopen one perror 包管理 包管理器
一 安装BeautifulSoup
安装Python的包管理器pip 然后运行
$pip3 install beautifulsoup
在终端里导入它测试下是否安装成功
>>>from bs import BeautifulSoup
如果没有错误,说明导入成功了
简单例子 http://sc.chinaz.com/biaoqing/baozou.html 爬取图片
代码如下
from urllib.request import urlopen
from urllib.error import HTTPError,URLError
from bs4 import BeautifulSoup
import re
import warnings
warnings.filterwarnings("ignore")
def getTitle(url):
list =[];
try:
html=urlopen(url);
except (HTTPError,URLError) as e:
return None;
try:
bsObj = BeautifulSoup(html)
a=bsObj.findAll("img",{"src":re.compile("http:\/\/.*jpg|png|jpeg|tiff|raw|bmp|gig")});
for i in a:
if i[‘src‘]!="":
list.append(i[‘src‘]);
except AttributeError as e:
return None;
return list;
# a=getTitle(url)
# print(a)
def getHread(is_urls):
list=[];
try:
html = urlopen(is_urls);
except (HTTPError, URLError) as e:
return None;
try:
bsObj = BeautifulSoup(html)
tables=bsObj.findAll("a")
for i in tables:
if "href" in i.attrs:
list.append(i.attrs[‘href‘]);
#print(getTitle(i.attrs[‘href‘]));
temp=set(list);
for d in temp:
print(getTitle(d));
except AttributeError as e:
return None;
#return list;
is_ulrs="http://sc.chinaz.com/biaoqing/baozou.html";
a=getHread(is_ulrs)
print(a)
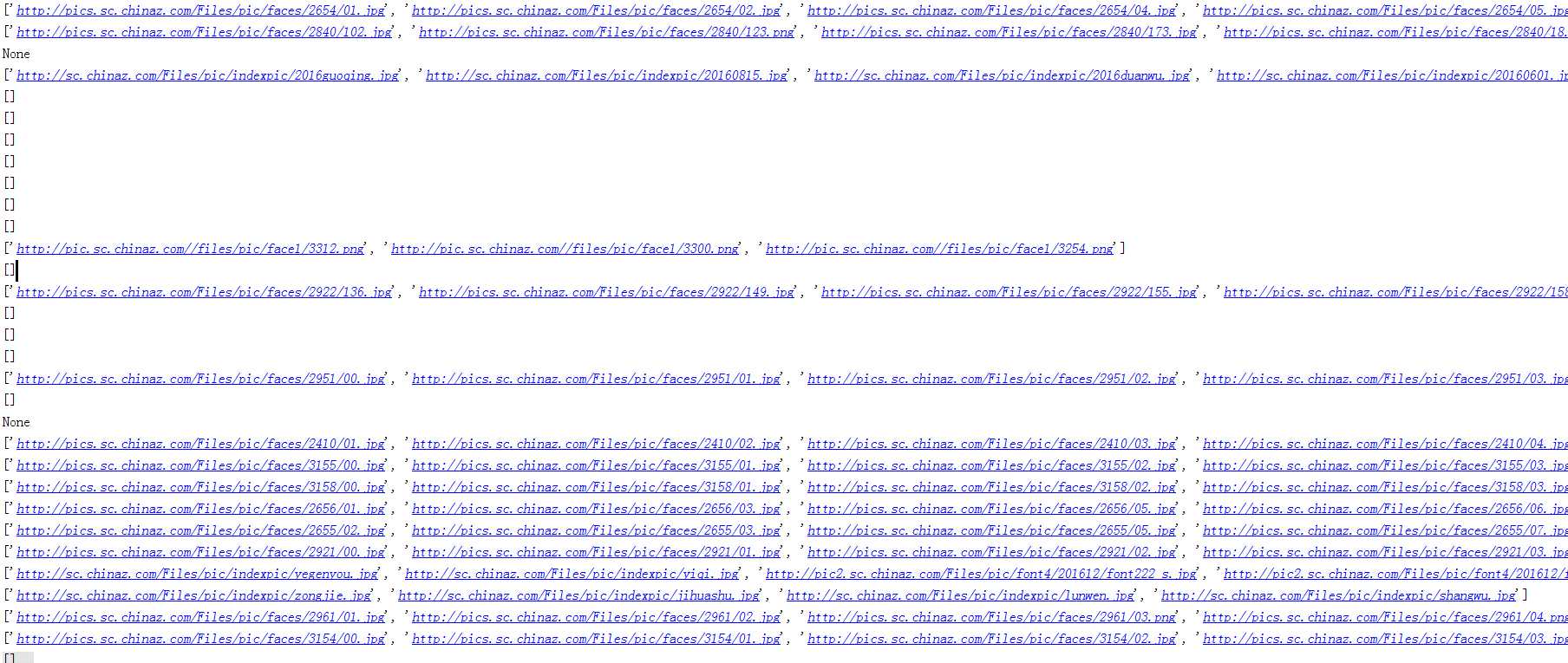
##################运行结果******************************
没有具体需求 只是简单的例子 只是处理了重复返回的图片用到set集合 运行的速度有点慢 没有时间优化 等有时间一定好好写写。
标签:read compile 重复 ror urlopen one perror 包管理 包管理器
原文地址:http://www.cnblogs.com/wxc1/p/6130079.html