标签:height 数据结构 情况 子集 lin 连接 搜索 相关 挖掘
关联规则:评定规则的标准
支持度:规则前项LHS和规则后项RHS所包括的商品都同时出现的概率,LHS和RHS商品的交易次数/总交易次数。
置信度:在所有的购买了左边商品的交易中,同时又购买了右边商品的交易机率,包含规则两边商品的交易次数/包括规则左边商品的交易次数。
提升度(有这个规则和没有这个规则是否概率会提升,规则是否有价值):无任何约束的情况下买后项的交易次数/置信度。提升度必须大于1才有意义。
一、Aprioir
多遍数据库扫描是昂贵的,挖掘长模式需要很多遍扫描,并产生大量候选。Aprioir具有的性质:频繁项集的所有非空子集也必须是频繁的。
首先找频繁一项集(满足最小支持度要求的项集),在频繁一项集的基础上寻找频繁二项集,再依次寻找频繁三、四等等,直到没有满足最小支持度的项集。
再根据频繁项集产生关联规则。频繁项集的非空子集计算置信度,在一定置信度的情况下保留下来相应有用的规则。
Aprioir算法本来orange2.7算法可以实现,不知道为什么orange3给取消了这个算法
二、FP-Growth
FP-growth算法不同于Apriori算法生成候选项集再检查是否频繁的“产生-测试” 方法,而是使用一种称为频繁模式树(FP-Tree,PF代表频繁模式,Frequent Pattern)菜单紧凑数据结构组织数据,并直接从该结构中提取频繁项集。每个事务被映射到FP-tree的一条路径上,不同的事务会有相同的路径,因此重叠的越多,压缩效果越好。
FP-growth算法分为两个过程,一是根据原始数据构造FP-Tree,
首先扫描一遍数据集,找出频繁项的列表L,并且按照支持度排序,根据此排序调整原数据中事务的排序。然后开始构造FP-tree,根节点为空,处理每个事物时按照L中的顺序将事物中出现的频繁项添加到中的一个分支。(下图中D是通过指针连接上的,这样后期搜索时候,是直接知道D出现两次的)
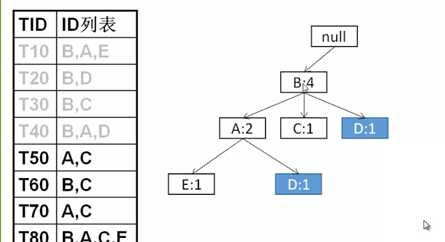
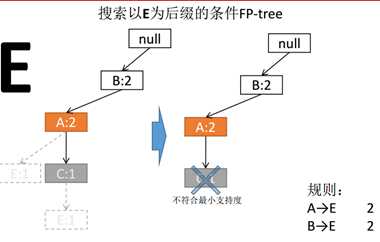
构造完成FP-Tree后,选定叶节点,收集所有包含叶节点的前缀路径,通过把与叶节点相关联的支持度计数相加,得到叶节点的支持度计数,从而产生满足最小支持度的规则。
标签:height 数据结构 情况 子集 lin 连接 搜索 相关 挖掘
原文地址:http://www.cnblogs.com/fionacai/p/6131495.html