标签:style blog http color os io strong for
测试环境
测试的GPU平台为GTX660M,计算能力为3.0
首先介绍一下GPU提供的函数:
int printf(const char *format[, arg, ...]);
从核函数格式化输出到主机,只支持计算能力在2.x及以上的设备。行为与标准的C相似。这里我们用于输出内建变量的值。
核函数调用方式
kernel<<<Dg, Db, Ns, S >>>
其中,Dg,类型为dim3,表示grid的每一维大小,计算能力为1.x的Dg.z等于1。表示加载的block数量为Dg各维的乘积。
Db也是Dim3类型,表示为每个block的每一维带下,表示每个block中线程的数量,等于Db各维的乘积。
Ns为每个Block的共享内存的大小,单位为字节。是一个可选的参数,默认为0。
S类型为cudaStream_t,表示相关的流。是一个可选的参数,默认为0。
CUDA内建的变量有:
内建变量的限制
从计算能力3.0的相关硬件描述可以找到以下限制:
下面我们先搞清楚不同的grid和block大小对CUDA内建的变量的影响
代码如下,grid为(2,3,1),而block大小为(2,2,1):
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> __global__ void MyKernel() { printf("(%d,%d,%d) (%d, %d, %d) (%d, %d, %d) (%d, %d, %d) %d\n", gridDim.x, gridDim.y, gridDim.z, blockDim.x, blockDim.y, blockDim.z, blockIdx.x, blockIdx.y, blockIdx.z, threadIdx.x, threadIdx.y, threadIdx.z, warpSize); } int main() { cudaError_t cudaStatus; // Choose which GPU to run on, change this on a multi-GPU system. cudaStatus = cudaSetDevice(0); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?"); } printf("gridDim | blockDim | blockIdx | threadIdx | warpSize\n"); dim3 gridSize(2, 3, 1); dim3 blockSize(2, 2, 1); // Launch a kernel on the GPU with one thread for each element. MyKernel<<<gridSize, blockSize>>>(); // Check for any errors launching the kernel cudaStatus = cudaGetLastError(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus)); } // cudaDeviceSynchronize waits for the kernel to finish, and returns // any errors encountered during the launch. cudaStatus = cudaDeviceSynchronize(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus); } // cudaDeviceReset must be called before exiting in order for profiling and // tracing tools such as Nsight and Visual Profiler to show complete traces. cudaStatus = cudaDeviceReset(); if (cudaStatus != cudaSuccess) { fprintf(stderr, "cudaDeviceReset failed!"); return 1; } return 0; }
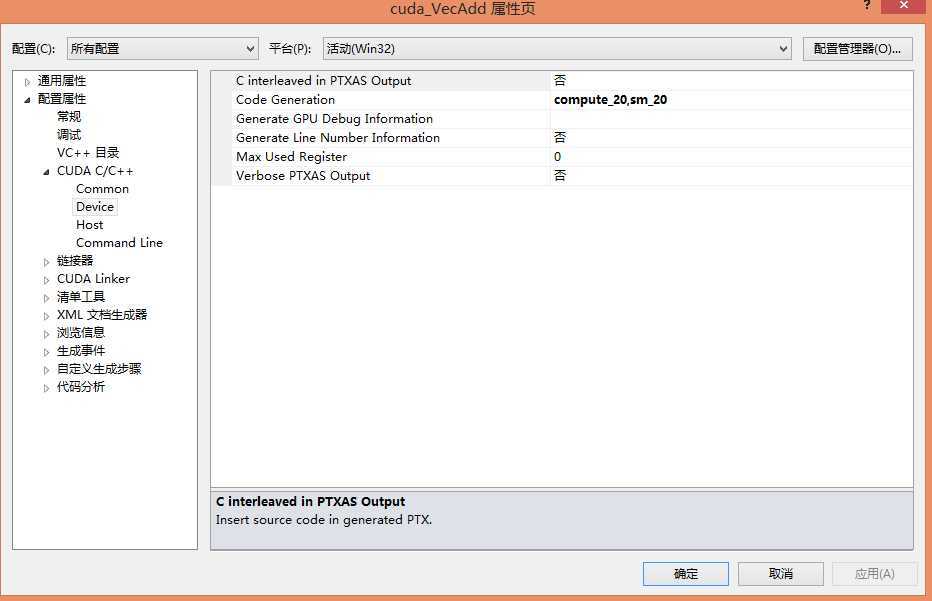
注意:需要设置CUDA代码生成的选项:
执行的结果如下:
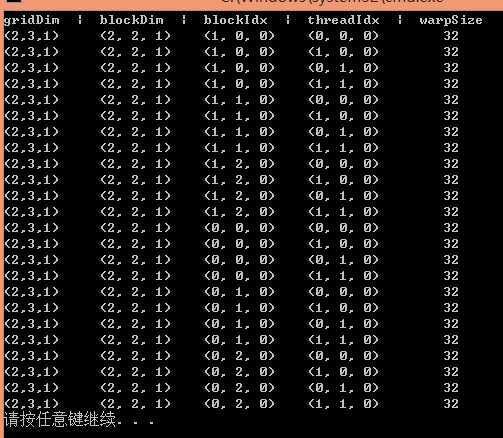
说明调用核函数输入的第一个参数设置gridDim,第二个设置blockDim,然后gridDim影响blockIdx的索引值,blockDim影响threadIdx索引值,warpSize大小为32。
CUDA C编程入门-不同的grid和block大小对CUDA内建的变量的影响,以及如何确定Thread ID,布布扣,bubuko.com
CUDA C编程入门-不同的grid和block大小对CUDA内建的变量的影响,以及如何确定Thread ID
标签:style blog http color os io strong for
原文地址:http://www.cnblogs.com/zjwzcnjsy/p/3917162.html