标签:blog http 使用 strong 文件 数据 ar 2014
以前没有写过,这是第一次写,用词不当,表述不清楚的地方请见谅。希望大家多提建议,谢谢。
网络爬虫常常被人所忽略,特别是和搜索引擎的光环相比,它似乎有些暗淡无光。我很少看见有详细介绍爬虫实现的文章或者文档。然而,爬虫其实是非常重要的一个系统,特别是在今天这个数据为王的时代。如果你是一个刚刚开始的公司或者项目,没有任何原始的数据积累,那么通过爬虫去Internet上找到那些有价值的数据再进行数据的清洗和整理,是一个可以快速得到数据的重要手段。
本文侧重于爬虫的系统设计和实现的部分细节,内容来源于三方面,一是我2013年3月份到10月份的一个数据采集的项目,对数据的要求是普通PC单机日下载量不少于80万个有效页面,第二则是来源于大量的网络资料作参考,因为当时的公司的保密性不是很高,我们在开发的过程中遇到问题随时可以求助网络,然而我使用最多的是Google搜索和 http://stackoverflow.com/ 网站是我去的最多的地方,第三则是最近看的一本在华为公司的角落里存放很久的一本书《数学之美》。大部分关于爬虫的系统方面的文献都是2000年左右的,此后寥寥无几,说明关于爬虫的系统设计在十几年前已经基本解决了。此外,既然本文侧重于系统方面的问题,那么某些内容就不会涉及,比如如何抓取那些隐藏的web数据,如何抓取ajax的页面,如何动态调整抓取频率等等。
正文
一个正规的,完整的网络爬虫其实是一个很复杂的系统:首先,它是一个海量数据处理系统,因为它所要面对的是整个互联网的网页,即便是一个小型的,垂直类的爬虫,一般也需要抓取上十亿或者上百亿的网页;其次,它也是一个对性能要求很好的系统,可能需要同时下载成千上万的网页,快速的提取网页中的url,对海量的url进行去重,等等;最后,它确实是一个不面向终端用户的系统,所以,虽然也很需要稳定性,但偶然的当机并不会是灾难,而且,不会出现类似访问量激增这样的情况,同时,如果短暂的时间内出现性能的下滑也不算是个问题,从这一点来看,爬虫的系统设计在某些部分又变得简单了许多。
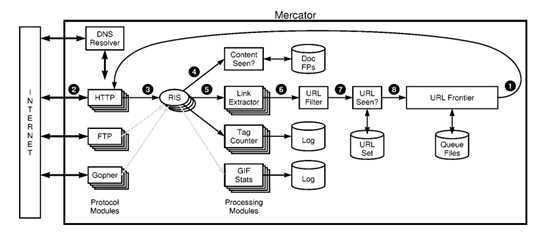
上图是一个爬虫的系统框架,它基本上包括了一个爬虫系统所需要的所有模块。
任何一个爬虫系统的设计图,会发现都有一个环路,这个环代表着爬虫大致的工作流程:根据URL将对应的网页下载下来,然后提取出网页中包含的URL,再根据这些新的URL下载对应的网页,周而复始。爬虫系统的子模块都位于这个环路中,并完成某项特定的功能。
这些子模块一般包括:
Fetcher:用于根据url下载对应的网页;
DNS Resolver:DNS的解析;
Content Seen:网页内容的去重;
Extractor:提取网页中的url或者其它的一些内容;
URL Filter:过滤掉不需要下载的url;
URL Seen:url的去重;
URL Set:存储所有的url;
URL Frontier:调度器,决定接下来哪些下载哪些url对应的网页;
Fetcher和DNS Resolver
这两个模块是两个非常简单的独立的服务:DNS Resolver负责域名的解析;Fetcher的输入是域名解析后的url,返回的则是该url对应的网页内容。对于任何一次网页的抓取,它都需要调用这两个模块。
对一般的爬虫,两个模块可以做得非常的简单,甚至合并到一起。但是对于性能要求很高的系统,它们可能成为潜在的性能瓶颈。主要原因是无论是域名解析还是抓取,都是很耗时的工作。比如抓取网页,一般的延迟都在百毫秒级别,如果遇上慢的网站,可能要几秒甚至十几秒,这导致工作线程会长时间的处于阻塞等待的状态。如果希望Fetcher能够达到每秒几千个网页甚至更高的下载,就需要启动大量的工作线程。
因此,对于性能要求高的爬虫系统,一般会采用epoll或者类似的技术将两个模块改成异步机制。另外,对于DNS的解析结果也会缓存下来,大大降低了DNS解析的操作。
Content Seen
Internet上的一些站点常常存在着镜像网站(mirror),即两个网站的内容一样但网页对应的域名不同。这样会导致对同一份网页爬虫重复抓取多次。为了避免这种情况,对于每一份抓取到的网页,它首先需要进入Content Seen模块。该模块会判断网页的内容是否和已下载过的某个网页的内容一致,如果一致,则该网页不会再被送去进行下一步的处理。这样的做法能够显著的降低爬虫需要下载的网页数。
至于如果判断两个网页的内容是否一致,一般的思路是这样的:并不会去直接比较两个网页的内容,而是将网页的内容经过计算生成FingerPrint(信息指纹),通常FingerPrint是一个固定长度的字符串,要比网页的正文短很多。如果两个网页的FingerPrint一样,则认为它们内容完全相同。
Extractor和Url Filter
Extractor的工作是从下载的网页中将它包含的所有url提取出来。这是个细致的工作,你需要考虑到所有可能的url的样式,比如网页中常常会包含相对路径的url,提取的时候需要将它转换成绝对路径。
Url Filter则是对提取出来的url再进行一次筛选。不同的应用筛选的标准是不一样的,比如对于baidu/google的搜索,一般不进行筛选,但是对于垂直搜索或者定向抓取的应用,那么它可能只需要满足某个条件的url,比如不需要图片的url,比如只需要某个特定网站的url等等。Url Filter是一个和应用密切相关的模块。
Url Seen
Url Seen用来做url去重。关于url去重之后会介绍,这里就不再详谈了。
对于一个大的爬虫系统,它可能已经有百亿或者千亿的url,新来一个url如何能快速的判断url是否已经出现过非常关键。因为大的爬虫系统可能一秒钟就会下载几千个网页,一个网页一般能够抽取出几十个url,而每个url都需要执行去重操作,可想每秒需要执行大量的去重操作。因此Url Seen是整个爬虫系统中非常有技术含量的一个部分。(Content Seen其实也存在这个问题)
Url Set
当url经过前面的一系列处理后就会被放入到Url Set中等待被调度抓取。因为url的数量很大,所以只有一小部分可能被放在内存中,而大部分则会写入到硬盘。一般Url Set的实现就是一些文件或者是数据库。
URL Frontier
URL Frontier之所以放在最后,是因为它可以说是整个爬虫系统的引擎和驱动,组织和调用其它的模块。
当爬虫启动的时候,Froniter内部会有一些种子url,它先将种子url送入Fetcher进行抓取,然后将抓取下来的网页送入Extractor提取新的url,再将新的url去重后放入到Url Set中;而当Froniter内部的url都已经抓取完毕后,它又从Url Set中提取那些新的没有被抓取过的url,周而复始。Frontier的调度实现有很多种,这里只介绍最常见的一种实现方法。
在此之前,需要先解释一点,尽管在介绍Fetcher的时候我们说,好的Fetcher每秒能够下载百千个网页,但是对于某个特定的目标网站,比如www.sina.com,爬虫系统对它的抓取是非常慢速的,十几秒才会抓取一次,这是为了保证目标网站不至于被爬虫给抓垮。
为了做到这一点,Frontier内部对于每个域名有一个对应的FIFO队列,这个队列保存了该域名下的url。Frontier每次都会从某个队列中拿出一个url进行抓取。队列会保存上一次被Frontier调用的时间,如果该时间距离现在已经超过了一定值,那么该队列才可以再次被调用。
Frontier内部同时可能拥有成千上万个这样的队列,它会轮询的获取一个可以被调用的队列,然后从该队列中pull一个url进行抓取。而一旦所有队列中的url被消耗到一定程度,Frontier又会从Url Set中提取一批新的url放入对应的队列。
分布式
当单机版的爬虫性能不能满足要求的时候,就应该考虑用多台机器组成分布式的爬虫系统。分布式的爬虫架构其实要比想象的简单得多,一个朴素的做法是:假设有N台机器,每台机器上有运行了一个完整的爬虫系统,每台机器的爬虫在从Extractor模块获得新的url之后,根据url的域名进行hash然后取模N得到结果n,然后该url会被放入第n台机器的Url Set中。这样,不同网站的url会被放在不同的机器上处理。
当时我们设计之处的目标是把爬虫程序放到路由器这样的设备上也可以正常、稳定的运行,因为不需要再设备上存放没用的信息,所有的有用页面通过socket通信被存放到指定的服务器中。但当我离开公司的时候,这个方案已经没有人再提到了,因为我们发现这样的做法,我们没有硬件支持,而且影响了路由器的运行速度。
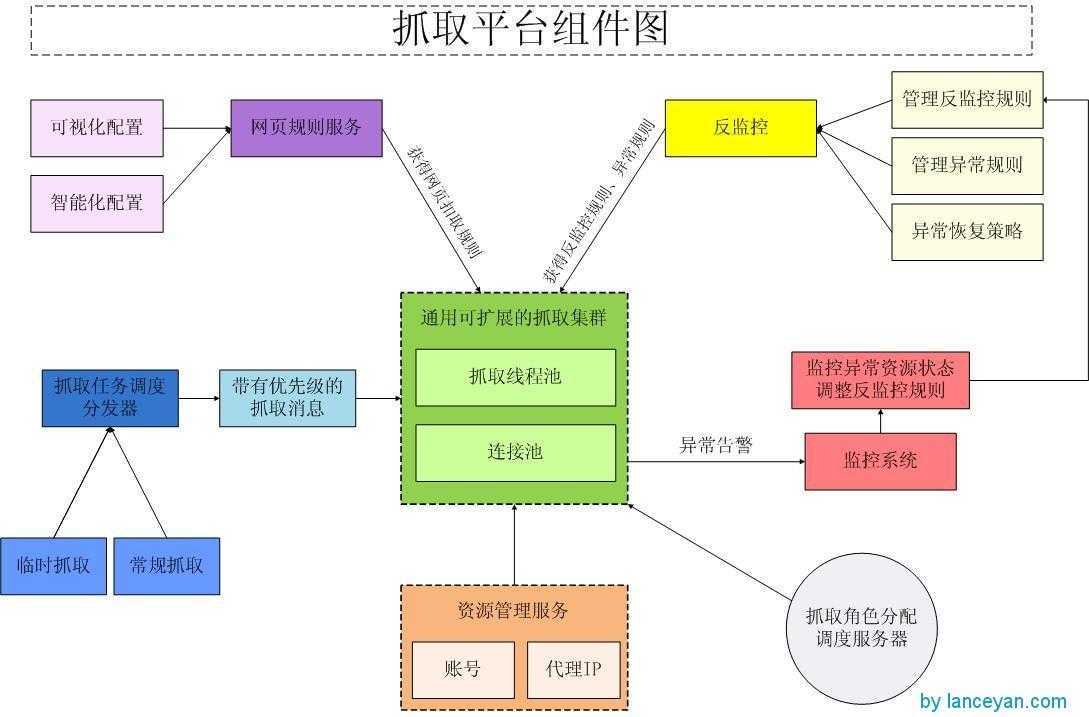
以上就是一个完整爬虫的系统实现。当然,由于篇幅有限回避了一些细节。比如爬虫抓取每个网站前需要先读取该网站的robots.txt来判断该网站是否允许被抓取(关于robots.txt的一下解释可以参考http://www.cnblogs.com/yuzhongwusan/archive/2008/12/06/1348969.html);再比如,一些网站提供了sitemap,这样可以直接从sitemap上获取该网站的所有url;等等。还有一张来自网络的抓取平台的结构图,这个图的结构和上面的那张图的结构基本相同。
反思自己一年前做数据采集的经过——网络爬虫,布布扣,bubuko.com
标签:blog http 使用 strong 文件 数据 ar 2014
原文地址:http://www.cnblogs.com/stlong/p/3917206.html