标签:des style blog http color 使用 os io
上一节分析了Job由JobClient提交到JobTracker的流程,利用RPC机制,JobTracker接收到Job ID和Job所在HDFS的目录,够早了JobInProgress对象,丢入队列,另一个线程从队列中取出JobInProgress对象,并丢入线程池中执行,执行JobInProgress的initJob方法,我们逐步分析。
public void initJob(JobInProgress job) { if (null == job) { LOG.info("Init on null job is not valid"); return; } try { JobStatus prevStatus = (JobStatus)job.getStatus().clone(); LOG.info("Initializing " + job.getJobID()); job.initTasks(); // Inform the listeners if the job state has changed // Note : that the job will be in PREP state. JobStatus newStatus = (JobStatus)job.getStatus().clone(); if (prevStatus.getRunState() != newStatus.getRunState()) { JobStatusChangeEvent event = new JobStatusChangeEvent(job, EventType.RUN_STATE_CHANGED, prevStatus, newStatus); synchronized (JobTracker.this) { updateJobInProgressListeners(event); } } } catch (KillInterruptedException kie) { // If job was killed during initialization, job state will be KILLED LOG.error("Job initialization interrupted:\n" + StringUtils.stringifyException(kie)); killJob(job); } catch (Throwable t) { String failureInfo = "Job initialization failed:\n" + StringUtils.stringifyException(t); // If the job initialization is failed, job state will be FAILED LOG.error(failureInfo); job.getStatus().setFailureInfo(failureInfo); failJob(job); } }
可以看出,先进行 job.initTasks(),初始化Map和Reduce任务,之后更新所有
synchronized (JobTracker.this) { updateJobInProgressListeners(event); }
Map/Reduce Task初始化完毕是一个事件,下面的代码进行消息通知:
// Update the listeners about the job // Assuming JobTracker is locked on entry. private void updateJobInProgressListeners(JobChangeEvent event) { for (JobInProgressListener listener : jobInProgressListeners) { listener.jobUpdated(event); } }
可见,在Job放入队列时使用的是jobAdded,此时使用的是jobUpdated。我们在后面再分析jobUpdated后的细节,此时先分析从jobAdded到jobUpdated之间,Job的初始化过程,主要分为几个阶段。
首先执行的是获取Split信息,这一部分信息事先已经由JobClient上传至HDFS中。
1、读取Split信息:
// // read input splits and create a map per a split // TaskSplitMetaInfo[] splits = createSplits(jobId); if (numMapTasks != splits.length) { throw new IOException("Number of maps in JobConf doesn‘t match number of " + "recieved splits for job " + jobId + "! " + "numMapTasks=" + numMapTasks + ", #splits=" + splits.length); } numMapTasks = splits.length;
createSplits方法的代码为:
TaskSplitMetaInfo[] createSplits(org.apache.hadoop.mapreduce.JobID jobId) throws IOException { TaskSplitMetaInfo[] allTaskSplitMetaInfo = SplitMetaInfoReader.readSplitMetaInfo(jobId, fs, jobtracker.getConf(), jobSubmitDir); return allTaskSplitMetaInfo; }
即读取job.splitmetainfo文件,获得Split信息:
public static JobSplit.TaskSplitMetaInfo[] readSplitMetaInfo( JobID jobId, FileSystem fs, Configuration conf, Path jobSubmitDir) throws IOException { long maxMetaInfoSize = conf.getLong("mapreduce.jobtracker.split.metainfo.maxsize", 10000000L); Path metaSplitFile = JobSubmissionFiles.getJobSplitMetaFile(jobSubmitDir); FileStatus fStatus = fs.getFileStatus(metaSplitFile); if (maxMetaInfoSize > 0 && fStatus.getLen() > maxMetaInfoSize) { throw new IOException("Split metadata size exceeded " + maxMetaInfoSize +". Aborting job " + jobId); } FSDataInputStream in = fs.open(metaSplitFile); byte[] header = new byte[JobSplit.META_SPLIT_FILE_HEADER.length]; in.readFully(header); if (!Arrays.equals(JobSplit.META_SPLIT_FILE_HEADER, header)) { throw new IOException("Invalid header on split file"); } int vers = WritableUtils.readVInt(in); if (vers != JobSplit.META_SPLIT_VERSION) { in.close(); throw new IOException("Unsupported split version " + vers); } int numSplits = WritableUtils.readVInt(in); //TODO: check for insane values JobSplit.TaskSplitMetaInfo[] allSplitMetaInfo = new JobSplit.TaskSplitMetaInfo[numSplits]; final int maxLocations = conf.getInt(JobSplitWriter.MAX_SPLIT_LOCATIONS, Integer.MAX_VALUE); for (int i = 0; i < numSplits; i++) { JobSplit.SplitMetaInfo splitMetaInfo = new JobSplit.SplitMetaInfo(); splitMetaInfo.readFields(in); final int numLocations = splitMetaInfo.getLocations().length; if (numLocations > maxLocations) { throw new IOException("Max block location exceeded for split: #" + i + " splitsize: " + numLocations + " maxsize: " + maxLocations); } JobSplit.TaskSplitIndex splitIndex = new JobSplit.TaskSplitIndex( JobSubmissionFiles.getJobSplitFile(jobSubmitDir).toString(), splitMetaInfo.getStartOffset()); allSplitMetaInfo[i] = new JobSplit.TaskSplitMetaInfo(splitIndex, splitMetaInfo.getLocations(), splitMetaInfo.getInputDataLength()); } in.close(); return allSplitMetaInfo; }
涉及读取文件的代码有:
FSDataInputStream in = fs.open(metaSplitFile); byte[] header = new byte[JobSplit.META_SPLIT_FILE_HEADER.length]; in.readFully(header);
这一部分先读取job.splitmetainfo文件的头部,头部实际上是字符串”META-SPL“,该信息由下面的类指定:
public class JobSplit { static final int META_SPLIT_VERSION = 1; static final byte[] META_SPLIT_FILE_HEADER; static { try { META_SPLIT_FILE_HEADER = "META-SPL".getBytes("UTF-8"); } catch (UnsupportedEncodingException u) { throw new RuntimeException(u); } } .......
读取了文件头之后,剩下的是读取版本信息:
int vers = WritableUtils.readVInt(in); if (vers != JobSplit.META_SPLIT_VERSION) { in.close(); throw new IOException("Unsupported split version " + vers); }
检查了版本(1)后,接下来就是读取Split的数量:
int numSplits = WritableUtils.readVInt(in); //TODO: check for insane values JobSplit.TaskSplitMetaInfo[] allSplitMetaInfo = new JobSplit.TaskSplitMetaInfo[numSplits];
并根据Split数量创建JobSplit.TaskSplitMetaInfo数组。接下来对于每个Split,循环读取位置等信息:
for (int i = 0; i < numSplits; i++) { JobSplit.SplitMetaInfo splitMetaInfo = new JobSplit.SplitMetaInfo(); splitMetaInfo.readFields(in); final int numLocations = splitMetaInfo.getLocations().length; if (numLocations > maxLocations) { throw new IOException("Max block location exceeded for split: #" + i + " splitsize: " + numLocations + " maxsize: " + maxLocations); } JobSplit.TaskSplitIndex splitIndex = new JobSplit.TaskSplitIndex( JobSubmissionFiles.getJobSplitFile(jobSubmitDir).toString(), splitMetaInfo.getStartOffset()); allSplitMetaInfo[i] = new JobSplit.TaskSplitMetaInfo(splitIndex, splitMetaInfo.getLocations(), splitMetaInfo.getInputDataLength()); }
在上面的代码中,splitMetaInfo.readFields(in)可以获得位置信息:
public void readFields(DataInput in) throws IOException { int len = WritableUtils.readVInt(in); locations = new String[len]; for (int i = 0; i < locations.length; i++) { locations[i] = Text.readString(in); } startOffset = WritableUtils.readVLong(in); inputDataLength = WritableUtils.readVLong(in); }
所谓的位置,实际上就是指这个Split在j哪些服务器的信息。获取到位置、Split数据长度等信息后,全部纪录在对象JobSplit.TaskSplitMetaInfo中:
JobSplit.TaskSplitIndex splitIndex = new JobSplit.TaskSplitIndex( JobSubmissionFiles.getJobSplitFile(jobSubmitDir).toString(), splitMetaInfo.getStartOffset()); allSplitMetaInfo[i] = new JobSplit.TaskSplitMetaInfo(splitIndex, splitMetaInfo.getLocations(), splitMetaInfo.getInputDataLength());
返回allSplitMetaInfo数组。
2、根据Map任务数量创建相同数量的TaskInProgress对象:
上面返回的数组大小即纪录了Split的个数,也决定了Map的数量,验证这些服务器的合法性:
numMapTasks = splits.length;
// Sanity check the locations so we don‘t create/initialize unnecessary tasks
for (TaskSplitMetaInfo split : splits) {
NetUtils.verifyHostnames(split.getLocations());
}
在监控相关类中设置相应信息:
jobtracker.getInstrumentation().addWaitingMaps(getJobID(), numMapTasks); jobtracker.getInstrumentation().addWaitingReduces(getJobID(), numReduceTasks); this.queueMetrics.addWaitingMaps(getJobID(), numMapTasks); this.queueMetrics.addWaitingReduces(getJobID(), numReduceTasks);
接下来创建TaskInProgress对象,每个Map都对应于一个TaskInProgress对象:
maps = new TaskInProgress[numMapTasks]; for(int i=0; i < numMapTasks; ++i) { inputLength += splits[i].getInputDataLength(); maps[i] = new TaskInProgress(jobId, jobFile, splits[i], jobtracker, conf, this, i, numSlotsPerMap); }
TaskInProgress纪录了一个Map Task或Reduce Task运行相关的所有信息,类似于JobInProgress,TaskInProgress的构造函数有两个,分别针对Map和Reduce的,对于Map的:
/** * Constructor for MapTask */ public TaskInProgress(JobID jobid, String jobFile, TaskSplitMetaInfo split, JobTracker jobtracker, JobConf conf, JobInProgress job, int partition, int numSlotsRequired) { this.jobFile = jobFile; this.splitInfo = split; this.jobtracker = jobtracker; this.job = job; this.conf = conf; this.partition = partition; this.maxSkipRecords = SkipBadRecords.getMapperMaxSkipRecords(conf); this.numSlotsRequired = numSlotsRequired; setMaxTaskAttempts(); init(jobid); }
splitInfo纪录了当前Split的信息,partition即表示这是第几个Map Task,numSlotsRequired为1.
创建好的TaskInProgress将会放入缓存中:
if (numMapTasks > 0) { nonRunningMapCache = createCache(splits, maxLevel); }
nonRunningMapCache是一个未运行起来的Map任务的关于主机信息等等的缓存,其索引为Node,即服务器;而其值为TaskInProgress对象,其声明为,因此,实际上就是解析Split所在的服务器,缓存下来,供后续调度使用:
Map<Node, List<TaskInProgress>> nonRunningMapCache;
其方法代码为:
private Map<Node, List<TaskInProgress>> createCache( TaskSplitMetaInfo[] splits, int maxLevel) throws UnknownHostException { Map<Node, List<TaskInProgress>> cache = new IdentityHashMap<Node, List<TaskInProgress>>(maxLevel); Set<String> uniqueHosts = new TreeSet<String>(); for (int i = 0; i < splits.length; i++) { String[] splitLocations = splits[i].getLocations(); if (splitLocations == null || splitLocations.length == 0) { nonLocalMaps.add(maps[i]); continue; } for(String host: splitLocations) { Node node = jobtracker.resolveAndAddToTopology(host); uniqueHosts.add(host); LOG.info("tip:" + maps[i].getTIPId() + " has split on node:" + node); for (int j = 0; j < maxLevel; j++) { List<TaskInProgress> hostMaps = cache.get(node); if (hostMaps == null) { hostMaps = new ArrayList<TaskInProgress>(); cache.put(node, hostMaps); hostMaps.add(maps[i]); } //check whether the hostMaps already contains an entry for a TIP //This will be true for nodes that are racks and multiple nodes in //the rack contain the input for a tip. Note that if it already //exists in the hostMaps, it must be the last element there since //we process one TIP at a time sequentially in the split-size order if (hostMaps.get(hostMaps.size() - 1) != maps[i]) { hostMaps.add(maps[i]); } node = node.getParent(); } } } // Calibrate the localityWaitFactor - Do not override user intent! if (localityWaitFactor == DEFAULT_LOCALITY_WAIT_FACTOR) { int jobNodes = uniqueHosts.size(); int clusterNodes = jobtracker.getNumberOfUniqueHosts(); if (clusterNodes > 0) { localityWaitFactor = Math.min((float)jobNodes/clusterNodes, localityWaitFactor); } LOG.info(jobId + " LOCALITY_WAIT_FACTOR=" + localityWaitFactor); } return cache; }
3、根据Reduce任务数量创建相同数量的TaskInProgress对象:
代码和Map基本相同:
// // Create reduce tasks // this.reduces = new TaskInProgress[numReduceTasks]; for (int i = 0; i < numReduceTasks; i++) { reduces[i] = new TaskInProgress(jobId, jobFile, numMapTasks, i, jobtracker, conf, this, numSlotsPerReduce); nonRunningReduces.add(reduces[i]); }
4、计算Reduce任务启动前Map最少应该启动的数量:
根据MapReduce原理,先进行Map计算,之后中间结果再传递至Reduce计算,因此,Map要先进行计算,Reduce如果和Map一起启动,那么,Reduce必然先一直处于等待中。这会消耗机器资源,且Shuffle时间比较长。所以,这个值默认是Map所有任务数量的5%:
// Calculate the minimum number of maps to be complete before // we should start scheduling reduces completedMapsForReduceSlowstart = (int)Math.ceil( (conf.getFloat("mapred.reduce.slowstart.completed.maps", DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART) * numMapTasks)); // ... use the same for estimating the total output of all maps resourceEstimator.setThreshhold(completedMapsForReduceSlowstart);
从DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART可以看出,是5%:
private static float DEFAULT_COMPLETED_MAPS_PERCENT_FOR_REDUCE_SLOWSTART = 0.05f;
5、创建Map和Reduce任务的清理任务,各一个:
// create cleanup two cleanup tips, one map and one reduce. cleanup = new TaskInProgress[2]; // cleanup map tip. This map doesn‘t use any splits. Just assign an empty // split. TaskSplitMetaInfo emptySplit = JobSplit.EMPTY_TASK_SPLIT; cleanup[0] = new TaskInProgress(jobId, jobFile, emptySplit, jobtracker, conf, this, numMapTasks, 1); cleanup[0].setJobCleanupTask(); // cleanup reduce tip. cleanup[1] = new TaskInProgress(jobId, jobFile, numMapTasks, numReduceTasks, jobtracker, conf, this, 1); cleanup[1].setJobCleanupTask();
6、创建Map和Reduce任务的启动任务,各一个:
// create two setup tips, one map and one reduce. setup = new TaskInProgress[2]; // setup map tip. This map doesn‘t use any split. Just assign an empty // split. setup[0] = new TaskInProgress(jobId, jobFile, emptySplit, jobtracker, conf, this, numMapTasks + 1, 1); setup[0].setJobSetupTask(); // setup reduce tip. setup[1] = new TaskInProgress(jobId, jobFile, numMapTasks, numReduceTasks + 1, jobtracker, conf, this, 1); setup[1].setJobSetupTask();
7、Map/Reduce Task初始化完毕:
synchronized(jobInitKillStatus){ jobInitKillStatus.initDone = true; // set this before the throw to make sure cleanup works properly tasksInited = true; if(jobInitKillStatus.killed) { throw new KillInterruptedException("Job " + jobId + " killed in init"); } }
初始化完毕后,会通过jobUpdated进行通知。Job更新的事件主要有三种:
static enum EventType {RUN_STATE_CHANGED, START_TIME_CHANGED, PRIORITY_CHANGED}
此时初始化完毕属于RUN_STATE_CHANGED。从其代码来看,如果是运行状态改变,并不执行什么操作:
public synchronized void jobUpdated(JobChangeEvent event) { JobInProgress job = event.getJobInProgress(); if (event instanceof JobStatusChangeEvent) { // Check if the ordering of the job has changed // For now priority and start-time can change the job ordering JobStatusChangeEvent statusEvent = (JobStatusChangeEvent)event; JobSchedulingInfo oldInfo = new JobSchedulingInfo(statusEvent.getOldStatus()); if (statusEvent.getEventType() == EventType.PRIORITY_CHANGED || statusEvent.getEventType() == EventType.START_TIME_CHANGED) { // Make a priority change reorderJobs(job, oldInfo); } else if (statusEvent.getEventType() == EventType.RUN_STATE_CHANGED) { // Check if the job is complete int runState = statusEvent.getNewStatus().getRunState(); if (runState == JobStatus.SUCCEEDED || runState == JobStatus.FAILED || runState == JobStatus.KILLED) { jobCompleted(oldInfo); } } } }
因为此时Job并未结束。从此可以看出,Job在初始化完毕后,线程池又去执行其他Job的初始化等操作,等待TaskTracker来取。
关于TaskTracker与JobTracker之间的心跳,以及任务的获取等操作,比较复杂,留作后续博文分析。
后记
由流程图来看:
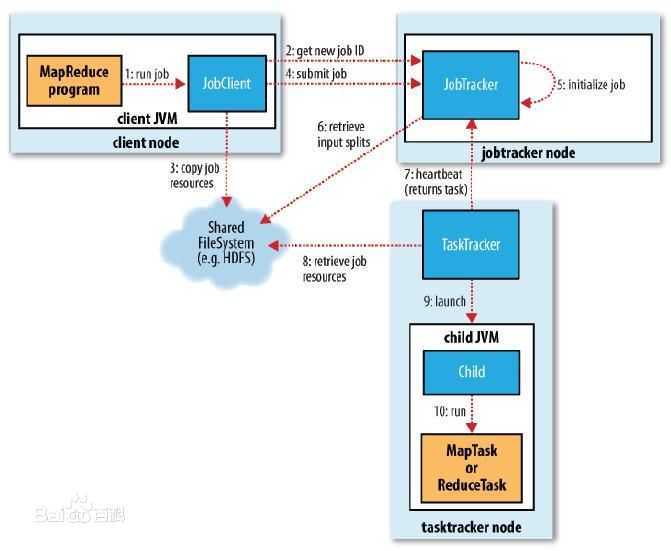
本博文在上一节分析了1、2、3、4的基础上,分析了5、6两个步骤,即Job的初始化、到HDFS中获取资源数据,获得Map和Reduce数量等过程。关于7、8、9、10等后续操作,在后续博文中分析。
MapReduce剖析笔记之三:Job的Map/Reduce Task初始化,布布扣,bubuko.com
MapReduce剖析笔记之三:Job的Map/Reduce Task初始化
标签:des style blog http color 使用 os io
原文地址:http://www.cnblogs.com/esingchan/p/3917252.html