标签:技术 使用 pre 查询 string div 有用 节点 util

authornamelist = soup.find_all(‘contrib‘) for x in authornamelist: print x.surname.text print x.surname.next_sibling.next_sibling.text
surname.next_sibling实际上是换行符,所有用换行符的next_sibling
直接print x.given-names.text 无法解析given-names这种格式的
参考文献
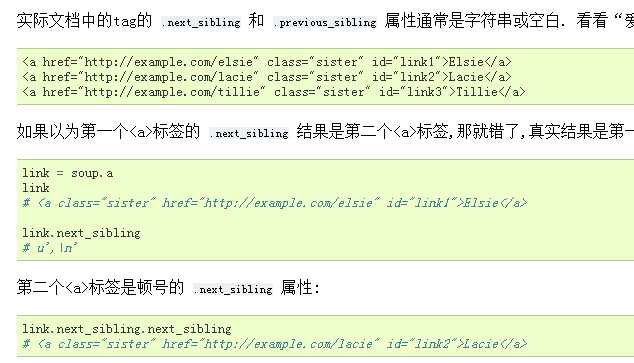
在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点:
sibling_soup.b.next_sibling
# <c>text2</c>
sibling_soup.c.previous_sibling
# <b>text1</b>
<b>标签有 .next_sibling 属性,但是没有 .previous_sibling 属性,因为<b>标签在同级节点中是第一个.同理,<c>标签有 .previous_sibling 属性,却没有.next_sibling 属性:
print(sibling_soup.b.previous_sibling)
# None
print(sibling_soup.c.next_sibling)
# None
例子中的字符串“text1”和“text2”不是兄弟节点,因为它们的父节点不同:
sibling_soup.b.string
# u‘text1‘
print(sibling_soup.b.string.next_sibling)
# None
标签:技术 使用 pre 查询 string div 有用 节点 util
原文地址:http://www.cnblogs.com/lovely7/p/6137063.html