标签:sig 老婆 问题 nal 这一 图像复原 好的 cga 预测
从另一个博客园上搬的东西宣传委员画了一个稿子:
好丑啊!
然后我想我要拿出自己的方案,不然没说服力。
于是花了两天找矢量素材。
接着放到班群里投票。

然而结果……
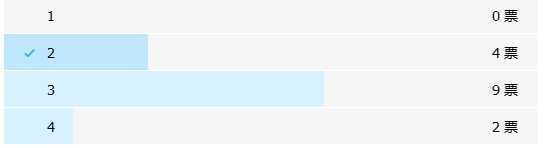
还有一个是投错的。想投3结果投了2.
在这里保存一下我的效果图。

全部是矢量图!!!我找了好久的!!!!
我作业都没做你造吗!!!
OI都没刷你造吗!!!
真·生无可恋。
又要拿来垫衣柜??????!!!!!
再见
再见
再见
再见




想更深入了解这个话题的同学,请移步霍老爷的文章《程序员爱写脚本是种病》:https://news.cnblogs.com/n/553596/
抢房子/工作/老婆那一段台词来自王渊命同学的吐槽,已获得改编授权,感谢隔壁老王。
神奇的黑魔法。

计算机视觉(Computer Vision,CV)是一门研究如何使机器“会看”的科学。1963 年来自 MIT 的 Larry Roberts 发表了该领域第一篇博士论文《Machine Perception of Three-Dimensional Solids》,标志着 CV 作为一门新兴人工智能方向研究的开始。在发展了 50 多年后的今天,我们就来聊聊最近让计算机视觉拥有“无中生有”能力的几个有趣尝试:
可以看出,这五个尝试层层递进,难度和趣味程度也逐步提升。由于篇幅有限,本文在此只谈视觉问题,不提太过具体的技术细节,若大家对某部分感兴趣,以后再来单独写文章讨论。
超分辨率重建(Image Super-Resolution)
去年夏天,一款名为“waifu 2x”的岛国应用在动画和计算机图形学中着实火了一把。waifu 2x 借助深度“卷积神经网络”(Convolutional Neural Network,CNN)技术,可以将图像的分辨率提升 2 倍,同时还能对图像进行降噪。简单来说,就是让计算机“无中生有”地填充一些原图中并没有的像素,从而让漫画看起来更清晰真切。大家不妨看看图1、图2,真想童年时候看的就是如此高清的龙珠啊!

图 1 《龙珠》超分辨率重建效果。右侧为原画,左侧为 waifu 2x 对同帧动画超分辨率重建结果

图 2 waifu 2x 超分辨率重建对比,上方为低分辨率且有噪声的动画图像,左下为直接放大的结果,右下为 waifu 2x 去噪和超分辨率结果
不过需要指出的是,图像超分辨率的研究始于 2009 年左右,只是得力于“深度学习”的发展,waifu 2x 才可以做出更好的效果。在具体训练 CNN 时,输入图像为原分辨率,而对应的超分辨率图像则作为目标,以此构成训练的“图像对”(Image Pair),经过模型训练便可得到超分辨率重建模型。waifu 2x 的深度网络原型基于香港中文大学汤晓欧教授团队的成果(如图 3 所示)。有趣的是,这一研究指出可以用传统方法给予深度模型以定性的解释。在图 3 中,低分辨率图像通过 CNN 的卷积(Convolution)和池化(Pooling)操作后可以得到抽象后的特征图(Feature Map)。基于低分辨率特征图,同样可以利用卷积和池化实现从低分辨率到高分辨率特征图的非线性映射(Non-Linear Mapping)。最后的步骤则是利用高分辨率特征图重建高分辨率图像。实际上,这三个步骤与传统超分辨率重建方法的三个过程是一致的。
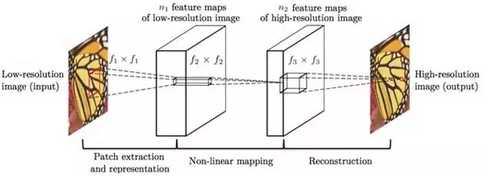
图 3 超分辨率重建算法流程。从左至右依次为:低分辨率图像(输入)、经过若干卷积和池化操作得到的低分辨率特征图、低分辨率特征图经过非线性映射得到的高分辨率特征图、高分辨率重建图像(输出)
图像着色(Image Colorization)
顾名思义,图像着色是将原本“没有”颜色的黑白图像进行彩色填充。图像着色同样借助卷积神经网络,输入为黑白和对应彩色图像的“图像对”,但仅仅通过对比黑白像素和 RGB 像素来确定填充的颜色,效果欠佳。因为颜色填充的结果要符合我们的认知习惯,比如,把一条“汪星人”的毛涂成鲜绿色就会让人觉得很怪异。于是近期,早稻田大学发表在 2016 年计算机图形学国际顶级会议 SIGGRAPH 上的一项工作就在原来深度模型的基础上,加入了“分类网络”来预先确定图像中物体的类别,以此为“依据”再做以颜色填充。图 4 就分别展示了模型结构图和颜色恢复示例,其恢复效果还是颇为逼真的。另外,此类工作还可用于黑白电影的颜色恢复,操作时只需简单将视频中逐帧拿来做着色即可。
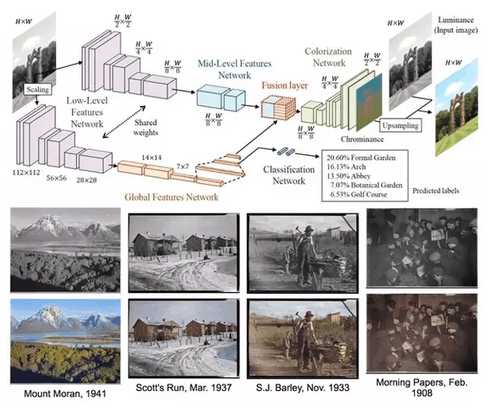
图 4 图像着色的深度学习网络结构和效果。输入黑白图像后即分为两支,上侧一支用于图像着色,下侧一支用于图像分类。在图中红色部分(Fusion layer),两支的深度特征信息进行融合,由于包含了分类网络特征,因此可以起到“用分类结果为依据辅助图像着色”的效果
看图说话(Image Caption)
人们常说“图文并茂”,文字是除图像之外另一种描述世界的方式。近期,一项名为“Image Caption”的研究逐渐升温起来,其主要目的是通过计算机视觉和机器学习的方法实现对一张图像自动地生成人类自然语言的描述,即“看图说话”。一般来讲,在 Image Caption 中,CNN 用来获取图像的特征,接着将图像特征作为语言模型 LSTM(RNN 的一种)的输入,整体作为一个 End-to-End 的结构进行联合训练,最终输出对图像的语言描述(如图 5 所示)。
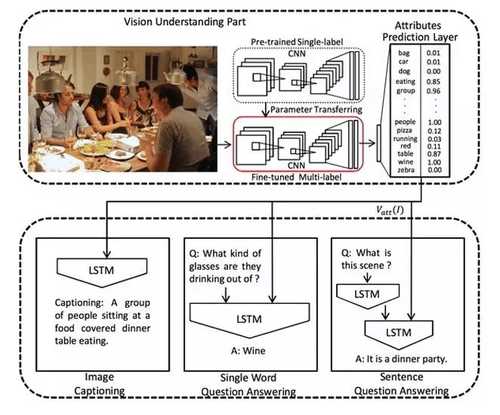
图 5 Image Caption 网络结构。图像作为输入,首先经过微调后的多标记(Multi-Label)分类网络得到预测的类别标签,并以此连同图像的深度特征作为下方语言模型 LSTM 的输入,最终进行联合训练。下图左一可完成 Image Caption 任务,左 2 为单个单词图像问答任务,右 1 为句子级别的图像问答任务
人像复原(Sketch Inversion)
就在六月初,荷兰科学家在 arXiv 上发布了他们的最新研究成果——通过深度网络对人脸轮廓图进行“复原”。如图 6 所示,在模型训练阶段,首先对真实的人脸图像利用传统的线下边缘化方法获得对应人脸的轮廓图,并以原图和轮廓图组成的“图像对”作为深度网络的输入,进行类似超分辨率重建的模型训练。在预测阶段,输入为人脸轮廓(左二 Sketch),经过卷积神经网络的层层抽象和后续的“还原”操作,可以逐步把相片般的人脸图像复原出来(右一),与最左边的人脸真实图像对比,足够以假乱真。在模型流程图下还另外展示了一些人像复原的结果,左侧一列为真实人像,中间列为画家手工描绘的人脸轮廓图,并以此作为网络输入进行人像复原,最终得到右侧一列的复原结果——目测以后刑侦警察再也不用苦练美术了。

图 6 人像复原算法流程及效果
图像自动生成
回顾刚才的四个工作,其实它们的共同点是仍然需要依靠一些“素材”方可“无中生有”,例如“人像复原”还是需要一个轮廓画才可以恢复人像。接下来的这个工作则可以做到由任意一条随机向量生成一张逼近真实场景的图像。
“无监督学习”可谓是计算机视觉领域的圣杯。最近该方向的一项开创性工作是由 Ian Goodfellow 和 Yoshua Bengio 等提出的“生成对抗网络”(Generative Adversarial Nets, GAN)。该工作的灵感来自博弈论中的零和博弈。在二元零和博弈中,两位博弈方的利益之和为零或一个常数,即一方有所得,另一方必有所失。而 GAN 中的两位博弈方分别由一个“判别式网络”和一个“生成式网络”充当,如图 7 所示。
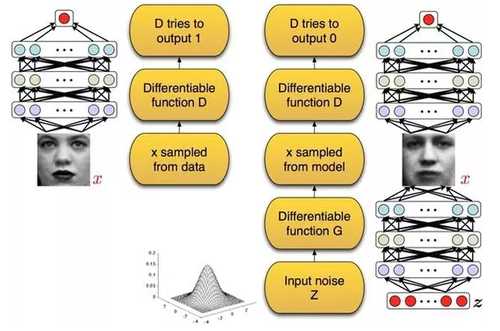
图 7 生成式网络和判别式网络
其中,“判别式网络”的输入为图像,其作用为判断一张图像是真实的,还是由计算机生成的像;“生成式网络”的输入为一条随机向量,可以通过网络“生成”一张合成图像。这张合成图像亦可作为“判别式网络”的输入,只是此时,在理想情况下应能判断出它是由计算机生成的。
接下来,GAN 中的零和博弈就发生在“判别式网络”和“生成式网络”上:“生成式网络”想方设法的让自己生成的图像逼近真实图像,从而可以“骗过”“判别式网络”;而“判别式网络”也时刻提高警惕,防止“生成式网络”蒙混过关……你来我往,如此迭代下去,颇有点“左右互搏”的意味。GAN 整个过程的最终目标是习得一个可以逼近真实数据分布的“生成式网络”,从而掌握整体真实数据的分布情况,因此取名“生成对抗网络”。需要强调的是,GAN 不再像传统的监督式深度学习那样需要海量带有类别标记的图像,它不需任何图像标记即可训练,也就是进行无监督条件下的深度学习。2016 年初,在 GAN 的基础上,Indico Research 和 Facebook AI 实验室将 GAN 用深度卷积神经网络进行实现(称作 DCGAN,Deep Convolutional GAN),工作发表在国际表示学习重要会议 ICLR 2016 上,并在无监督深度学习模型中取得了当时最好的效果。图 8 展示了一些由 DCGAN 生成的卧室图像。

图 8 DCGAN 生成的卧室图像
更为有趣的是,DCGAN 还可以像 word2vec 一样支持图像“语义”层面的加减(如图 9 所示)。

图 9 DCGAN“语义加减”示意
另外,前些天“生成式计算机视觉”研究领域大牛 UCLA 的 Song-Chun Zhu 教授团队发布了他们基于生成式卷积网络的最新工作 STGConvNet:它不仅可以自动合成动态纹理,同时还可以合成声音,可以说将无监督计算机视觉又向前推进了一大步。
结束语
如今借着“深度学习”的东风,计算机视觉中绝大多数任务的性能表现都被“刷”上了新高,甚至连“人像复原”,“图像生成”类似“无中生有”的奇谈都可以较高质量地实现,着实让人激动不已。不过尽管如此,事实上距离所谓的颠覆人类的 AI“奇点”还相当遥远,并且可以预见,现阶段甚至相当长的一段时间内,计算机视觉或人工智能还不可能做到真正意义上的“无中生有”——即拥有“自我意识”。
但是,也非常庆幸我们可以目睹并且经历这次计算机视觉乃至是整个人工智能的革命浪潮,相信今后还会有很多“无中生有”的奇迹发生。站在浪潮之巅,我兴奋不已、彻夜难眠。
标签:sig 老婆 问题 nal 这一 图像复原 好的 cga 预测
原文地址:http://www.cnblogs.com/yanhuihang/p/6140739.html