VHost
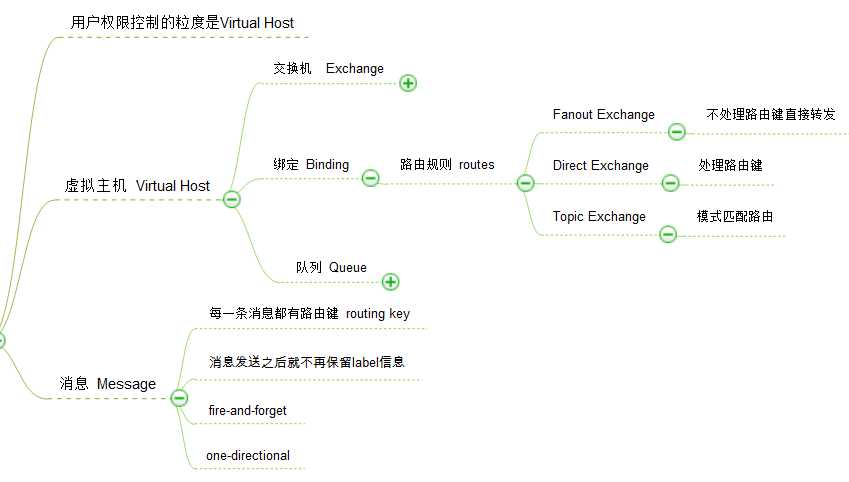
Vhosts也是AMQP的一个基础概念,连接到RabbitMQ默认就有一个名为"/"的vhost可用,本地调试的时候可以直接使用这个默认的vhost.这个"/"的访问可以使用guest用户名(密码guest)访问.可以使用rabbitmqctl工具修改这个账户的权限和密码,这在生产环境是必须要关注的. 出于安全和可移植性的考虑,一个vhost内的exchange不能绑定到其他的vhost.
可以按照业务功能组来规划vhost,在集群环境中只要在某个节点创建vhost就会在整个集群内的节点都创建该vhost.VHost和权限都不能通过AMQP协议创建,在RabbitMQ中都是使用rabbitmqctl进行创建,管理.
如何创建vhost
vhost和permission(权限)信息是并不是通过AMQP创建而是通过rabbitmqctl工具来添加,管理的.
说完vhost我们就来看看重中之重的消息:Message
Message
消息由两部分组成: payload and label. "payload"是实际要传输的数据,至于数据的格式RabbitMQ并不关心,"label"描述payload,包括exchange name 和可选的topic tag.消息一旦到了consumer那里就只有payload部分了,label部分并没有带过来.RabbitMQ并不告诉你消息是谁发出的.这好比你收到一封信但是信封上是空白的.当然想知道是谁发的还是有办法的,在消息内容中包含发送者的信息就可以了.
消息的consumer和producer对应的概念是sending和receiving并不对应client和server.通过channel我们可以创建很多并行的传输 TCP链接不再成为瓶颈,我们可以把RabbitMQ当做应用程序级别的路由器.
Consumer消息的接收方式
Consumer有两种方式接收消息:
通过basic.consume 订阅队列.channel将进入接收模式直到你取消订阅.订阅模式下Consumer只要上一条消息处理完成(ACK或拒绝),就会主动接收新消息.如果消息到达queue就希望得到尽快处理,也应该使用basic.consume命令.
还有一种情况,我们不需要一直保持订阅,只要使用basic.get命令主动获取消息即可.当前消息处理完成之后,继续获取消息需要主动执行basic.get 不要"在循环中使用basic.ge"t当做另外一种形式的basic.consume,因为这种做法相比basic.consume有额外的成本:basic.get本质上就是先订阅queue取回一条消息之后取消订阅.Consumer吞吐量大的情况下通常都会使用basic.consume.
要是没有Consumer怎么办?
如果消息没有Consumer就会老老实实呆在队列里面.
多个Consumer订阅同一个队列
只要Consumer订阅了queue,消息就会发送到该Consumer.我们的问题是这种情况下queue中的消息是如何分发的?
如果一个rabbit queue有多个consumer,具体到队列中的某条消息只会发送到其中的一个Consumer.
消息确认
所有接收到的消息都要求发送响应消息(ACK).这里有两种方式一种是Consumer使用basic.ack明确发送ACK,一种是订阅queue的时候指定auto_ack为true,这样消息一到Consumer那里RabbitMQ就会认为消息已经得到ACK.
要注意的是这里的响应和消息的发送者没有丝毫关系,ACK只是Consumer向RabbitMQ确认消息已经正确的接收到消息,RabbitMQ可以安全移除该消息,仅此而已.
没有正确响应怎么办
如果Consumer接收了一个消息就还没有发送ACK就与RabbitMQ断开了,RabbitMQ会认为这条消息没有投递成功会重新投递到别的Consumer.如果你的应用程序崩掉了,你可以设置备用程序来继续完成消息的处理.
如果Consumer本身逻辑有问题没有发送ACK的处理,RabbitMQ不会再向该Consumer发送消息.RabbitMQ会认为这个Consumer还没有处理完上一条消息,没有能力继续接收新消息.我们可以善加利用这一机制,如果需要处理过程是相当复杂的,应用程序可以延迟发送ACK直到处理完成为止.这可以有效控制应用程序这边的负载,不致于被大量消息冲击.
拒绝消息
由于要拒绝消息,所以ACK响应消息还没有发出,所以这里拒绝消息可以有两种选择:
1.Consumer直接断开RabbitMQ 这样RabbitMQ将把这条消息重新排队,交由其它Consumer处理.这个方法在RabbitMQ各版本都支持.这样做的坏处就是连接断开增加了RabbitMQ的额外负担,特别是consumer出现异常每条消息都无法正常处理的时候.
2. RabbitMQ 2.0.0可以使用 basic.reject 命令,收到该命令RabbitMQ会重新投递到其它的Consumer.如果设置requeue为false,RabbitMQ会直接将消息从queue中移除.
其实还有一种选择就是直接忽略这条消息并发送ACK,当你明确直到这条消息是异常的不会有Consumer能处理,可以这样做抛弃异常数据.为什么要发送basic.reject消息而不是ACK?RabbitMQ后面的版本可能会引入"dead letter"队列,如果想利用dead letter做点文章就使用basic.reject并设置requeue为false.
消息持久化
消息的持久化需要在消息投递的时候设置delivery mode值为2.由于消息实际存储于queue之中,"皮之不存毛将焉附"逻辑上,消息持久化同时要求exchange和queue也是持久化的.这是消息持久化必须满足的三个条件.
持久化的代价就是性能损失,磁盘IO远远慢于RAM(使用SSD会显著提高消息持久化的性能) , 持久化会大大降低RabbitMQ每秒可处理的消息.两者的性能差距可能在10倍以上.
消息恢复
consumer从durable queue中取回一条消息之后并发回了ACK消息,RabbitMQ就会将其标记,方便后续垃圾回收.如果一条持久化的消息没有被consumer取走,RabbitMQ重启之后会自动重建exchange和queue(以及bingding关系),消息通过持久化日志重建再次进入对应的queues,exchanges.
皮之不存,毛将焉附?紧接着我们看看消息实际存放的地方:Queue
Queue
Queues是Massage的落脚点和等待接收的地方,消息除非被扔进黑洞否则就会被安置在一个Queue里面.Queue很适合做负载均衡,RabbitMQ可以在若干consumer中间实现轮流调度(Round-Robin).
如何创建队列
consumer和producer都可以创建Queue,如果consumer来创建,避免consumer订阅一个不存在的Queue的情况,但是这里要承担一种风险:消息已经投递但是consumer尚未创建队列,那么消息就会被扔到黑洞,换句话说消息丢了;避免这种情况的好办法就是producer和consumer都尝试创建一下queue. 如果consumer在已经订阅了另外一个Queue的情况下无法完成新Queue的创建,必须取消之前的订阅将Channel置为传输模式("transmit")才能创建新的Channel.
创建Queue的时候通常要指定名字,名字方便consumer订阅.即使你不指定Rabbit会给它分配一个随机的名字,这在使用临时匿名队列完成RPC-over-AMQP调用时会非常有用.
创建Queue的时候还有两个非常有用的选项:
exclusive—When set to true, your queue becomes private and can only be consumed by your app. This is useful when you need to limit a queue to only one consumer.
auto-delete—The queue is automatically deleted when the last consumer unsubscribes.
如果要创建只有一个consumer使用的临时queue可以组合使用auto-delete和 exclusive.consumer一旦断开连接该队列自动删除.
重复创建Queue会怎样?如果Queue创建的选项完全一致的话,RabbitMQ直接返回成功,如果名称相同但是创建选项不一致就会返回创建失败.如果是想检查Queue是否存在,可以设置queue.declare命令的passive 选项为true:如果队列存在就会返回成功,如果队列不存在会报错且不会执行创建逻辑.
消息是如何从动态路由到不同的队列的?这就看下面的内容了
bindings and exchanges
消息如何发送到队列
消息是如何发送到队列的?这就要说到AMQP bindings and exchanges. 投递消息到queue都是经由exchange完成的,和生活中的邮件投递一样也需要遵循一定的规则,在RabbitMQ中规则是通过routing key把queue绑定到exchange上,这种绑定关系即binding.消息发送到RabbitMQ都会携带一个routing key(哪怕是空的key),RabbitMQ会根据bindings匹配routing key,如果匹配成功消息会转发到指定Queue,如果没有匹配到queue消息就会被扔到黑洞.
如何发送到多个队列
消息是分发到多个队列的?AMQP协议里面定义了几种不同类型的exchange:direct, fanout, topic, and headers. 每一种都实现了一种 routing 算法. header的路由消息并不依赖routing key而是去匹配AMQP消息的header部分,这和下面提到的direct exchange如出一辙,但是性能要差很多,在实际场景中几乎不会被用到.
direct exchange routing key完全匹配才转发
fanout exchange 不理会routing key,消息直接广播到所有绑定的queue
topic exchange 对routing key模式匹配
exchange持久化
创建queue和exchange默认情况下都是没有持久化的,节点重启之后queue和exchange就会消失,这里需要特别指定queue和exchange的durable属性.
Consumer是直接创建TCP链接到RabbitMQ吗?下面就是答案:
Channel
无论是要发布消息还是要获取消息 ,应用程序都需要通过TCP连接到RabbitMQ.应用程序连接并通过权限认证之后就要创建Channel来执行AMQP命令.Channel是建立在实际TCP连接之上通信管道,这里之所以引入channel的概念而不是直接通过TCP链接直接发送AMQP命令,是出于两方面的考虑:建立上成百上千的TCP链接,一方面浪费了TCP链接,一方面很快会触及系统瓶颈.引入了Channel之后多个进程与RabbitMQ的通信可以在一条TCP链接上完成.我们可以把TCP类比做光缆,那么Channel就像光缆中的一根根光纤.
参考资料
------------ 休息的分隔线 --------------