标签:cfs 字符 post 大于 归类 down 处理 注意力 安全
前一段时间在网上找ret2dir的资料,一直没找到比较系统的介绍,于是干脆把这篇经典的论文翻译了,当然,第一次翻译(而且还这么长),很多词汇不知道到底该怎么翻译,而且最近事情也比较多,
翻译得挺烂的,如有错误,请指正。
后续如果有机会也会分享一些关于ret2dir利用的一些理解,和使用技巧。
翻译 by JDchen
2016年12月7日
摘要
Return-to-user(ret2usr)攻击将被破坏的内核指针重定向到用户空间。为了获得一个更严格的地址空间隔离以应对这种攻击,我们采取一些内核加固措施,这些措施是通过禁止任意控制流执行转移和解除内核与用户空间的映射关系来实现。最近Intel和ARM公司通过为处理器添加SMEP,SMAP和PXN的特性来为这个目的提供硬件支持。不幸的是,尽管采取了上述措施来防止用户进程和内核的虚拟地址空间的隐性共享,但是由于在设计中,为了使隔离的数据进行交换时具有更高的性能,隐性地址共享始终存在。
在这项工作中,我们演示了如何通过隐性页框共享来完整的绕过软件和硬件的隔离保护。我们介绍了一种新的内核攻击技术,叫做 return-to-direct-mapped memory(ret2dir)。这种技术绕过了所有ret2dir防护。如,SMEP,SMAP,PXN,KERNEXEC,UDEREF,KGuard。我们还介绍了如何通过构建稳定的ret2dir exploit来绕过x86,x86-64,AArch32,以及AArch64架构的Linux内核。最后,为了防护ret2dir攻击,我们设计了并实现了一种排他性页框架所有权机制(exclusive page frame ownership scheme),以在最小的性能花销的同时禁止隐性共享内存。
1.介绍
尽管操作系统内核一直是一个极具吸引力的目标,但在几年前,攻击者仍致力于客户端和服务端的exploit的开发,这些程序一般都以管理员权限运行,而且更容易分析。然而,在过去几年,内核变成了极具吸引力的目标,继续前几年的趋势,在2013年,355个内核漏洞在NVD(National Vulnerability Database)被曝光,足足比2012多了140个。诚然,由于近来流行的操作系统有许多保护和缓解措施,最小权限执行准则(The principle of least privilege)在用户账号和系统服务中更好的执行,编译器对常见的软件漏洞提供了更多的防护,像浏览器和文档访问器(Word,Excel,Adobe reader等)这类目的性极强的软件开始使用沙箱,用户级软件的exploit编写变得越来越困难。换一个角度看,系统内核具有一个极大的代码库,以及由于不断增加的特性,攻击面也不断在变大。直白的说,内核代码行数从v2.6.11 的6.6 MLOC到v3.10的16.9 MLOC,足足增加了两倍多。
自然而然,与其努力去攻击被大量加固措施保护的用户级应用,攻击者转而把注意力移向了内核。通过攻击内核(compromising the kernel),他们能提升权限,绕过访问控制和策略实施,以及绕过隔离和配置机制。例如,在最近关于Chrome和Adobe reader的漏洞攻击代码中,在成功得到代码执行权后,攻击者通过内核漏洞打破各自的沙箱。
内核exploit的开发的机会是非常多的,以Linux 内核为例,那些一直困扰着通用软件的漏洞,例如,栈溢出,堆溢出,空指针,指针计算错误,内存泄露,释放重引用(UAF),格式字符串(Format string),无符号错误,整数溢出,竞争条件,权限检查缺失,函数参数处理不恰当,也存在于内核漏洞中,由于用户和内核空间隔离机制极弱,尽管存在内核保护机制,这些bug的利用还是十分有效的。尽管用户进程不能直接访问内核代码和数据,但是因为性能原因,内核直接映射到用户空间,所以相反是不对的。这种设计允许攻击者通过编写内核exploit,重定向内核代码或数据流指向用户空间,来在非root情况下以特权模式执行代码,篡改数据结构。这种攻击方式,称之为ret2usr,影响所有主要的操作系统,包括Windows和Linux,并且适用于x86/x86-64,ARM,和其它流行的处理器。
为了解决ret2usr攻击,很多为了是吸纳严格的地址空间隔离的措施被提出和实施,例如Pax’s KERNEXEC ,UDEREF,kGuard。在认识到问题的严重性之后,Intel引进了SMEP(Supervisor Mode Execute Protection)和SMAP(Supervisor Mode Access Protection)的处理器功能,当该功能被允许的时候,在内核空间中,禁止执行任意用户代码。ARM 也引入一种等同于SMEP的处理器功能:PXN(Privileged Execute-Never)。这些功能提供了类似的保障,在提供软件安全防护的同时运行开销可以忽略不计。
尽管上述措施防止了用户空间和内存空间的虚拟地址隐性共享,但是隐性数据共享依旧存在。基本的操作系统组成,如物理地址映射,I/O缓冲和页缓存,仍允许用户影响那些内核访问的数据,在本文中,我们在Linux上研究了上述问题,并说明如何在高性能解决数据交换问题 (trade stronger isolation) 的决策,在现有的框架下,我们提出了一个新的内核漏洞利用技术,叫做ret2dir(return-to-direct-mapped memory)。这在绕过现有的ret2dir时,依赖了现有的内存管理子系统的固有属性。这是通过利用一个核心区域,直接映射系统的一部分或全部物理内存,允许攻击者在内核地址空间内映射用户空间数据。
由于不同的内核布局,不同架构的内存管理特性,32位系统的部分物理物理内存映射,和在内核空间中,用户空间地址映射的未知性,进行ret2dir攻击是十分复杂的,我们公布了克服这些困难的各种技术的细节,并构造了稳定的ret2direxploit来对抗x86,x86-64,AArch32和AArch64架构的Linux加固技术。
为了缓解ret2dir攻击,我们设计并实现了我们设计了并实现了一种排他性页框架所有权机制(exclusive page frame ownership scheme)。这种技术防止了用户进程和内核隐性共享物理内存。我们测试的结果表明,加固措施得到了显著的防御效果,而且性能损耗在3%以内。
这篇文章的主要贡献如下:
1:我们通过介绍ret2dir攻击来披露Linux的内存管理子系统的基本设计缺陷。我们通过利用内核直接映射物理内存绕过了所有存在的ret2dir加固措施(SMEP,SMAP,PXN,KERNEXEC,UDEREF,kGuard)
2:我们介绍了构建稳定的ret2dir攻击x86,x86-64,AArc32和AArch64 架构的Linux的方法,这种方法通过利用强制用户空间攻击载荷强制暴露在内核直接映射RAM区和精确定位来实现。
3.我们实验性的通过使用一组九个漏洞(8个真实存在和一个伪造的)攻击不同内核配置和保护措施来评估ret2dir攻击的影响。,结果是,我们的exploit有效的绕过了所有的ret2usr防护。
4.我们提出,实现并评估了一种针对Linux的叫做排他性页框架所有权机制(exclusive page frame ownership scheme),这能以忽略不计的性能损耗缓解ret2dir攻击
2.背景和相关工作
2.1 Linux的虚拟内存组织
安全组合不同保护域的设计,将内核与用户进程放在同一个地址空间,并用软件进行隔离,使用户进程和内核拥有一个隔离,硬件强制的地址空间。Linux和基于Linux的系统(Android,Firefox OS,Chrome OS)采用这一种方法,使用一种更粗粒度的变体,将虚拟空间划分为用户和内核空间。在x86和32位ARM(AArch32)架构的CPU中,Linux内核一般映射在虚拟地址高层的1G内存中,,这种划分称为”3G/1G”。在x86-64和64位ARM中(AArch64)中,内核映射了典型的一半。
这种设计最大限度的减少了交叉保护域的开销,并且促进了用户空间和内核空间快速交互。当在进行系统调用或者处理异常时,内核处于抢占进程上下文。因此,当内核直接访问用户空间访问用户数据或写系统调用的结果时,刷新TLB是没有必要的。
2.2 return-to-usr(ret2usr)exploit
尽管内核代码和用户软件被一些通用的类型漏洞困扰,但由于内核和用户进程共享虚拟地址的执行模型使内核漏洞程序开发变得明显不一样。对于本地攻击者来说,共享地址空间提供了一个独特的优势点去控制内核所能访问部分的权限和内容。简单的说,攻击者可以通过劫持特权执行路径并将其重定向到用户空间来轻松地执行具有内核权限的shellcode。
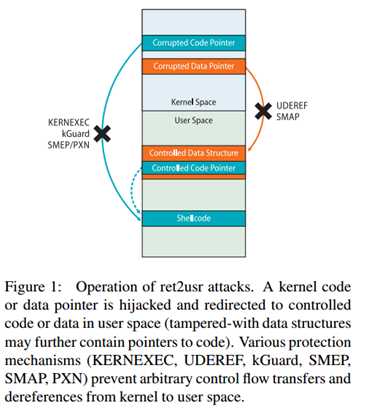
ret2usr的作为一种漏洞利用技术(同时也在其它操作系统上)已经有十多年的历史了。正如图一所示,在ret2usr攻击中,通常在内核代码中利用内存错误后,内核数据被用户空间地址覆盖。攻击者主要控制那些有利于执行任意代码的数据,例如,返回地址,函数指针,调度表。当然,由于可以通过在用户空间映射假的副本来篡改关键数据结构的关键数据,指向存储在内核堆或全局数据段中的关键数据结构的指针也是常见的目标,值得注意的是,为了能够执行任意代码,目标数据结构通常含有函数指针或能够影响内核中的代码执行流的数据。
大部分ret2direxploit利用多阶段的 shellcode,第一阶段依赖于用户空间,同时第二阶段一般是内核函数,这样来进行特权提升或者以root权限执行shell。从技术角度来说,ret2dir通常期望运行在攻击者控制的进程上下文中,这样才能够使攻击可靠。然而,内核bug也常在中断服务程序中被识别和攻击。在这种情况下,内核要么在中断上下文运行,要么在超出攻击者控制的进程上下文中运行。对应的shellcode必须注入到内核空间,或者利用ROP/JOP使用内核空间的小片段。由于日益增加的内核加固措施,后一种方法在现实世界极受欢迎。
2.3对ret2uer攻击的防护
Return-to-user 攻击是另一个典型的具有代表性的问题。考虑到问题的多体系和多OS的特性,存在几种防御机制。在这一节的剩余部分,我们将在图一的帮助下讨论几种ret2dir防御措施。
PaX:KERNEXEC和UDEREF是PaX加固补丁的两种特性。它们能防止控制流转移并接触内核空间到用户空间的引用。在X86架构中,KERNEXEC和UDEREF依赖内存分割于将内核空间映射到一个1G的的段中,当特权代码尝试去解引用非内核空间的指针或者从非内核空间提取指令返回一个内存错误。在x86-64中,由于缺少分段措施的支持,为了防止指向用户空间的指针的解引用,当执行进入内核空间时(退出时恢复),KERNEXEC/amd64将用户空间用户空间映射到一个不可执行的区域。由于重映射内存的开销极大,x86-64另一个可替代的方案是打开KERNEXEC/amd64,它具有较小的开销,但只针对控制流劫持进行保护。最近,KERNEXEC和UDEREF移植到了ARM架构,但只支持AArch而且依赖已弃用的MMU功能。
SMEP/SMAP/PXN:SMEP(Supervisor Mode Execute Protection)和SMAP(Supervisor Mode Access Protection)是Intel最新支持的两种处理器功能,以更好的促进地址隔离。其中,SMEP提供了类似KERNEXEC的保护,SMAP则类似于UDEREF。最近,ARM添加了等同于SMEP的功能,称为PXN(Privileged Execute-Never)。但是Linux仅仅在AArch64中使用。更重要的是,在AArch32,PXN要求MMU在LPAE模式下执行(相当于Intel的物理地址扩展模式),这种情况禁止了MMU域。因此,在AArch32上应用了KERNEXEC/UDEREF相当于放弃了PXN的支持和更大的大于4G内存。
KGuard:kGuard是一个跨平台的编译器扩展,这种扩展在没有特殊的硬件功能的前提下保护了内核受到ret2usr攻击。它通过扩展(在编译时)使用动态控制流断言(CFA)(在运行时)防止特许执行路径到用户空间的无约束转换的潜在可利用的控制转换来实施轻量级地址空间隔离。注入的CFA在计算每个分支之前会进行花费极小的运行开销来进行检查,检查目的地址是在内核空间还是在用户空间。此外,kGuard还采用了代码多样化技术来阻止攻击自身。
3 攻击概述
Linux遵循一种设计,弱的内核到用户隔离有利于促进内核进程和用户更好的交互。在这之前讨论的Ret2usr攻击防护主要是缓解这种设计缺陷,并以最小的开销来加强内核和用户空间的隔离。在这项工作中,我们试图评估这些保护提供的安全性,并调查某些面向性能的设计选择是否会使它们无效。我们的研究和调查表明这种机制存在,它存在Linux内存管理子系统中的架构中,滥用它可以用来削弱内核和用户空间的隔离。我们引入了一种新的内核利用技术,称为ret2dir,它允许攻击者执行相当于对加固系统的ret2usr攻击。
3.1 威胁模型
我们假定内核为了防护ret2dir攻击采取一种或一组节2.3 Linux的加固机制。此外,我们假定一个拥有本地访问权限的非特权攻击,它试图通过利用内存破坏漏洞来进行提权。需要注意的是,我们没有对破坏的数据类型做任何假设—代码和数据指针都是有可能的目标。
总的来说,我们假定对抗能力与执行ret2usr攻击所需的能力相同。
3.2 攻击策略
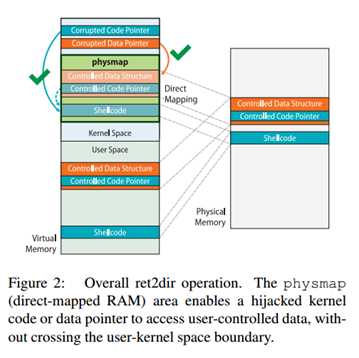
在为了对抗ret2dir攻击而实施的系统加固中,被劫持的控制或数据流不能再以直接方式重定向到用户空间。正如图一所示,各种ret2dir措施将会防止任何尝试。然而,内核和用户空间的物理内存隐性共享允许攻击者重构由ret2usr保护机制提供的隔离保护。并且将留重定位到用户控制的代码和数据中。准许物理内存共享的主要设备是 physmap:内核空间中一个大的,连续的虚拟内存空间,它映射了部分或所有(取决于具体架构)的物理内存。这片区域在快速进行动态内存分配中扮演了其为重要的角色(我们将会在第四节讨论physmap的结构。需要强调的是尽管在研究中我们主要集中在Linux上—使用最广泛的操作系统之一。但是由于这被认为是物理内存管理的标准实践,直接映射物理内存区域(direct-mapped RAM)也存在于其它很多操作系统。
由于物理内存分配给用户进程和内核,physmap的存在导致了地址别名。当两块或者多块虚拟内存映射到同一块物理地址时,就会产生地址别名。假定physmap能够映射内核中大部分物理地址,攻击者控制的进程可以通过地址别名来访问。
进行ret2dir攻击的第一步是将payload映射到内存空间。如图二所示,根据被利用漏洞是否能够控制代码指针或数据只能,payload由shellcode或者被篡改的数据结构组成。每当mm子系统为用户空间分配(动态)内存时,它实际上将延迟帧直到最后一刻。具体来说,物理内存使用请求分页和写时复制(copy-on-write)方法以延迟方式授予用户进程。这两者都依靠页错误来实际分配RAM。当有效载荷的内容被初始化时,MMU生成页面错误,并且内核分配页面来攻击进程。Mm子系统通过使用伙伴分配器来管理帧页。如图二示,假定physmap存在,伙伴分配器提供在用户空间被映射的页框时,mm有效在内核空间创建了exploit的地址别名。尽管系统无法直接使用地址别名,mm保持着整个RAM的初始化以增强页帧的初始化。这允许新释放的页帧立即对内核可用,而不需要改变页面表。(4.1具有更多的细节)。
总的来说,ret2dir利用内核空间和用户空间的隐性地址共享来将被劫持的内核或者数据流重定向到别名空间中,这也有效的执行了ret2usr攻击而无需到用户空间去。非常重要的是,在向攻击进程给出页面帧的时刻,恶意有效载荷“出现”在内核空间中。由于phsmap,攻击者这不需要显式的将payload放进physmap。使用这样的方法也不那么灵活,因为系统对可以分配给内核驻留缓冲区的内存量施加严格的限制,而漏洞有效载荷(很可能)必须被封装在某些可以影响其结构的内核数据对象。
4 揭开physmap的神秘面纱
理解ret2dir攻击机制的关键第一步是看Linux如何组织内核地址空间的,我们使用x86平台作为参考。x86-64架构使用48位虚拟地址,符号扩展为64位,这种方案把地址空间分成了两份,没份128TB。内核空间占了上半部分(0xFFFF800000000000 –0xFFFFFFFFFFFFFFFF).并进一步划分为六个区域:fixmap区,模块,内核映像,vmemmap区,vmalloc区和physmap区。另一方面,在x86中内核空间可以设置为高1G,2G或3G。通常默认为1G。由于内核地址空间被限制,所以一般内核空间都是稀缺资源,并且某些部分碰撞以防止浪费(例如模块空间和vmalloc区,内核映像和physmap区)。为了达到ret2dir攻击的目的,我们集中在direct-mapped区。
4.1作用
Physmap区域是内核表现出最重要的部分的映射,它能促进内核进程的动态分配。在一个较高层次中,mm系统提供了两种方法来请求内存:vmalloc和kmalloc。在vmalloc系列中,内存需要请求页的倍数大小的内存,而且需要保证虚拟地址连续,但不需要保证物理地址连续。与此相反,在kmalloc系列中,内存能够在字节级分配内存,而且保证不论在虚拟地址还是物理地址都是连续的。
由于vmalloc需要提供页倍数的内存,极易导致更高的内存碎片而且在缓存方面的性能表现也比较差。更重要的是,当内存被分配用于映射或解除映射各自的页时vmalloc需要改变内核的页表,这不仅会导致的额外的花销,而且会导致TLB crash。出于这些原因,内核主要使用kmalloc。然而,考虑到kmalloc会在任何上下文中被调用,例如有严格的时间限制的中断服务,它需要大量不同的要求。在大部分上下文中,分配器不能够睡眠。在其它的方面,它不允许失败或者需要返回的内存保证物理地址连续(例,当设备驱动程序需要为DMA保留内存)。
由于上述的一些限制,physmap是很有必要的,它具有极好的性能。Mm系统开发者选择依托于kmalloc的设计的区域映射整个(或者部分)RAM,是由于以下原因,首先,kmalloc在不需要接触内核页表的情况下分配内存,这不断显著的减少的了TLB的压力,而且以一种快捷的方式解除了一些潜在的操作,例如页表计算和TLB抖动。第二,这种相邻页映射的方法物理内存连续。这能增强缓存性能,而且能够允许驱动直接分配kmalloc区域给DMA驱动,这样可以直接操作物理连续内存(如当内有IOMMU支持的时候)。最后,由于地址转换(虚拟地址到物理地址或者物理地址到虚拟地址)能直接使用唯一的算术操作,所以页记账十分简单。
4.2位置和大小
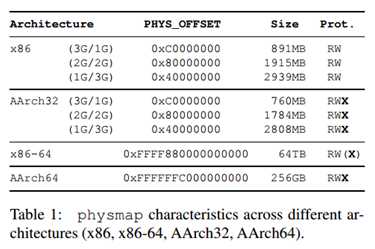
Physmap是一个架构独立的特性(基于上文概述给的原因,这不需要吃惊),它存在于所有流行的Linux平台。根据每种ISA的寻址特性不同,physmap的大小和准确位置都不同。尽管如此,在所有情况下:存在内核空间的部分或者全部物理地址的直接映射,而且映射开始于一个固定已知的位置,即使内核采用了ASLR,后一点依旧成立。
表1列出了我们参考的physmap一些感兴趣的特性。在x86-64系统中,physmap直接以1:1的方式进行映射,从0页表开始,将整个RAM放进64T的区域中,AArch64使用了256G的空间完成了相同的目标。不同的是,在x86系统中,内核直接映射部分可用的RAM内存。
在32位架构的处理器中,physmap的大小取决于两个因素:内核和用户空间大小的划分(3G/1G,2G/2G,1G/3G)以及vmalloc区的大小,在默认设置中,当1G划分给内存时,vmalloc占了120M,此时physmap为891M(1G-sizeof(vmalloc+pkmap+fixmap+unused)),并且开始于0xC0000000,在其它两种情况中,2G/2G(3G/1G),physmap开始于0x80000000(0x40000000),占了1915M(2939M)。AARch32的情况也很类似,唯一不同的是vmalloc区的默认大小为240M。
总而言之,在32位系统中,直接映射物理内存的大小取决于RAM和physmap。如果sizeof(physmap)>=sizeof(RAM)的话,整个RAM是可以全部映射的。对于高达1G RAM的32位手机来说这是一种常见的情况。否则,从第一个页开始,只能直接映射到sizeof(physmap)/sizeof(PAGE)的位置了。
4.3访问权限
进行ret2dir攻击的一个很关键的一个方面是physmap的访问权限。为了获取与直接映射的存储器区域相对应的内核页面的保护位。我们建立了kptbuild:以通过debugfs伪文件系统导出页表的内核模块形式的实用程序。整个工具遍历了内核页表,可以通过全局符号表swapper_pg_dir(x86/AArch32/AArch64)和init_level_pgt(x86-64),并转储在physmaps区的每一个页的标志(U/S,R/W,XD)。
在x86系统中,physmap在我们尝试的所有内核版本中映射为可读和可写。然而,在x86-64中,physmap的权限没有处于一个正常的状态。在v3.8.13之前的内核,直接将映射的整个区域设置为可读可写可执行(RWX),但这样违背了W^X属性。仅仅在最近的内核版本中(>=3.9)使用了更多保留的RW映射。最后,AArch32和AArch64的physmap在所有我们测试的版本中都是可读可写可执行的。
5 定位别名位置
进行ret2dir攻击的最后一步是找到一种方法,能够稳定的在physmap区找到用户空间的别名地址的位置。对于传统环境,physmap仅仅映射系统物理内存的一部分,例如拥有8G RAM的32位系统,一个必要的要求是确定感兴趣的用户空间的别名存在。为了实现这两个目标,我们提出了两种方法,第一种方法依赖于/proc文件系统的pagemap提供的借口来获取页框信息,这种方法能在所有我们研究的Linux发行版本以非特权的用户进行访问。由于ret2dir攻击的危险性会鼓励系统管理员和Linux分发版本关闭对pagemap的访问,所以我们提出了另一种不需要借助任何信息泄露的技术。
5.1泄露PFNs(via/proc)
Procfs伪文件系统在泄露系统敏感信息上有很长一段历史了。从v2.6.25开始,一组伪文件,包括/proc/<pid>/pagemap,为了方便调试,添加进了/proc以允许页表的检查。为了评估这个设施的普及程度,我们根据DistroWatch测试了最受欢迎的发行版的最新版本。在所有情况中,pagemap都是默认打开的。
对于每一个用户页来说,pagemap提供了一个64位的值,由页号来索引。其中包含关于页面在RAM中的是否存在的信息。如果页存在,然后第63位被设置,0到54位设置为PFN(Page Frame Number)。正是如此,这样,给定用户空间虚拟地址uaddr的PFN可以通过打开/ proc / <pid> / pagemap并从文件偏移量(uaddr / 4096)* sizeof(uint64_t)读取8个字节来定位(假设4KB页)
使用给定uaddr的PFN,表示为PFN(addr)。Uaddr在physmap的地址别名地址表示为SYN(uaddr)。SYN(uaddr)则可以使用以下公式计算出来:SYN(uaddr)=PHYS_OFFSET+4096*(PFN(uaddr)-PFN_MIN),其中,PHYS_OFFSET固定为physmap的内核起始地址(如表一所示,值根据配置的不同而不同),而PFN_MIN是第一个页框数,包括ARM在内的很多处理器架构中,物理内存都不是从0开始的(例如:Versatile Express ARM board是,它的的PEN_MIN的值为0x60000。为了防止SYN(uaddr)被回收(例如,交换了uaddr)。各自的使用者能过通过mlock函数来锁定RAM。
Sizeof(RAM) > sizeof(physmap): 对于其中RAM的一部分被直接映射的系统,只有PFN的子集可以通过physmap访问。例如,在拥有4GARM的x86系统中,PFN的范围为0x0~0x100000.然而,在3G/1G的划分中,physmap仅能映射RAM的前891M,这意味着PFN的范围为0x~0x37B00(PFN_MAX)。如果用户空间地址的PFN大于PFN_MAX(最后一个直接映射的页),则physmap的位置不能包括地址的别名, 自然而然,出现的问题是我们是否可以强迫伙伴分配器提供具有小于PFN_MAX的PFN的页面帧。
出于兼容性考虑,mm系统将物理内存划分为几个不同的空间,值得一提的是, 旧的ISA总线的DMA处理器只能寻址第一个16MB的RAM,而一些PCI DMA外设只能访问第一个4GB。Mm系统支持了一下空间:Zone_DMA,ZONE_DMA32,ZONE_DMA32,ZONE_NORMAL和ZONE_HIGHMEN。后者在32位平台使用,而且包含那些不能直接由内核寻址的地址(就是那些没有在physmap的地址)。ZONE_NORMOL在ZONE_DMA (在64位系统中,ZONE_DMA32)上,在ZONE_HIGHMEN下。当只有部分RAM被直接映射。Mm系统按照以下进行分配:ZONE_HIGHMEN>ZONE_NORMAL>ZONE_DMA,给定一个页框请求,mm将尝试满足它从符合请求的最高区域开始。(例如,正如我们所讨论的,ZONE_NORMAL的直接映射内存更偏爱kmallc),只要没有空余的页就会移至低空间。
从攻击者的角度来看,由于mm尝试去保留那些从内核请求的直接映射的动态内存,用户进程最先从ZONE_HIGHMEN中得到页框。然而,当ZONE_HIGHMEM的页框耗尽时,由于不断增加的内存压力,mm不得不从ZONE_NORMAL或者ZONE_DMA获取页框。以这一点为基础,我们的策略如下:攻击进程不断使用mmap函数来申请内存,对于申请的内存的每一页,通过访问单个字节产生一个页错误来强制mm分配一个页框(或者,mmap中的MAP_POPULATE标志可用于预分配所有相应的页框)。然后进程检查每个收集的页PFN,同样的步骤将会不断重复直到获得一个小于PFN_MAX的PFN。就这样,页的别名就这样保证出现在physmap中,并且准确的地址能够通过上文的公式准确计算出来了。需要注意的是,取决于物理地址的大小和物理地址划分,我们可能需要产生额外的进程以完全耗尽ZONE_HIGHMEM。例如,在拥有8G RAM,默认3G/1G划分的x86架构机器中,可能需要多达三个进程以确保获取落入physmap中的页面帧。有趣的是,系统运行的良性程序越多,攻击者获取就越容易获取在physmap的别名地址。换句话说,任务越多,内存压力就越大,越容易将攻击者地址压入需要的空间。
连续的地址别名: 某些exploit可能需要多于一个页面用于其有效载荷,页在用户空间是连续的,然而,映射到物理内存没必要连续,这意味着它们的别名地址可能不会连续。然而,给定的线性映射,两个连续的别名地址的PFNs也是连续的。因此,如果0xBEEF000和0xFEEB000的PFN 分别为0x2E7C2和0x2E7C3,它们在physmap中是连续的,尽管在用户空间他们相差64M。
为了识别连续的别名空间,我们进行了如下:使用上述的同样方法,我们计算了随机用户空间页的地址别名。我们然后尝试获得更多地址别名,每次获得的PFN和之前获得的进行比较。这一过程不断重复,知道获得两个具有连续的PFN的别名地址空间。然后exploit可以对payload在具有顺序PFN的用户页上进行适当拆分。
5.2 physmap喷射
由于解除对/proc/<pid>/pagemap的访问是一件非常简单的事情,我们也考虑到PFN不能获取的情况。在这种情况下,给定存在在RAM的用户页,无法确定在physmap的别名地址空间的位置。回想一下我们的目标是确定一个physmap中的用户空间页别名,里面包含了一个payload。尽管我们不能直接确定一个给定的用户空间地址的别名空间,但依然可以以一个相反的方向运行,选定一个任意的physmap地址,并确保(尽力)其对应的页框包含exploit代码的payload。
这可以通过一种类似于堆喷射的方法实现,利用exploit的载荷的副本来耗尽地址空间。基地址和physmap区的长度已经知道了(表1),后者对应PFN_MAX-PFN_MIN页框,共享所有的用户进程和内核。如果攻击进程将漏洞利用载荷复制到n的内存驻留页中(由physmap映射的物理内存页范围内)。那么任意选择指向漏洞利用载荷的概率为:P = N/(PFN_MAX – PFN_MIN)。我们的目标是最大化P。
喷射:最大化N是最简单明了的,即尽可能获取更多的页。我们使用的技术和5.1的一种技术非常相似。攻击进程不断使用mmap函数来申请内存,向返回区域喷射攻击载荷。相比于shmget,brk和remap_file_pages,由于系统对后者有诸多限制,我们更偏向于调用mmap函数。因为与匿名映射相比,现有的文件支持的映射具有在交换中具有更高的优先级,MAP_ANONYMOUS配置更加好。载荷的复制导致页错误,从而导致mm分配页框。如果虚拟地址空间这不足以耗尽RAM,在某些32位的配置中存在,攻击进程需要派生额外的子进程来辅助分配。
这一过程持续知道将喷射页交换到磁盘上,要准确定位到进行交换的准确时刻,攻击进程需要通过在每调用几次mmap函数都调用getrusage()来定期检查被喷射的页是否在物理内存中。同时,所有的攻击程序启动一组后台进程来不断重复写入,以模拟mlock()。来防止(尽可能)喷射页被交换。 Mm使用LRU机制交换页表到磁盘。因此,mm被欺骗,相信它们都是新的内容。当驻留内存页的数量开始下降时(攻击进程的RSS(the resident-set size)开始下降),它已经达到了所允许的最大物理内存占用。当然,内存空间的占用大小也取决于和攻击内存进行竞争的其它进程产生的负荷。
签名:就PFN_MAX~PFN_MIN而言,我们可以通过排除那些伙伴分配器永远不会给用户空间提供帧的页面来减少physmap的潜在页目标。例如,在x86和x86-64中,BIOS通常存储在POST期间检测到的页框0处的硬件配置。同样,物理地址范围0xA0000-0xFFFFF被保留用于映射某些图形卡的内部存储器。另外,对应于内核代码和全局数据的ELF段被分配在RAM的固定已知的位置。基于这些其它预定分配,我们已为每个我们考虑的配置生成保留页框范围的physmap签名。如果签名不可用,那么所有的都是潜在的目标。通过结合physmap喷射和页签名,我们能最大化我们选择任意physmap击中漏洞攻击代码payload的可能性。我们的实验结果评估可得,取决于具体配置,成功的可能性高达96%。
6 归纳
6.1绕过SMAP和UDEREF
我们以一个绕过经由SMAP和UDEREF加固的x86系统的ret2dir的攻击事例开始。我们假定了一个允许我们可以破坏内核数据指针,名为kdptr,并且可以对其写任意值。在一个没有加固的内核中,攻击者可以通过在用户空间来重写kdptr,并通过调用一个适当的接口(例如一个错误的系统调用)来强制内核解除引用。然而,SMAP和UDEREF的出现可以造成内存访问冲突,从而有效的组织漏利用。为了成功利用,可以通过以下方式来进行ret2dir攻击。
首先,一个攻击者控制的进程保留一个单独的页,地址为0xBEEF000。然后攻击者继续用攻击载荷初始化新分配的内存。载荷初始化阶段将会导致页错误,使其从伙伴分配器申请内存并映射到0xBEEF000.假设伙伴分配器分配了0x770号页框、在x86系统中,默认的地址划分为3G/1G,此时physmaps的起始地址为0xC0000000,这意味着页框预映射的地址为0xC0000000+(4096+0x770)=C0770000。在这一点上,0xBEEF0000和0xC0770000是别名关系。它们都映射到包含攻击者载荷的物理页上。因此,任何在0xBEEF00~0xBEEFFFFF区域的数据在内核空间都可以通过内核别名空间0xC0770000~0xC0770FFF来访问。更糟糕的是,由于physmap主要用于实现动态内存,内核不能区分位于0xC0770000的数据的真伪(一般使用kmalloc进行分配)。因此,由于保护措施都认为高于0xC0000000的地址解引用都是良性的,通过重写0xC0770000(而不是0xBEEF000)来覆盖kdptr,可以成功绕过SMAP和UDEREF。
6.2绕过SMAEP,PXN,KERNEXEC和kGuard
我们通过一个在x86-64上的例子来演示ret2dir技术怎么绕过SMEP(PWN基本等同SMEP),KERNEXEC和kGuard.我们假定一个内核利用可以任意值重写一个内核函数指针,叫做kfptr。在这组设置中,攻击载荷不是一组数据结构,而是一组能以特权执行的机器码。在真实世界中,攻击载荷通常由多级shellcode组成。其第一级将用于执行特权升级的内核例程(第二级)连接在一起。在大多数情况下,归类于执行类似于commit_creds(prepare_kernel_cred(0))的代码。这两个例程将用户的credential((e) uid,(e) gid)替换为0.有效的将用户进程提升至root。
流程基本和上一个例子相似。假定攻击载荷被复制到用户空间地址0xBEEF000,伙伴分配器将页框指定为0x2E7C2。在x86-64中,physmap的起始地址为0xFFFF880000000000,使用常规页映射了整个RAM,因此0xBEEF000的在内核空间的地址别名在0xFFFF880000000000+(4096*0x2E7C2)=0xFFFF87FF9F080000。
在ret2usr场景中,攻击者控制内核函数指针,一个优点是它们还控制包含漏洞有效负载的用户页面的内存访问权限,使得将shellcode标记为可执行的命令变得非常容易。然而,在一个加固的系统中,ret2dir攻击允许只控制physmap中各个别名页面的内容,而不是它们的权限。换句话来说,尽管攻击者可以改变0xBEEF000~0xBEEEEEEEE,但不能设置在内核空间的范文权限。不巧的是,正如表一所示,W^X在很多平台并没有强制实施,其中包括x86-64.在我们的例子中,用户地址0xBEEF000的内容也可通常也可以通过内核地址0xFFFF87FF9F080000执行。因此只要简单的将kfptr覆盖为0x FFFF87FF9F080000并且触发内核对其解引用,攻击者可以直接以内核权限执行shellcode。KERNEXEC,kGuard和SMEP不能区分kfptr指向的是合法还是非法的内核例程。只要kfptr>0xFFFF880000000000并且*kfptr是RWX,解引用则被认为是良性的。
不可执行physmap: 在上面的例子中,我们利用了一些事实,一些平台将部分(或全部)的physmap区域映射为可执行(X)。但是问题是,当physmap具有恰当的权限是,ret2dir攻击是否影响。正如我们在第七节演示的,甚至在这个例子中,通过使用ROP技术ret2dir攻击都能顺利使用。
让我们重温上文的例子,这一次假定physmap不可执行。与直接在0xBEEF000直接映射shellcode不同,攻击者可以映射等价的ROP payload。相同的功能由那些内核空间内以ret结尾的代码片段组成的链实现。为了触发ROP链, 使用指向堆栈片段改变rsp的地址来覆盖kfptr,这是将堆栈指针设置为ROP有效载荷的开始所需的,以便每个片段可以将控制转移到下一个。通过指向类似于xchg %eax,%rsp;ret(假定%rax 指向0xFFFF87FF9F080000)的片段,使别名空间扮演类似于内核栈的角色。注意,Linux使用kmalloc为每一个用户分配内核栈且它们都停留在physmap中,使得不可能在内核空间使用ret2dir来区分合法堆栈和ROP 载荷 的push。最后,需要注意的是, ROP代码还应该注意恢复堆栈指针(以及可能的其他CPU寄存器)以允许的内核继续运行。
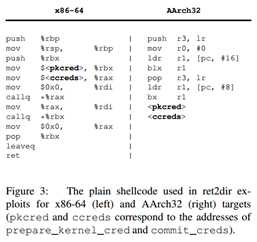

7 安全评估
7.1效果
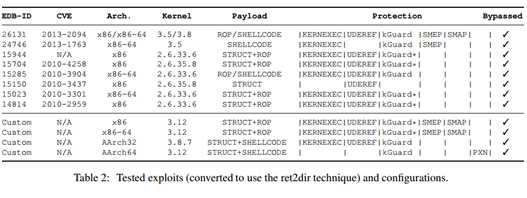
我们使用真实世界的经典漏洞来评估评估ret2dir面向ret2usr加固的有效性。我们从EDB(Exploit Database)获取了一组八个漏洞,包括了v2.6.33~v3.8的不同版本。我们现在没有加固的内核上运行,确定是否能正常工作,然后,我们在加固的内核中使用ret2dir进行攻击,所有的exploit都失败了。最后,我们使用第五节的技术将exploit等价转化为ret2dir攻击,并对加固内核进行攻击,总的来说,我们的攻击绕过了所有可利用的ret2dir保护,包括(SMAEP,PXN,KERNEXEC和kGuard)。
表二总结了我们的发现。前两列(EBD-ID和CVE)说明我们测试的具体漏洞。第三列说明(Arch)和第四列(Kernel)说明架构和内核版本,payload列说明载荷的种类,使用ROP,还是SHELLCODE,还是篡改的数据结构,或者上述的组合,当然,这些取决于漏洞利用本身。Protection则列出了每一种情况的设置的保护机制。空的说明没有任何保护措施,可能是因为由于给定的内核版本,不适用特殊的架构,也可能于特定的漏洞有关系。例如,PXN仅仅支持ARM架构,与此同时SMEP和SMAP则是Intel的处理器特性。此外,SMEP在v3.2被添加,SMAP在v3.7被添加。注意,根据physmap区域的权限(见表1),我们不得不修改一些依赖普通shellcode使用ROP有效载荷的漏洞,以便实现任意代码执行(虽然在ret2usr漏洞攻击者可以给予可执行权限到包含有效载荷的用户空间存储器,在ret2dir中利用它是不可能修改physmap的权限)。
正如我们在2.3所提及的,KERNEXEC和UDEREF被AArch架构支持了。除了提供更强的地址空间分隔,作者还努力通过强制在Physmap中的大多数RWX页面设置W ^ X属性来修正AArch32中的内核的权限。然而,由于相应的补丁目前正在开发中,因此在physmap内仍存在被映射为RWX的区域。在内核v3.8.7中,我们找到了一个映射为RWX的大约6MB的Physmap区域,使得在我们的ret2dir漏洞中能够执行shellcode。
我们找到的有公共可利用的exploit的内核版本是v3.8。因此,为了评估最新的版本,我们自定义了一个exploit。我们人为插入了两个漏洞,这允许我们破坏内核数据或者指针,并可以写入任意值(在表2中用Custom标志)。值得注意的是这两个与那些公开的可利用的漏洞类似。关于ARM,我们成功管理引导的最新PaX保护的AArch32内核是v3.8.7。
对于每一个exploit,我们测试所有可利用的保护。在所有情况下,ret2dir攻击仅仅将控制流转移到内核地址,绕过了所有的加固。图三展示了我们在x86-64和AArch32架构上使用的shellcode。如6.2节,shellcode是位置无关的,所以只要将phcred和ccreds替换成prepare_kernel_cred和commit_creds的地址就好了。通过将shellcode复制到在physmap有别名的用户地址上,我们可以通过改写函数指针来指向该用户地址使得shellcode以内核态运行。我们在所有physmap能以可执行的方式被映射时使用这一方式(对应于表二的payload列)。
在一些physmap不能执行的情况中,我们用ROP链来代替shellcode以实现同样的目的。在这些情况中,指针被覆盖为栈转换(stack pivoting)gadget,它能将栈指针指向包含用户空间ROP payload的physmap页上。图四展示了一个x86 ROP payload的一个例子。
第一个gadget保存了esp和ebp以使代码能够方便稳定的运行下去。修改的空间能够在受控制的页内被方便的定位,因此可以容易地相应地计算SCRATCH_SPACE_ADDR1和SCRATCH_SPACE_ADDR2的地址。
7.2喷射性能
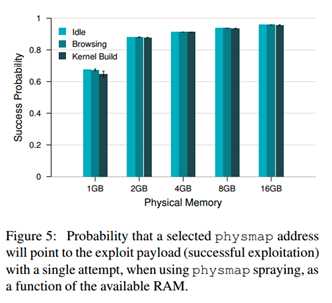
对于那些不能访问pagemap的系统来说,ret2dir攻击必须靠physmap喷射来找到synonym的别名空间 。正如5.2节所讨论的,随机选择指向攻击有效载荷的物理地址的概率取决于(i)payload在RAM的数量,(ii)由于竞争过程导致的物理存储器负载,以及(iii)生理图区域的大小。为了评估这种可能性,我们在不同的系统配置和工作负载下进行了一系列实验。图5所示,我们选择一次能够成功选择physmap地址的概率,作为RAM大小的函数。我们的测试平台包括一个单一主机,配有两个2.66GHz四核Intel Xeon X5500 CPU和16GB内存,运行64位Debian Linux v7。每个条表示5次重复的平均值,误差条对应于95%置信区间。在每次重复时,我们使用喷射技术(第5.2节)计算我们设法获取的物理图页面帧的最大数量的百分比,以超过了物理图的大小。我们使用三种不同的工作负载增加内存压力:空闲系统,一个桌面式工作负载,在多个选项卡(Facebook,Gmail,Twitter,YouTube和USENIX网站)中具有不断的浏览活动,以及具有在8个CPU核上运行的16个并行线程的分布式内核编译。注意,有必要在竞争过程中保持连续活动,以使它们的工作集保持热(最坏情况场景),否则攻击ret2dir进程将很容易窃取其内存驻留页面。
成功的概率随着RAM的变大而增加。对于最低内存配置(1GB),取决于工作负载,概率范围在65-68%之间,。空闲和密集工作负载之间的这个小差别表明,尽管竞争过程的连续活动,但是ret2dir进程管理要求大量的存储器,因为它们重复地访问所有已经分配的页面“锁定”他们到主存储器。对于2GB配置,概率跳到88%,并达到96%的16GB。注意,由于这些实验是在64位系统上执行的,因此physmap总是映射所有可用的内存。在32位平台上,其中physmap仅映射RAM的一个子集,成功的概率甚至更高。如5.1节所讨论的,在这种情况下,由竞争进程(更可能是在ret2dir进程之前产生的)创建的额外内存压力有助于将ret2dir分配“推送”到落在physmap区域内的所需区域(ZONE_NORMAL,ZONE_DMA) 。最后,根据漏洞,失败的攻击很多都不会导致内核崩溃,允许攻击者多次运行漏洞。
8 防御ret2dir攻击
限制或者完全禁止(编译时取消对PROC_PAGE_MONITOR的支持)对/proc/<pid>/pagemap的访问是禁止的第一步,但这只能起隐藏作用,不能起到防范作用。在这一节中,我们对Linux内核提出了XPFO(eXclusive Page Frame Ownership)方案,它能以一种较低的性能损耗来提供有效的保护。
8.1 XPFN标志
XPFO是一个简单的管理层,通过内核或用户级进程强制实现页框的独占所有权。具体来说,在XPFO下,除非内核组件显式地请求(例如,实现零拷贝缓冲区[84]),否则不能将页面帧分配给内核和用户空间。
我们选择了一种不会对性能关键的内核分配器造成不利影响的设计,只要将页面帧分配给用户进程(或从用户进程回收),就会降低额外开销。回想一下,使用需求分页和写时复制(COW)方法[7]将物理内存分配给用户空间,这两种方法都依赖页错误来分配RAM。因此,用户进程已经支付了用于执行页错误处理程序和执行必要的bookkeeping的运行时惩罚。XPFO与这种设计理念一致,并且略微增加了用户空间页面帧分配的管理和运行时开销。至关重要的是,physmap区域保持不变,slab分配器以及直接与buddy分配器连接的内核组件继续获取被保证物理上连续并受益于快速虚拟到物理地址转换的页面,因为没有额外的页表行走或修改。
每当将一个页框分配给用户进程时,XPFO会从physmap中取消其physmap映射的别名空,并确保恶意内容不能再使用ret2dir“注入”内核空间。同样,当用户进程将页框释放回内核时,XPFO会将相应的页映射回physmap,以主动方便动态(内核)内存请求。这里的关键要求是在将内容提供给内核之前,清除由用户进程返回(或从用户进程中收回)的页面框架的内容。否则,非净化XPFO方案将容易受到以下攻击。恶意程序产生一个子进程,它使用第5节中介绍的技术来映射其有效载荷。由于XPFO已经就位,所以有效载荷从physmap中被解映射,并且不能被内核寻址。然而,一旦子进程终止,它将被映射回来,使得它容易被恶意程序用于加载ret2dir攻击。
8.2实现
我们在v3.13实现了XPFO,我们的实现(~500LOC)通过使用一组与TLB处理和页面清理相关的优化,将管理和运行时开销保持最小,并适当地处理页面帧分配给用户进程(和从用户进程回收)的所有情况。一般来说,XPFO需要处理:(a) 预申请的地址别名和共享存储器映射而申请页框(brk,mmap/mmap2,mremap,shmat) (b) COW 帧(fork,clone)(c)显性或隐性回收栈帧(_exit,mumap,shmat)(d)页交换(包括页的换入和换出)(e)NUMA栈迁移(migrate_pages和move_pages)(f) 大页和大透明页
处理上述所有情况还是很有挑战嘀!为此目的,我们先扩展了系统页的数据结构(struct page):xpfo_kmcnt(引用数量),xpfo_lock(spinlock),xpfo_flags(32位标记域)。Struct page早已经有一个标记了,但是在32位系统中,就显得不够用了。注意尽管在系统中,每一个页都有一个page变量,但是我们的改动只在每1G的RAM多加了3M空间。此外,在xpfo_flags中,我们仅仅使用了3位:”Tained”(T:bit 0),”Zapped”(Z:bit 1),”TLB-shootdown needed”(s; bit 2)。
然后,我们扩展了伙伴分配系统。无论何时伙伴分配系统接收了申请用户空间的页框的请求(将gfp_flags设置为GFP_USER,GFP_HIGHUSER,GFP_HIGHUSER_MOVEABLE的请求),XPFO将会解除在physmap的映射,并且将xpfo_flag.T置位。那些分配给用户的页框页不会被信任。相反,那些分配给内核空间的页,XPFO将会xpfo_flags.S置1 当页框被释放,返回给伙伴系统时,XPFO检查xpfo_flags.T是否已经置1,如果置1,页被映射到用户空间,需要被交换出去。置0之后,XPFO重新将其映射到physmap,并且将xpfo_flags.Z置1.如果xpfo_flags.T没有置1,伙伴分配系统回收先前分配给内核的页,不需要任何多余的行为(快速路径:没有干扰内存的分配).注意在32位系统中,如果相关的页框来自ZONE_HIGHMEM,则不执行上述操作 - 此区域包含未直接映射的页框。
最后,为了完整的实现(a)~(f),我们利用了kmap/kmap_atomic和kunmap/kunmap_atomic。这些函数用于临时(取消)映射从ZONE_HIGHMEM获取的页面帧(见第5.1节)。在64位系统中,整个RAM都能直接映射,kmap / kmap_atomic直接从physmap返回相应页面帧的地址,而kunmap / kunmap_atomic定义为NOP并由编译器优化。如果启用XPFO,则相应地重新定义所有这些。由于用户空间页优先从ZONE_HIGHMEN分配,内核将与我们考虑的情况相关的所有代码(例如,请求调页,COW,交换)与上述函数包装在一起。使用kmap来操作与用户进程无关的页面框架的内核组件确实存在,我们使用xpfo_flags.T区分这些情况。如果页面帧被传递到kmap / kmap_atomic并且该位被置1,这意味着内核尝试通过其内核别名在分配给用户空间的帧上操作(例如,读取其内容以用于交换它)并因此被临时映射回physmap中。同样,在kunmap / kunmap_atomic中,xpfo_flags.T置1的页框未映射。注意,在32位系统中,XPFO逻辑在kmap例程上仅对直接映射的页帧执行(见表1)。 xpfo_lock和xpfo_kmcnt用于处理具有相同页面帧的kmap / kmap_atomic和kunmap / kunmap_atomic的递归或并发调用。
优化:XPFO的运行开销主要来自下面两个方面:(1) 清理回收页面的内容(2)TLB抖动和冲刷(由于我们修改了页表,所以很必要)。我们使用了三种措施来使开销最小化。由于完全TLB刷新导致禁止的减速,在支持单个TLB条目无效的架构中,XPFO选择性地仅驱逐对应于未映射的physmap中的别名空间的那些条目;在x86 / x86-64中,这是使用INVLPG指令完成的。
在具有多核CPU的系统中,XPFO必须考虑TLB一致性问题。特别地,我们必须在先前分配给内核本身的页面帧被映射到用户空间时执行TLB下拉。 XPFO扩展伙伴系统以使用xpfo_flags.S。如果在将页面帧分配给用户空间时将该标志置1,则XPFO通过向级联TLB更新发送IPI中断来使在每个CPU核中的physmap中对应于该帧的别名空间的TLB条目无效。在所有其他情况下(即,从一个进程传递到另一个进程的页框,来自以后分配给内核的用户进程的回收页框,以及分配给内核,回收并随后再次分配给内核的页框) XPFO仅执行本地TLB无效。
为了减轻页面清理的影响,我们利用了先前映射到用户空间的页面帧,并且由伙伴系统收回的页面帧具有xpfo_flags.Z置1的事实。我们扩展了clear_page以检查xpfo_flags.Z,并且如果该位被置1,则避免清除帧。这种优化避免了将页面帧调零两次,以防它被用户进程首先回收,然后被分配到需要干净页面的内核路径 - 由需要零填充页面的每个内核路径调用clear_page。
限制:XPFO通过制动不同安全上下文之间的随机地址空间共享来提供对ret2dir攻击的保护。但是,它不会阻止内核和用户空间之间的通用形式的数据共享,例如通过I / O缓冲区,页面缓存或通过系统对象(如管道和消息队列)推送到内核空间的用户控制内容。
8.3评估
为了评估保护方案的有效性,我们使用了7.1节中真实世界的漏洞的ret2dir版本。我们在我们之前使用的6个版本中打了XPFO补丁,并且在允许XPFO运行时再一次进行测试,在所有情况里,XPFO都成功挡住的ret2dir攻击。
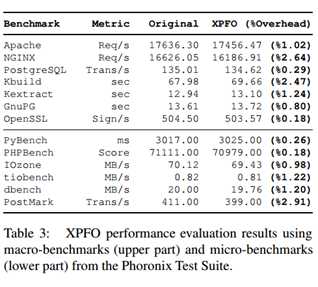
为了评估XPFO的性能开销,我们使用了内核v3.13,以及来自PTS(Phoronix Test Suite)的宏基准和微基准的集合。PTS集合了标准的系统测试,像 apachebench,pgbench,kernel build和IOZone,这些通常被系统开发员来跟踪性能回归。我们的测试和7.2节相同,表三总结了我们的发现。总的来说,XPFO的性能开销极小(在大部分情况下可以忽略不计),在0.18-2.91%之间
9 总结
我们提出了ret2dir攻击,一种新颖的内核利用技术,利用直接映射物理内存区域绕过现有的免受ret2usr攻击的保护。为了加强地址隔离,我们设计并实现了XPFO,一种Linux内核所有者独占页框的设计,它能防止物理内存隐性共享,我们的实验评估证明XPFO以及小的开销提供有效的保护。
可用性
我们的XPFO的实现和所有改良的ret2dir攻击可以在http://www.cs.
columbia.edu/~vpk/research/ret2dir/ 找到
ret2dir:Rethinking Kernel Isolation(翻译)
标签:cfs 字符 post 大于 归类 down 处理 注意力 安全
原文地址:http://www.cnblogs.com/0xJDchen/p/6143102.html