标签:技术 res 使用 tin ini 不能 打印 方式 方法
首先做好准备工作,创建一个Scrapy项目,目录结构如下:
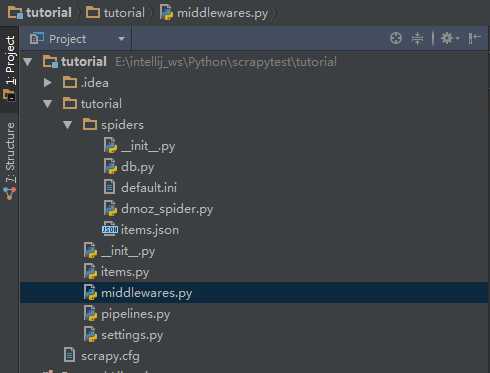
注:spiders目录下多了3个文件,db.py,default.init和items.json。db.py是我简单封装的一个数据库访问的lib文件,default.init是我的数据库和代理相关的配置文件,items.json是最后的输出文件。
给请求添加代理有2种方式,第一种是重写你的爬虫类的start_request方法,第二种是添加download中间件。下面会分别介绍这2种方式。
我在我的爬虫类中重写了start_requests方法:

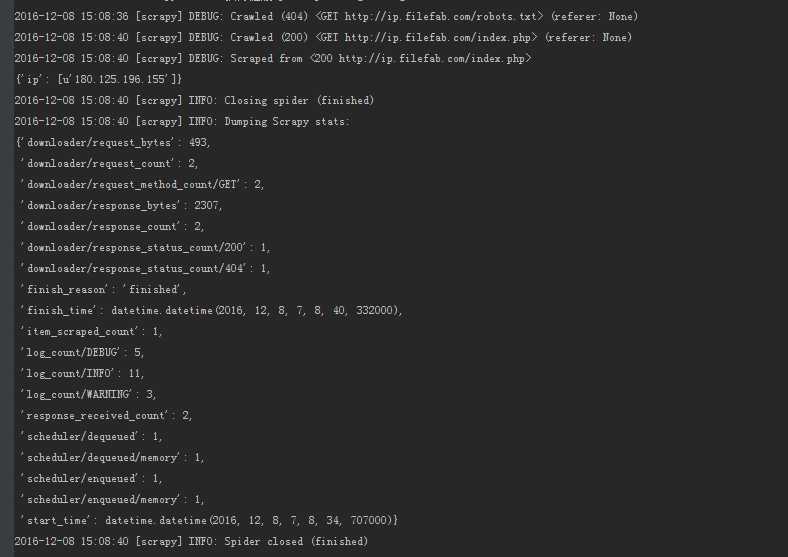
比较简单,只是在meta中加了一个proxy代理。然后可以测试了,那么问题来了,我怎么知道我的请求是否带上了代理呢?可以在测试的时候去爬 "http://ip.filefab.com/index.php" 这个网站,它会显示你当前访问ip地址。一切准备就绪了,我在我的intellij控制台中输入命令: cd /spider和scrapy crawl dmoz,然后控制台打印:
需要注意的一点是,在使用那种Basic认证的代理ip时,scrapy不同于python的requests包,这里不能直接把用户名和密码与代理ip放在一起。假设我这里使用一个基于Basic认证的代理ip,比如:http://username:passwd@180.125.196.155,把上述代码简单的改成:meta={‘proxy‘: ‘http://username:passwd@180.125.196.155‘} 是不正确的:

它会给你报一个407的错误(在可为此请求提供服务之前,您必须验证此代理服务器。请登录到代理服务器,然后重试)。正确的做法是将验证消息加到header的Proxy-Authorization中:
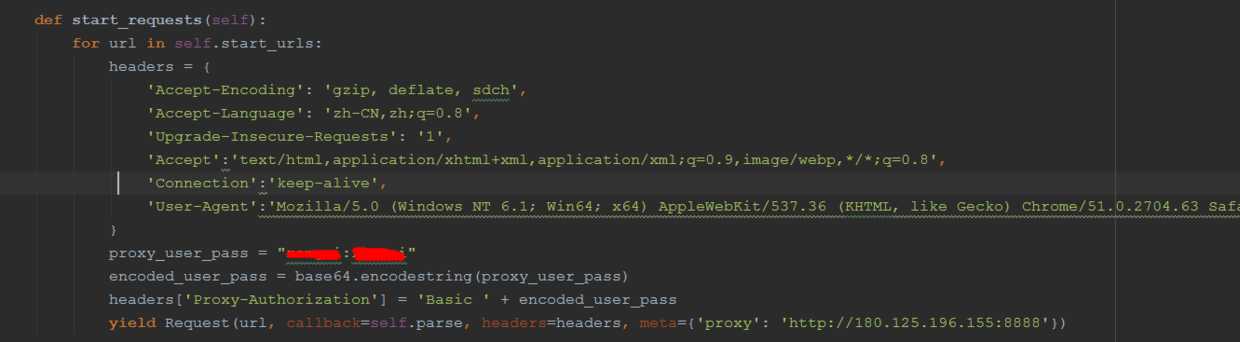
红色的部分填用户名和密码,这样就解决了,这里也看到了请求的header信息也是在这里添加的~
在middlewares.py中增加一个类,取名:ProxyMiddleware即代理中间件:
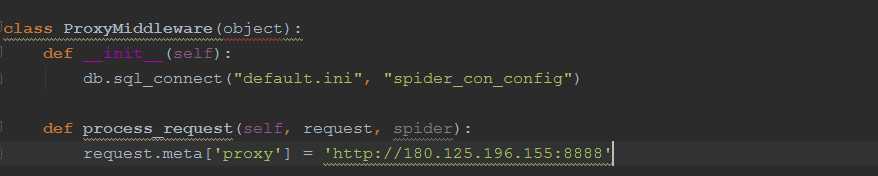
这里的初始化方法可以忽略,是我业务上的需求,主要是看这里的process_request方法,加了一个代理,然后在settings中配置这个中间件:

这里的数字是中间件的一个唯一编号,可以随意指定,只要不重复就行。然后同样在控制台中启动爬虫,没有问题~,同样的,对于Basic认证的代理ip同样可以在这里设置,header通过process_request的request方法取到。
标签:技术 res 使用 tin ini 不能 打印 方式 方法
原文地址:http://www.cnblogs.com/hsp-77-abc/p/6145659.html