标签:并且 error options first 代码 sort img iss pdv
数据集中的数据来源分为两种:
一、来自于另一个数据集;
二、来自于外部数据源(本文细说此来源);
无论是哪种来源,在它们成为目标数据集中的观测行(官方叫它observation)之前都要进入PDV,先成为准观测行。
这里可以形象的把PDV 看作一个数据容器,在该容器中的数据即将成为目标数据集中的观测。先来一段小程序如下:
OPTIONS USER=TEMP LS=MAX PS=MAX NOCENTER; DATA A; INPUT X1 X2; CARDS; 1 2 3 4 5 . . 6 ; RUN; DATA B C D; IF _N_=1 THEN OUTPUT B; IF _N_=2 THEN OUTPUT C; SET A; IF _N_=1 THEN OUTPUT D; Y=X1+X2; RUN; PROC PRINT DATA=A; RUN; PROC PRINT DATA=B; RUN; PROC PRINT DATA=C; RUN; PROC PRINT DATA=D; RUN;
运行一段代码可以分两个阶段:编译阶段和执行阶段。而PDV这个容器的建立就是在编译阶段了,上面这段程序编译时就创建好了PDV容器,而在PDV成型之前就现在当前的DATA步里面搜索存在的变量(包括SET语句中数据集的变量),同时也获取每个变量的类型,长度等。继而PDV会存好每个变量的名称,并预留存放数据的空间。
在第二个DATA步中的PDV为:

其中_N_和_ERROR_是两个自动的变量,在存入目标数据集后会自动消失,_N_记录当前的记录条数,_ERROR_标记当前有无错误字段。
以上为编译阶段,下面是执行阶段。
在执行一开始,就为PDV各空间进行赋值,制为:

因为是第一条准观测,所以其中_N_为1,开始默认没有错误,所以 _ERROR_为0,其余的个变量值通通置为MISSING状态值。
代码中的B数据集由于还没走到SET步就被输出,所以变量都还没有赋值,所以B数据集中只有一条观测值,并且都为空 ,如图:
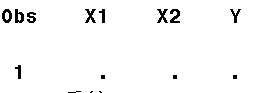
程序继续走到IF _N_=2步满足条件,继续走到SET语句,给X1 X2赋值,走到IF _N_=1这条语句,此时PDV状态为如图:

故数据集D输出为:
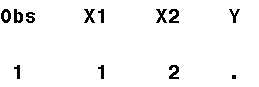
然后走到Y运算语句,继而给Y进行赋值,此时PDV状态为如图:

走到下一步到RUN语句,由于前面程序中出现了OUTPUT语句,所以在RUN语句执行时,不输出。
然后到了第二轮执行了。进入DATA步,_N_置为2,_ERROR_先置为0,而,SET数据集中出现的变量值不变(自带RETIAN功能!!!),然而DATA步中新建的变量要被置为MISSING状态,所以此时PDV状态为:
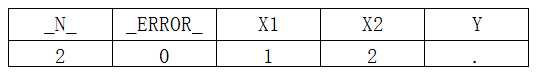
说明此状态是还没有走到SET语句时的状态!还仅仅是第二轮的初始状态,走到了IF _N_=2时,C数据集的输出结果为:

走到SET语句时PDV中内容替换了X1,X2的值为:3 4。PDV的状态为:

当执行到Y运算时Y的置才有MISSING 值替换为7,PDV为:

接下来一次类推。
注意,SET数据集中的字段有自带的RETIAN功能,而DATA步中新建的变量PDV都会认为初始值为MISSING值。
说到PDV,还有一点关于PDV的应用,first.X1
OPTIONS USER=TEMP LS=MAX PS=MAX NOCENTER; DATA A; INPUT X1 X2; CARDS; 1 2 1 3 1 5 3 4 4 7 3 0 4 8 3 9 5 0 . 6 ; RUN; PROC SORT; BY X1 X2; RUN; DATA B; SET A; BY X1; IF FIRST.X1; RUN; PROC PRINT; RUN;
以上的代码中,因为DATA步中出现了BY语句,所有PDV会总动在末尾创建两个临时变量名为:FIRST.X1和LAST.X1。若当前观测是以X1变量一组中的第一条观测时,FIRST.X1置为1否则为0。LAST.X1同理,如当前观测为一组中的最后一个观测则置为1,否则为0。可想象所有PDV合起来是如下图所示的:
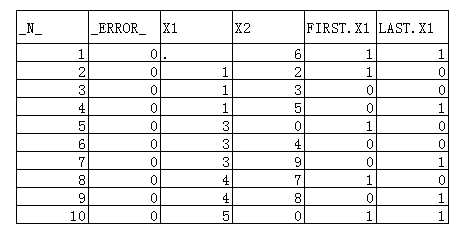
DATA步中有IF语句筛选FIRST.X1为>0的观测,所以执行结果如下:

标签:并且 error options first 代码 sort img iss pdv
原文地址:http://www.cnblogs.com/immaculate/p/6159901.html