标签:person https 分派 字段 when 单位 内存不足 区别 order
版权声明:本文由黄辉原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/259
来源:腾云阁 https://www.qcloud.com/community
之前对GreenPlum与Mysql进行了TPC-H类的对比测试,发现同等资源配比条件下,GreenPlum的性能远好于Mysql,有部分原因是得益于GreenPlum本身采用了更高效的算法,比如说做多表join时,采用的是hash join方式。如果采用同样高效的算法,两者的性能又如何?由于GreenPlum是由PostgreSQL演变而来,完全采用了PostgreSQL的优化算法,这次,我们将GreenPlum与PostgreSQL进行对比测试,在同等资源配比条件下,查看GreenPlum(分布式PostgreSQL)和单机版PostgreSQL的性能表现。
测试环境:腾讯云
测试对象:GreenPlum、PostgreSQL,两者的配置信息统计如下:
表1 GreenPlum集群服务器
| Master Host | Segment Host | Segment Host | |
|---|---|---|---|
| 操作系统 | CentOS 6.7 64位 | CentOS 6.7 64位 | CentOS 6.7 64位 |
| CPU | Intel(R) Xeon(R) CPU E5-26xx v3 2核 | Intel(R) Xeon(R) CPU E5-26xx v3 2核 | Intel(R) Xeon(R) CPU E5-26xx v3 2核 |
| 内存 | 8GB | 8GB | 8GB |
| 公网带宽 | 100Mbps | 100Mbps | 100Mbps |
| IP | 123.207.228.40 | 123.207.228.21 | 123.207.85.105 |
| Segment数量 | 0 | 2 | 2 |
| 版本 | greenplum-db-4.3.8.1-build-1-RHEL5-x86_64 | greenplum-db-4.3.8.1-build-1-RHEL5-x86_64 | greenplum-db-4.3.8.1-build-1-RHEL5-x86_64 |
表2 PostgreSQL服务器
| 指标 | 参数 |
|---|---|
| 操作系统 | CentOS 6.7 64位 |
| cpu | Intel(R) Xeon(R) CPU E5-26xx v3 8核 |
| 内存 | 24GB |
| 公网带宽 | 100Mbps |
| IP | 119.29.229.209 |
| 版本 | PostgreSQL 9.5.4 |
1.总测试数据量为1G时
结果统计信息如下:
表3 总量为1GB时各测试表数据量统计
| 表名称 | 数据条数 |
|---|---|
| customer | 150000 |
| lineitem | 6001215 |
| nation | 25 |
| orders | 1500000 |
| part | 200000 |
| partsupp | 800000 |
| region | 5 |
| supplier | 10000 |
表4 总量为1GB时22条sql执行时间统计
| 执行的sql | GeenPlum执行时间(单位:秒) | PostgreSQL执行时间(单位:秒) |
|---|---|---|
| Q1 | 4.01 | 12.93 |
| Q2 | 0.50 | 0.62 |
| Q3 | 1.35 | 1.29 |
| Q4 | 0.11 | 0.52 |
| Q5 | 0.19 | 0.72 |
| Q6 | 0.01 | 0.79 |
| Q7 | 6.06 | 1.84 |
| Q8 | 1.46 | 0.59 |
| Q9 | 4.00 | 7.04 |
| Q10 | 0.14 | 2.19 |
| Q11 | 0.30 | 0.18 |
| Q12 | 0.08 | 2.15 |
| Q13 | 1.04 | 4.05 |
| Q14 | 0.04 | 0.42 |
| Q15 | 0.07 | 1.66 |
| Q16 | 0.51 | 0.80 |
| Q17 | 3.21 | 23.07 |
| Q18 | 14.23 | 5.86 |
| Q19 | 0.95 | 0.17 |
| Q20 | 0.16 | 3.10 |
| Q21 | 7.23 | 2.22 |
| Q22 | 0.96 | 0.28 |
分析:从以上的表4可以看出,PostgreSQL在22条sql中有8条sql的执行时间比GreenPlum少,接近一半的比例,我们直接放大10倍的测试数据量进行下一步测试。
2.总测试数据量为10G时
结果统计如下:
表5 总量为10GB时各测试表数据量统计
| 表名称 | 数据条数 |
|---|---|
| customer | 1500000 |
| lineitem | 59986052 |
| nation | 25 |
| orders | 15000000 |
| part | 2000000 |
| partsupp | 8000000 |
| region | 5 |
| supplier | 100000 |
表6 总量为10GB时22条sql执行时间统计
| 执行的sql | GeenPlum执行时间(单位:秒) | PostgreSQL执行时间(单位:秒) |
|---|---|---|
| Q1 | 36.98 | 130.61 |
| Q2 | 3.10 | 17.08 |
| Q3 | 14.39 | 117.83 |
| Q4 | 0.11 | 6.81 |
| Q5 | 0.20 | 114.46 |
| Q6 | 0.01 | 11.08 |
| Q7 | 80.12 | 42.96 |
| Q8 | 6.61 | 45.13 |
| Q9 | 49.72 | 118.36 |
| Q10 | 0.16 | 40.51 |
| Q11 | 2.28 | 3.06 |
| Q12 | 0.08 | 21.47 |
| Q13 | 19.29 | 68.83 |
| Q14 | 0.05 | 36.28 |
| Q15 | 0.09 | 23.16 |
| Q16 | 6.30 | 12.77 |
| Q17 | 134.22 | 127.79 |
| Q18 | 168.03 | 199.48 |
| Q19 | 6.25 | 1.96 |
| Q20 | 0.54 | 52.10 |
| Q21 | 84.68 | 190.59 |
| Q22 | 17.93 | 2.98 |
分析:放大数据量到10G后可以明显看出,PostgreSQL执行测试sql的时间大幅度增多,性能下降比较厉害,但仍有3条测试sql快于GreenPlum,我们选取其中一条对比查看下两者的性能区别原因。
这里我们以Q7为例,Greenplum的执行时间大约是PostgreSQL的两倍,Q7如下: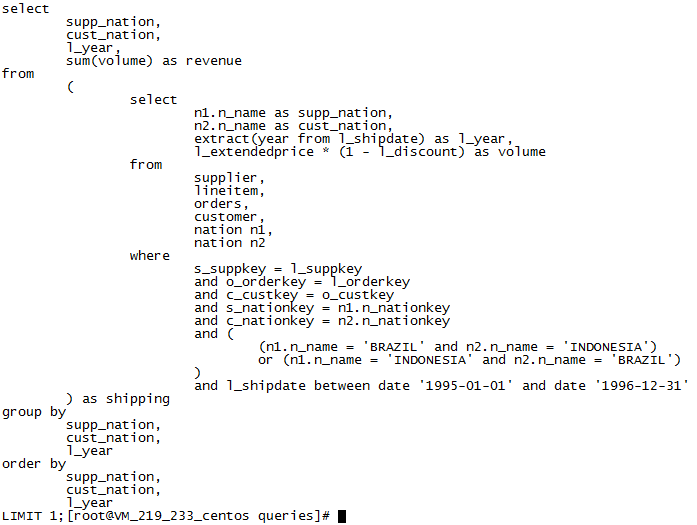
图1 Q7表示的sql语句
在PostgreSQL上执行explain Q7,得到结果如下: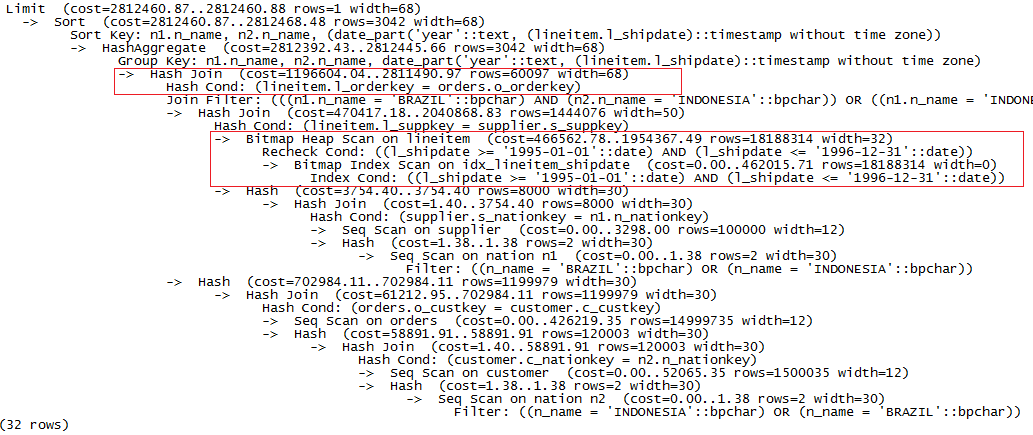
图2 数据量为10G时PostgreSQL上执行explain Q7的结果
对执行进行分析,可以看出,整个过程最耗时的部分如上图红色框部分标识,对应的条件查询操作分别是:
1).在lineitem表上对l_shipdata字段按条件查询,因为在字段有索引,采用了高效的Bitmap索引查询(Bitmap索引查询分两步:1.建位图;2.扫表。详细了解可看http://kb.cnblogs.com/page/515258/ )。
2).lineitem和orders表hash join操作。
为了方便进一步分析,我们加上analyze参数,获取详细的执行时间,由于内容过多,这里只截取部分重要信息如下:

图3 数据量为10G时PostgreSQL上执行explain analyze Q7的部分结果
根据以上信息,我们可以得出这两部分操作的具体执行时间,但由于PostgreSQL采取多任务并行,因此,我们需要对每步操作计算出一个滞留时间(该时间段内系统只执行该步操作),缩短滞留时间可直接提升执行速度,每步的滞留时间为前步的结束时间与该步结束时间之差。两部分的滞留时间分别为:
1).Bitmap Heap Scan:20197-2233=17964ms
2).Hash join:42889-26200=16689ms
PostgreSQL执行Q7的总时间为42963ms,因此,可以印证系统的耗时主要集中在上述两步操作上。
接下来,我们在GreenPlum上执行explain Q7,结果如下:
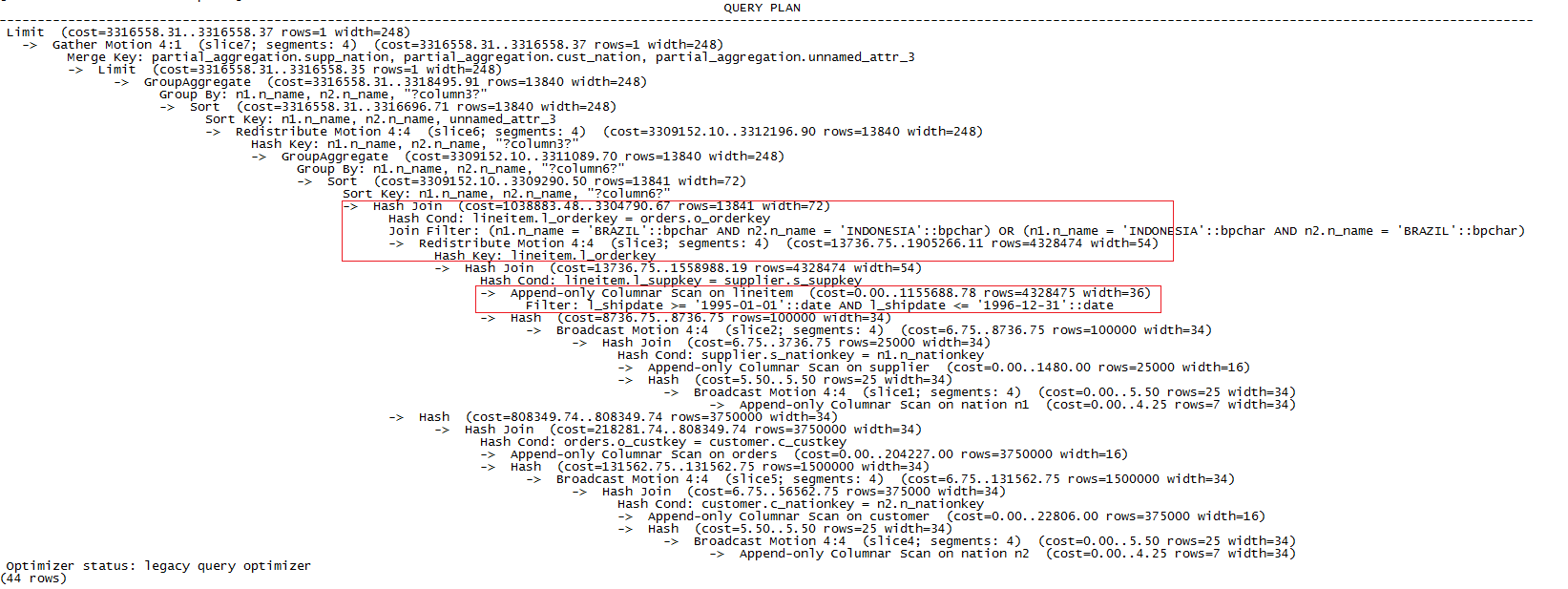
图4 数据量为10G时GreenPlum上执行explain Q7的结果
与PostgreSQL不同的是,GreenPlum的耗时多了数据重分布部分。同样,我们通过analyze参数得到详细的执行时间如下: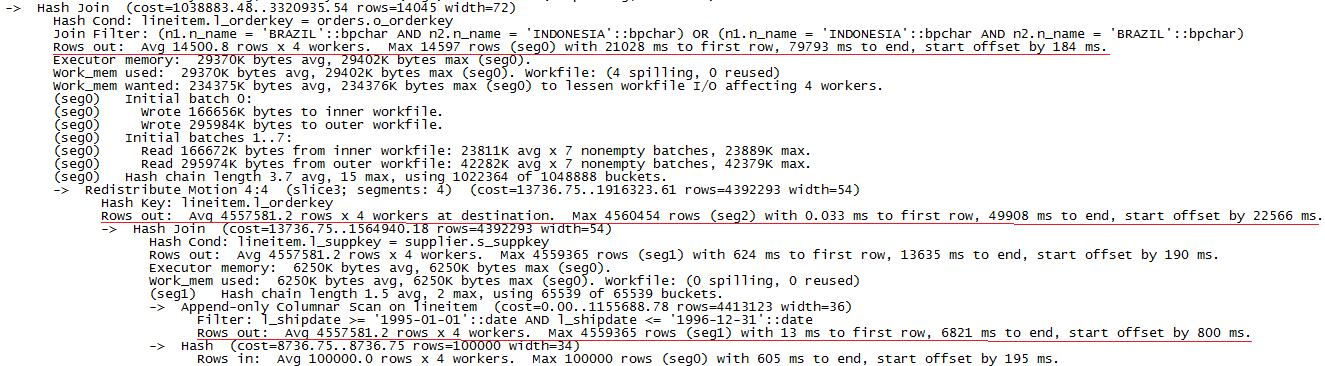
图5 数据量为10G时GreenPlum上执行explain analyze Q7的部分结果
根据执行计划信息,选出耗时最长的三步操作,计算出在一个segment(耗时最长的)上这三部分的滞留时间为:
1).Scan lineitem: 6216ms
2).Redistribute: 36273ms
3).Hash join: 29885ms
GreenPlum执行Q7的总时间为80121ms,可见数据重分布的时间占据了整个执行时间的一半,进行Hash join操作的时间占比也较多,主要是segment的内存不足,引起了磁盘的IO。
小结:对比PostgreSQL和GreenPlum在Q7的执行计划,GreenPlum的耗时较多的原因主要是数据重分布的大量时间消耗和hash join时超出内存引起磁盘IO。虽然GreenPlum各segment并行扫lineitem表节省了时间,但占比较小,对总时间的消耗影响较小。
基于此,是否可以减少数据重分布操作的耗时占比?我们尝试进一步增加测试的数据量,比较10G的测试数据对于真实的OLAP场景还是过少,扩大5倍的测试量,继续查看耗时情况是否有所改变。
3. 总测试数据量为50G时
表7 总量为50GB时各测试表数据量统计
| 表名称 | 数据条数 |
|---|---|
| customer | 7500000 |
| lineitem | 300005811 |
| nation | 25 |
| orders | 75000000 |
| part | 10000000 |
| partsupp | 40000000 |
| region | 5 |
| supplier | 500000 |
表8 总量为50GB时22条sql执行时间统计
| 执行的sql | GeenPlum执行时间(单位:秒) | PostgreSQL执行时间(单位:秒) |
|---|---|---|
| Q1 | 212.27 | 802.24 |
| Q2 | 16.53 | 164.20 |
| Q3 | 156.31 | 2142.18 |
| Q4 | 0.13 | 2934.76 |
| Q5 | 0.23 | 2322.92 |
| Q6 | 0.01 | 6439.26 |
| Q7 | 535.66 | 11906.74 |
| Q8 | 76.76 | 9171.83 |
| Q9 | 313.91 | >26060.36 |
| Q10 | 0.41 | 1905.13 |
| Q11 | 7.71 | 17.65 |
| Q12 | 0.19 | >3948.07 |
| Q13 | 108.05 | 354.59 |
| Q14 | 0.05 | 8054.72 |
| Q15 | 0.07 | >2036.03 |
| Q16 | 34.74 | 221.49 |
| Q17 | 862.90 | >9010.56 |
| Q18 | 913.97 | 3174.24 |
| Q19 | 129.14 | 8666.38 |
| Q20 | 2.28 | 9389.21 |
| Q21 | 1064.67 | >26868.31 |
| Q22 | 90.90 | 1066.44 |
分析:从结果表可明显看出,在22条SQL中,GreenPlum的执行效率都比PostgreSQL高出很多,我们还是以Q7为例,查看两种数据量下执行效率不一致的直接原因。
经过对执行计划的分析,发现区别还是集中在步骤2提到的几个部分,这里就不再重复给出整体的查询计划,直接查看耗时较多的部分如下:

图6 数据量为50G时PostgreSQL上执行explain analyze Q7的部分结果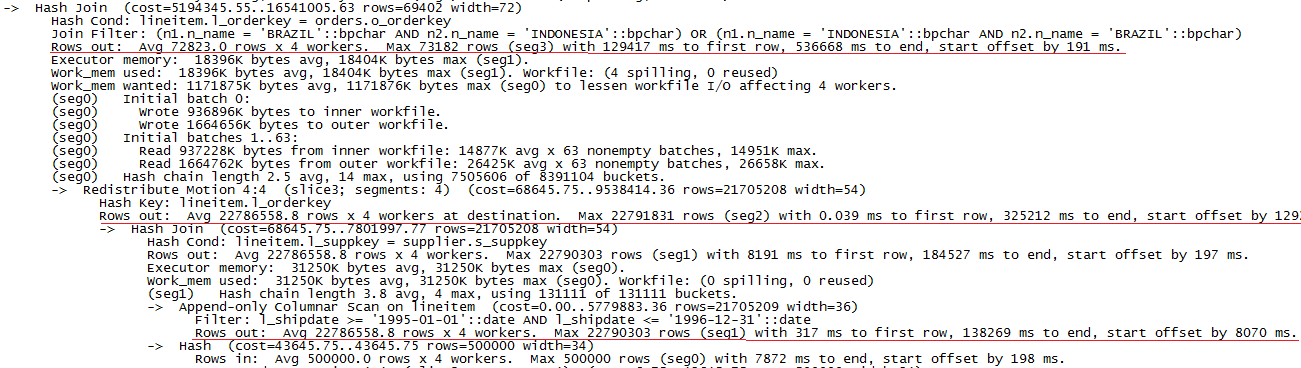
图7 数据量为50G时GreenPlum上执行explain analyze Q7的部分结果
PostgreSQL的主要滞留时间有:
1).Bitmap Heap Scan: 9290197ms
2).Hash join: 713138ms
总执行时间为10219009ms,可见主要的耗时集中在Bitmap Heap Scan上,
GreenPlum的主要滞留时间有:
1).Scan lineitem: 130397ms
2).Redistribute: 140685ms
3).Hash join: 211456ms
总的执行时间为537134ms,相比步骤2的10G测试数据量,数据重分布的耗时占比明显下降,主要耗时已集中在hash join操作上。
GreenPlum和PostgreSQL在执行同样的wheret条件时,扫表的方式不一样,原因在于GreenPlum里的lineitem表为列存储,直接扫表更方便更快。
对比PostgreSQL两次的测试结果,发现Bitmao Heap Scan操作的性能下降比较明显,第一次扫18188314 行用时17秒,而第二次扫90522811行用时9190秒。
小结:增大数据量,会减少数据重分布耗时对整体执行时间的影响比重,主要耗时集中在内部数据的计算上。由于扫表涉及到磁盘IO,GreenPlum将扫表任务分割给多个segment同时进行,减少了单个节点要执行的扫表量,相当于并行IO操作,对整体的性能提升较大。
通过对不同数据量(1G,10G,50G)的测试对比以及分析,可以看出,在TPC-H类的测试时,数据量越大,GreenPlum性能越好于单机版的PostgreSQL。由于GreenPlum采用分布式架构,为了实现各节点并行计算能力,需要在节点间进行广播或者数据重分布,对整体的性能有一定影响,当数据量较小时,计算量小,广播或者重分布耗时占总耗时比例大,影响整体的执行效率,可能会出现GreenPlum不如单机版PostgreSQL效率高;当数据量较大时,整体计算的量很大,广播或者重分布耗时不再是影响性能的关键因素,分布式属性的GreenPlum在关于复杂语句执行查询效率较高,原因在于,一是多节点同时进行计算(hash join、sort等),提升计算速度,且可以充分利用系统CPU资源;二是扫表时,将任务分派到多节点,减少了单个节点的IO次数,达到并行IO的目的,更适用于OLAP场景。
由于原生的TPC-H的测试用例不直接支持GreenPlum和PostgreSQL,因此需要修改测试脚本,生成新的建表语句如《附录一》所示,测试sql如《附录二》。
GreenPlum的数据导入可以使用GreenPlum自带的gpfdist工具,搭建多个gpfdsit文件服务器并行导入,但文件服务器的数量不能多于segment数量,这点官方文档并未说明。
GreenPlum:
BEGIN;
CREATE TABLE PART (
P_PARTKEY SERIAL8,
P_NAME VARCHAR(55),
P_MFGR CHAR(25),
P_BRAND CHAR(10),
P_TYPE VARCHAR(25),
P_SIZE INTEGER,
P_CONTAINER CHAR(10),
P_RETAILPRICE DECIMAL,
P_COMMENT VARCHAR(23)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (p_partkey);
COPY part FROM ‘/tmp/dss-data/part.csv‘ WITH csv DELIMITER ‘|‘;
COMMIT;
BEGIN;
CREATE TABLE REGION (
R_REGIONKEY SERIAL8,
R_NAME CHAR(25),
R_COMMENT VARCHAR(152)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (r_regionkey);
COPY region FROM ‘/tmp/dss-data/region.csv‘ WITH csv DELIMITER ‘|‘;
COMMIT;
BEGIN;
CREATE TABLE NATION (
N_NATIONKEY SERIAL8,
N_NAME CHAR(25),
N_REGIONKEY BIGINT NOT NULL, -- references R_REGIONKEY
N_COMMENT VARCHAR(152)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (n_nationkey);
COPY nation FROM ‘/tmp/dss-data/nation.csv‘ WITH csv DELIMITER ‘|‘;
COMMIT;
BEGIN;
CREATE TABLE SUPPLIER (
S_SUPPKEY SERIAL8,
S_NAME CHAR(25),
S_ADDRESS VARCHAR(40),
S_NATIONKEY BIGINT NOT NULL, -- references N_NATIONKEY
S_PHONE CHAR(15),
S_ACCTBAL DECIMAL,
S_COMMENT VARCHAR(101)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (s_suppkey);
COPY supplier FROM ‘/tmp/dss-data/supplier.csv‘ WITH csv DELIMITER ‘|‘;
COMMIT;
BEGIN;
CREATE TABLE CUSTOMER (
C_CUSTKEY SERIAL8,
C_NAME VARCHAR(25),
C_ADDRESS VARCHAR(40),
C_NATIONKEY BIGINT NOT NULL, -- references N_NATIONKEY
C_PHONE CHAR(15),
C_ACCTBAL DECIMAL,
C_MKTSEGMENT CHAR(10),
C_COMMENT VARCHAR(117)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (c_custkey);
COPY customer FROM ‘/tmp/dss-data/customer.csv‘ WITH csv DELIMITER ‘|‘;
COMMIT;
BEGIN;
CREATE TABLE PARTSUPP (
PS_PARTKEY BIGINT NOT NULL, -- references P_PARTKEY
PS_SUPPKEY BIGINT NOT NULL, -- references S_SUPPKEY
PS_AVAILQTY INTEGER,
PS_SUPPLYCOST DECIMAL,
PS_COMMENT VARCHAR(199)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (ps_partkey,ps_suppkey);
COPY partsupp FROM ‘/tmp/dss-data/partsupp.csv‘ WITH csv DELIMITER ‘|‘;
COMMIT;
BEGIN;
CREATE TABLE ORDERS (
O_ORDERKEY SERIAL8,
O_CUSTKEY BIGINT NOT NULL, -- references C_CUSTKEY
O_ORDERSTATUS CHAR(1),
O_TOTALPRICE DECIMAL,
O_ORDERDATE DATE,
O_ORDERPRIORITY CHAR(15),
O_CLERK CHAR(15),
O_SHIPPRIORITY INTEGER,
O_COMMENT VARCHAR(79)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (o_orderkey);
COPY orders FROM ‘/tmp/dss-data/orders.csv‘ WITH csv DELIMITER ‘|‘;
COMMIT;
BEGIN;
CREATE TABLE LINEITEM (
L_ORDERKEY BIGINT NOT NULL, -- references O_ORDERKEY
L_PARTKEY BIGINT NOT NULL, -- references P_PARTKEY (compound fk to PARTSUPP)
L_SUPPKEY BIGINT NOT NULL, -- references S_SUPPKEY (compound fk to PARTSUPP)
L_LINENUMBER INTEGER,
L_QUANTITY DECIMAL,
L_EXTENDEDPRICE DECIMAL,
L_DISCOUNT DECIMAL,
L_TAX DECIMAL,
L_RETURNFLAG CHAR(1),
L_LINESTATUS CHAR(1),
L_SHIPDATE DATE,
L_COMMITDATE DATE,
L_RECEIPTDATE DATE,
L_SHIPINSTRUCT CHAR(25),
L_SHIPMODE CHAR(10),
L_COMMENT VARCHAR(44)
) with (APPENDONLY=true,BLOCKSIZE=2097152,ORIENTATION=COLUMN,CHECKSUM=true,OIDS=false) DISTRIBUTED BY (l_orderkey, l_linenumber);
COPY lineitem FROM ‘/tmp/dss-data/lineitem.csv‘ WITH csv DELIMITER ‘|‘;
COMMIT;
PostgreSQL:
BEGIN;
CREATE TABLE PART (
P_PARTKEY SERIAL,
P_NAME VARCHAR(55),
P_MFGR CHAR(25),
P_BRAND CHAR(10),
P_TYPE VARCHAR(25),
P_SIZE INTEGER,
P_CONTAINER CHAR(10),
P_RETAILPRICE DECIMAL,
P_COMMENT VARCHAR(23)
);
COPY part FROM ‘/tmp/dss-data-copy/part.csv‘ WITH csv DELIMITER ‘|‘;