标签:使用 des reader 生成 注意 不能 技术分享 原理 lin
版权声明:本文由熊训德原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/258
来源:腾云阁 https://www.qcloud.com/community
本文档从源码角度分析了,hbase作为dfs client写入hdfs的hadoop sequence文件最终刷盘落地的过程。
之前在《wal线程模型源码分析》中描述wal的写过程时说过会写入hadoop sequence文件,hbase为了保证数据的安全性,一般都是写入同为hadoop生态的hdfs(Hadoop Distribute File System)中。append的最终结果是使用write.append()写入,而sync()则是使用write.sync()刷盘。这时其实并未真正的结束,为了保障数据安全性,hdfs可会根据用户的配置写到多个datanode节点中,不管是HFile还是FSHLog都不仅仅是简单的写入或刷入(flush)了真正的存储节点--DataNode中,其中涉及到数据流(WALEntry)如何安全有序且高效地写到datanode文件中,而flush又是具体如何做的,这个文档就将从源码上分析hbase的“写”操作到了wirter.append()和writer.sync()后具体发生了什么,如何落地的。
下图是《Hbase权威指南》中描述Hbase底层存储结构的顶层结构图。可以看到Hbase将处理HFile文件(memstore生成)和HLog文件(WAL生成)这两种文件都将有HRegionServer管理,当真正存储到HDFS中时,会使用DFS Client作为hdfs的客户端把大批量的这两种数据流写到多个DataNode节点中。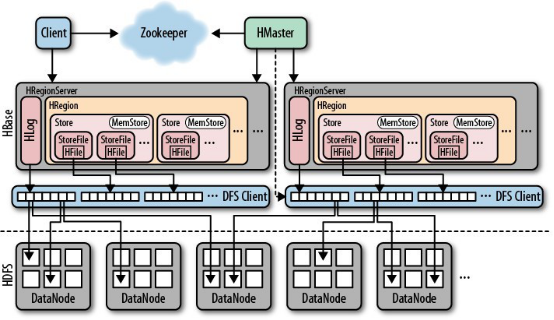
在文档 《wal线程模型源码分析》中为了突出重点说明wal线程模型,并未具体说明writer.append()和writer.sync()中writer实例是什么,在FSHLog中被volatile关键字修饰声明为一个WALProvider.Writer类型的接口:
其实它的实现类是ProtobufLogWriter,这个类也在org.apache.hadoop.hbase.regionserver.wal包中,在wal包中是作为wal向datanode的writer,它在FSHLog是使用工厂模式createWriterInstance()实例化,然后调用init()方法初始化:
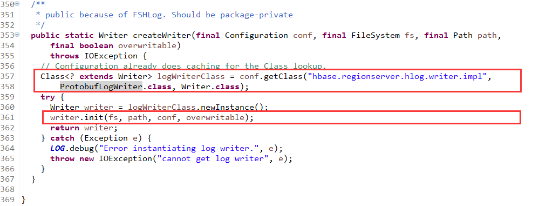
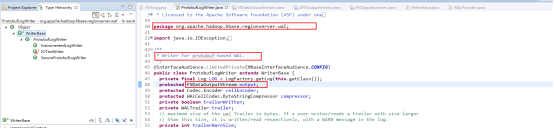
从源码中可以看到真正写实例是FSDataOutputStream,它用于向新生成的文件中写入数据,就像前面叙述的,在ProtobufLogWriter的init()方法中被初始化:
在这里我们仅仅讨论使用hdfs作为hbase的文件系统,也即是init参数中fs(System)是DistributedFileSystem的实例。在其createNonRecursive的实现的参数除了path参数指明需要在hdfs创建的文件路径比较重要以外,还有一个replication参数也很重要,这个参数说明了备份数量也即是写datanode份数。DistributedFileSystem中dfs是DFSClient的实例引用,也即最开始那张架构图中所指的DFS Client。hbase使用DFSClient的create方法通过RPC调用向hdfs的namenode创建一个文件并构造了输出流DFSOutputStream实例,这个方法另外一个重点就启动了一个pipeline,具体调用是streamer.start(),这个pipleline是hbase向hdfs的多个datanode管道写的实现。虽然这里分析的是wal的写入过程,但是其实keyvalue写到memstore,再写到HFile后也是采用这种方式管道写(pipeline)的方式实现。
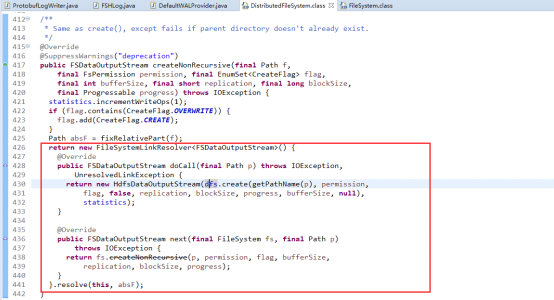
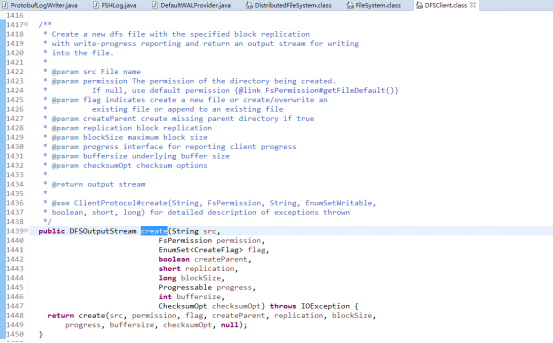
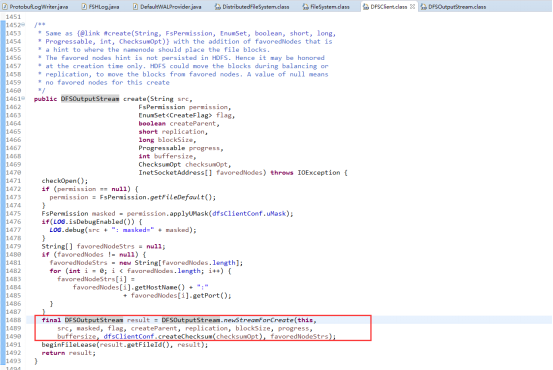
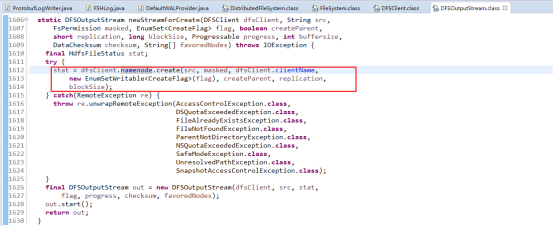
通过rpc调用NameNode的create函数,调用namesystem.startFile函数,其又调用startFileInternal函数,它创建一个新的文件,状态为under construction,没有任何data block与之对应。于此同时创建成功后会返回一个DFSOutputStream类型的实例,在FSDataOutputStream中被称作wrappedStream,该对象负责处理datanode和namenode之间的通讯。
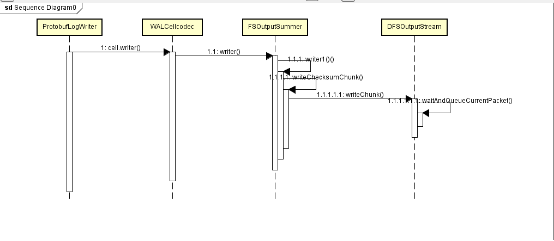
hdfs的文件结构,HDFS一个文件由多个block(默认64MB)构成。这里通过注释可以看到HDFS在进行block读写的时候是以packet(默认每个packet为64K)为单位进行的。每一个packet由若干个chunk(默认512Byte)组成。Chunk是进行数据校验的基本单位,对每一个chunk生成一个校验和(默认4Byte)并将校验和进行存储。
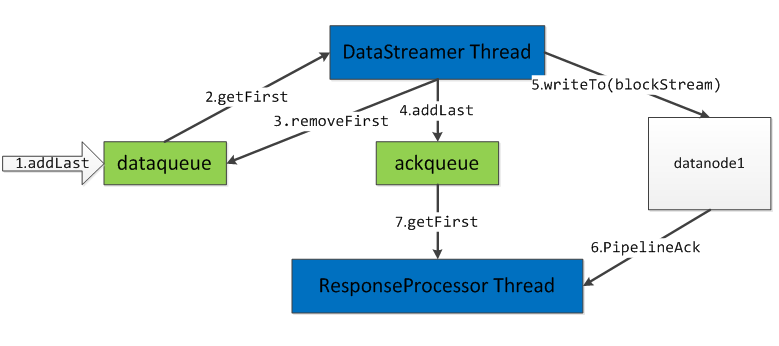
分析到这,已经可以看出hbase文件写入hdfs的过程并没有特别,hdfs就把hbase当做hdfs的client然后封装成chunk再组装成packet,再向datanode批量写数据。为了保证数据有序的传输,使用了数据发送队列dataqueue和待确认队列ackqueue,并使用两个线程DFSOutputStream$DataStreamer和DFSOutputStream$DataStreamer$ResponseProcessor(在run()中)分别来发送数据到对应block和确认数据是否到达。
还有另外一个重点就是hbase是如何把数据到datanode的磁盘的。
在此,我们又要回到ProtobufLogWriter类中因为writer.sync()最终调用的就是ProtobufLogWriter的writer方法,它的源码如下: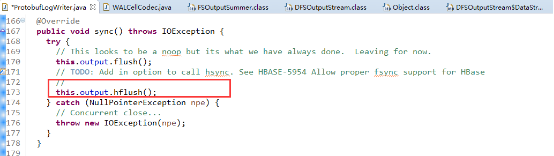
其中,output在就是之前分析过的FSDataOutputStream的实例,在sync()方法中调用了FSDataOutputStream的flush和hflush,其实flush什么都没做(noop,源码中也说明了),hflush()则会调用也是前面提过的DFSOutputStrem类的hflush方法,hflush方法将Client缓存的所有数据(packet)立即发送给Datanodes,并阻塞直到它们写入成功为止。hflush之后,可以确保Client端故障不会导致数据丢失,但如果Datanodes失效仍有丢失数据的可能,当FSDataOutputStream关闭时也会额外的执行一次flush操作:
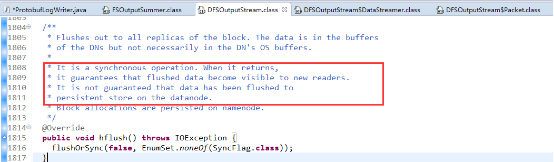
就像注释中所解释的一样,hflush是同步的只能保证能让新reader能看到,但是并不能保证其真正的持久化到了每个datanode中,也即没真的调用posix中的fsync()系统调用。它只是将client端写入的数据刷到每个DataNode的OS缓存(store)中,如果每个副本所在的DataNode同时crash时(例如机房断电)将会导致数据丢失。
hdfs给客户端还提供了另外一种语义hsync:client端所有的数据都发送到副本的每个datanode上,并且datanode上的每个副本都完成了posix中fsync的调用,也就是说操作系统已经把数据刷到磁盘上(当然磁盘也可能缓冲数据);需要注意的是当调用fsync时只有当前的block会刷到磁盘中,要想每个block都刷到磁盘,必须在创建流时传入Sync标示。
hbase当前选择的是hflush语义。这两种语义都调用的flushOrsync方法,其中hflush调用的isSync传入false,而hsync传入的是true。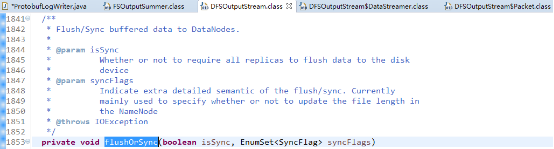
这个方法的主要作用就是把还在缓存(buffered )中的数据刷到datanodes中,
其中最终要的几个方法就是flushBuffer(),waitAndQueueCurrentPackket()和waitForAckedSeqno(),调用waitAndQueueCurrentPacket()将当前Package放到发送队列中waitForAckedSeqno()等待发送package的确认包,而其原理和写数据一样,就是把数据封装成chunk在把chunk一个个填充到package,再以pipeline的方式一个个写到datanode再根据是否有sync标识刷盘。
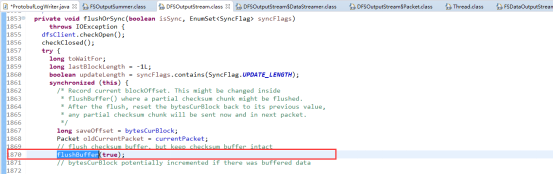
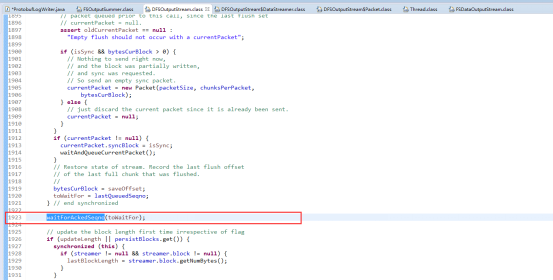
waitForAckedSeqno()就是用于等待ackqueue中的ack回来,并被唤醒。
标签:使用 des reader 生成 注意 不能 技术分享 原理 lin
原文地址:http://www.cnblogs.com/purpleraintear/p/6165606.html