标签:style blog http color java 使用 io strong
Hadoop学习笔记(9)
——源码初窥
之前我们把Hadoop算是入了门,下载的源码,写了HelloWorld,简要分析了其编程要点,然后也编了个较复杂的示例。接下来其实就有两条路可走了,一条是继续深入研究其编程及部署等,让其功能使用的淋漓尽致。二是停下来,先看看其源码,研究下如何实现的。在这里我就选择第二条路。
研究源码,那我们就来先看一下整个目录里有点啥:
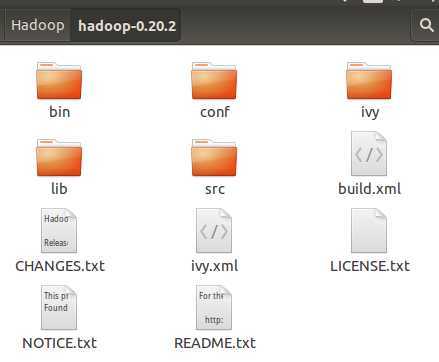
这个是刚下完代码后,目录列表中的内容。
|
目录/文件 |
说明 |
|
bin |
下面存放着可执行的sh命名,所有操作都在这里 |
|
conf |
配置文件所在目录 |
|
ivy |
Apache Ivy是专门用来管理项目的jar包依赖的,这个是ivy的主要目录 |
|
lib |
引用的库文件目录,里面存放用到的jar包 |
|
src |
这个里面就是主要的源码了 |
|
build.xml |
用于编译的配置文件。 编译我们用的是ant |
|
CHANGES.txt |
文本文件,记录着本版本的变更历史 |
|
ivy.xml |
Ivy的配置文件 |
|
LICENSE.txt |
文件本文件, |
|
NOTICE.txt |
文本文件,记录着需要注意的地方 |
|
README.txt |
说明文件。 |
进入src目录,我们看到了:
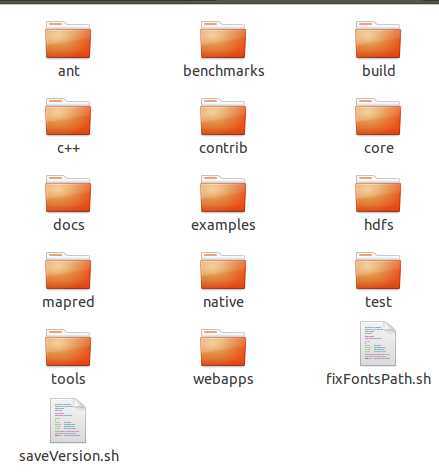
|
目录/文件 |
说明 |
|
ant |
为ant命令编写的扩展指定 |
|
benchmarks |
笔者也没弄明白L |
|
build |
就存放一个打包信息文件 |
|
c++ |
linux下amd64-64位系统以及i386-32位系统提供的库文件集合 |
|
contrib |
是开源界或第三方为hadoop编写的一些扩展程序,如eclipse插件等 |
|
core |
Hadoop的核心代码 |
|
docs |
文档 |
|
examples |
示例程序 |
|
hdfs |
HDFS模块的代码 |
|
marped |
MapReduce模块代码 |
|
native |
笔者也没弄明白L |
|
test |
测试程序 |
|
tools |
工具集 |
|
webapps |
网页管理工具的代码,主要是jsp文件。 |
|
fixFontsPath.sh |
用于修正字体路径的批处理命令。 |
|
saveVersion.sh |
用于生成打包信息文件批处理命令。 |
这些目录及文件命名及分布还是很清晰的,基本上根据命名也能猜出其意思来了。当我们拿到这些文件时,做了两件事,编译和运行,接下来我们一块块仔细来看看。
编译
当我们拿到手时,第一章中讲到,我们用了以下命令就完成了编译:
~/hadoop-0.20.2$ant
~/hadoop-0.20.2$ant jar
~/hadoop-0.20.2$ant examples
在编译完后,我们发现,目录中多了一个build文件夹。这个文件夹下,我们发现有大量的子文件夹,再深入看,可以找到了N多个.class文件。那这个正是java程序的编译产出物。
我们在第5章中,简要的描述了java程序与.net的差别。一个.java程序对应一个.class文件,手动的话用javac来编译。我们要将这么多的java文件都要编译成一个个的.class文件,敲javac命令肯定是不行的,我们得找个打包处理的办法。这个就是ant。简单的说ant就是将编译命名进行打包处理的程序,这个程序有一个配置文件就是build.xml。所以我们进入hadoop根目录后输入了ant后就开始运行了,因为它在当前目录下找到了build.xml文件。那ant能做啥,其实百度上一搜就有很多了。这里就不详述了。我们简要的来看一下build.xml。 打开一看,build.xml文件貌似很复杂,有1千8百多行。不要怕,简单看下:
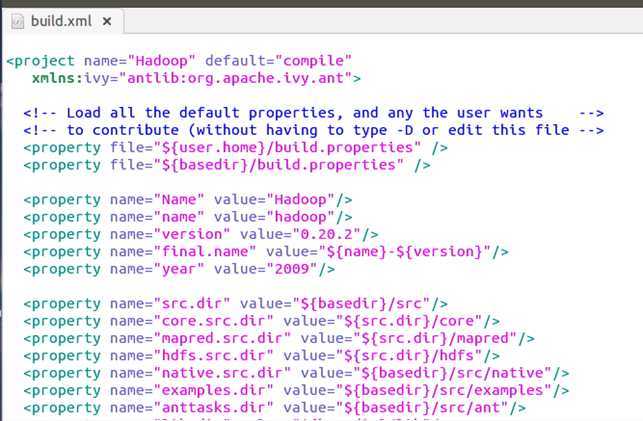
一上来,定义了一个project,看来这是一个工程,有名称和default属性(default后面看是啥)。
接下来发现是一堆的property,然后是name-value的健值。应该猜的出,这些就是后面真正执行用的一些变量或参数。
再往下,看到有这些:
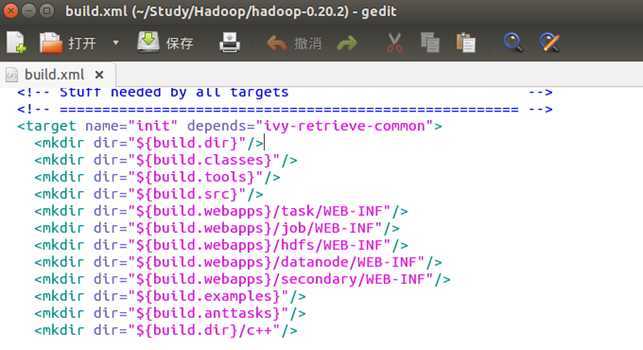
看到有target,然后取了个名,字面意思是目标,然后看看子结点,发现是mkdir,好熟悉的字眼,这不是在创建目录么,看下第一个dir是啥,${build.dir}。然后立即跑回上面property中,看下是否有呢?
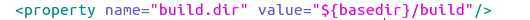
果然,这个就是在编译后的产生的目录,第一步创建之,很正常。
既然这样,这个target就是一个个目标,然后往下拖一下,发现下面的都是一个个的目录,全文搜索一下:
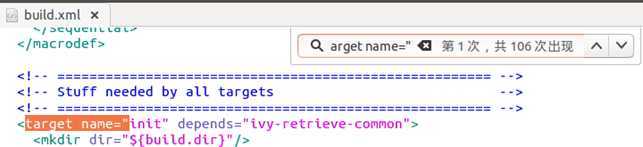
发现里面有106个。
继续搜,发现了亮点:
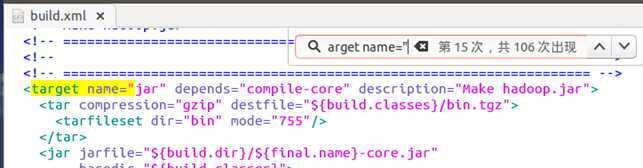
这个target(目标)好眼熟,~/hadoop-0.20.2$ant jar 没错,当时在编译时,输入这个命令后,就产出了一个jar文件。看来这个target就是在形成jar文件,略看下其子命令,的确就是在生成jar包了。
简单了解了这个target后,就可以继续找找,我们的examples命令了。现回想起来,在编译时第一个命令是~/hadoop-0.20.2$ant,而这个好象没有写target么?又想到了:

难道这个default就是传说中的默认目标? compile。 熬不住了,立即展开搜索:
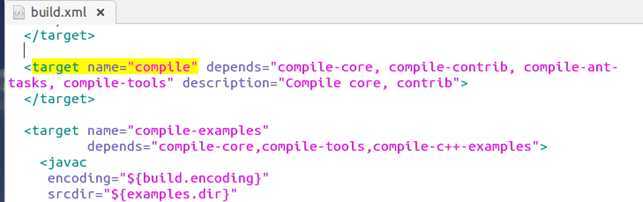
果然,猜的没错。找到了这个默认目录,然后发现好多target后还有depends,字面意思,依赖吧,然后可以继续找,依赖里面的目录,也是一个个的target。
了解了这个之后,我们又在想,现在知道的target也就 默认、jar、example,还有哪些呢,我们就可以搜target name="这个字符。当然会发现有很多,但是不是每个都对我们有用,因为好多是为了编写方便,将一个大的拆成多个小的,以便于维护。至于哪些有用的,这里我就不一一列出。可以自己看看。 比如clean就不错,可以把编译后的结果清理掉,还原到开始状态。
编译成.class包括jar包现在都没问题了。我们知道hadoop是用java写的,在src下可找到大量java类文件。难道这个hadoop就没有引用一个第三方的组件?答案是有的,一开始没看到几个,在lib下就只有几个。 但是在ant完后,在build下搜,发现有好多个jar文件。 哪来的? 下载的。谁负责下载的,为什么知道要下载这些文件?
我们发现,在build.xml中,第一个target init就有depends:

然后就可以一级级查到,是通用ivy进行下载的,至于下载哪些,在ivy.xml中就有配置。好了,这块并不是我们的重点,了解到这里就够了,反正所用到的lib文件都下来了。
运行
在第一章中,我们了解到启用整个hadoop,全到了这个命令:bin/start-all.sh,关闭是用到了bin/stop-all.sh。而这个又是什么文件,我们来研究一下看。
不急看start-all, 我们打开bin目录看一下:
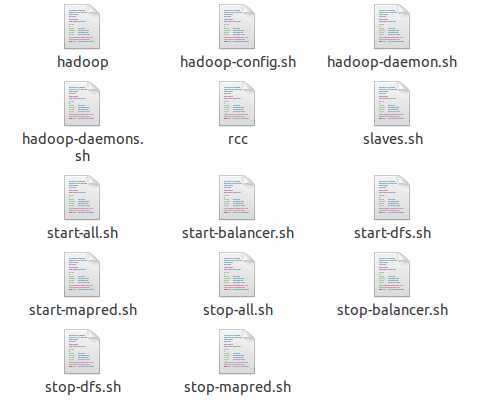
在bin下有很多个sh文件,hadoop这个命令,虽然没有后缀,但打开看后,发现跟其他sh文件样,类似的脚本。
什么是sh文件? 在windows中我们知道bat文件,就是将若干个命令放到一个文件中,依次执行,称之为批处理文件。在Linux中,这个bat文件就是sh文件了。
先不急着打开文件内容,我们观察下所以文件,看到下面8个,很有规律,4个startXXX.sh然后4个stopXXX.sh文件。看来这些就是用户启动和关闭hadoop用的。
打开start-all.sh,发现内容并不多,也很好理解:
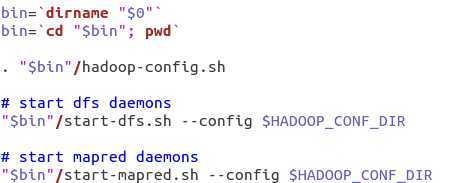
这里,先调了一下hadoop-config.sh,字面意思,设置配置文件。然后再调了start-dfs 和start-mapred。这里就很明显了,start-all是启动整个hadoop,然后里面包含了两个动作,启动dfs和mapreduce。 同理,如果我想只启动dfs,那么只需要运行start-dfs.sh即可。
同样,打开stop-all.sh文件,也可以看到比较简单,

发现是分别调了stop-mapred.sh和stop-dfs.sh这两个文件。
这里我们就不每个文件进行分析了,我们只挑几个关键文件看一下。
继续前行,打开start-dfs.sh和stop-dfs.sh文件,发现里面

和

大家可以打开其他所有的startXX和stopXX文件,发现所有的操作都又转入了hadoop-daemon.sh和hadoop-daemons.sh这两个命令,同时传入了参数—config stop/start 名称 (opt参数)。
继续,打开hadoop-daemons.sh,发现内容也很简单:

这里,先调用了slaves.sh后,又调回来hadoop-daemon.sh,所以现在目标焦点就只有两个了hadoop-daemon.sh和slaves.sh了。打开slaves.sh看一下:
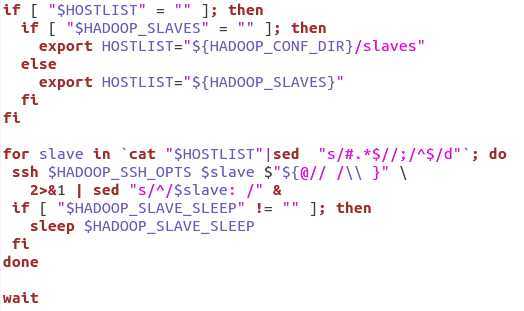
这个文件的字面意思应该就是启动各分布式子机的hadoop咯。看一下代码,第一个if与fi之间,可以看到是取得conf文件夹下的slaves文件。记得在配置分配布式里面,在slaves中配置写了是node1 node2用回车换行隔开。 所以第二段代码,for循环slaves中的文件,然后调用ssh命令,调到了子系统中的相应的命令,这里,就完全可以想通了,为什么子系统中部署的hadoop目录需要与主目录相同,然后slaves中配置的是子系统机器的名称。
到这里,整个bin目录的脚本,就集中在剩下的两个hadoop-daemon.sh和hadoop了。胜利在望了。先看hadoop-daemon.sh。

一开始,代码是在取参数,startstop和command,从前面的传入可以看到,startstop参数传的是start和stop,看来是启动和关闭, command是namenode、datanode之类的。
继续往下看:
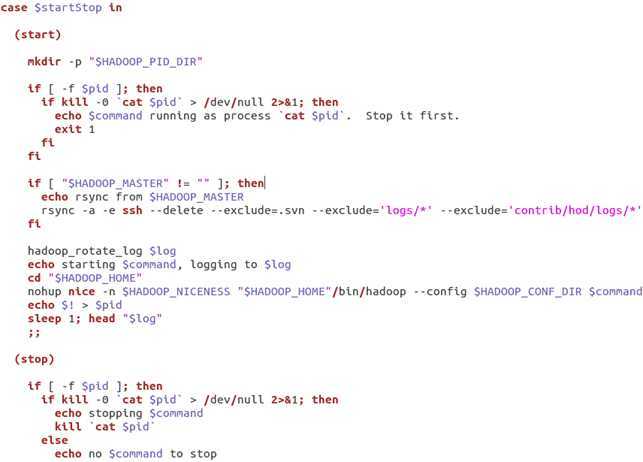
case语句下进行了分类,将start和stop命令分开处理。在start时,先是创建一个文件夹PID_DIR,具体值可以看上面,然后第一段if,是在判断进程有没有启动,然后最关健是执行nohup nice …. /bin/hadoop。也就是说归根到底又都是在执行hadoop命令了。这里nohup,是指启动进程后不被卡住,即转为后台进程,又称守护进程,所以该sh文件命名为daemon也不为过。
然后stop段时,把进程进行kill掉。这里有疑问了,启动的命令kill里需要知道进程的PID,而kill里哪里获取呢,在启动时,将启动进程后的pid记录在PID文件夹内,然后kill时就可以跟据这些PID来处理了。这块在代码中,也比较清晰的体现了。
在执行hadoop命令时,又将namenode、datanode、secondarynamenode等命令传入。所以现在可以打开hadoop命令文件了:(这里直接跳入重点看)

这里,看到有大量的if语句,条件是command判断,然后执行中对class和hadoop_opts进行了赋值。 继续往下看:(在最后)

我们发现,是在执行java命令,传入的main函数入口正是上面条件处理中的CLASS变量。换句话说,这个CLASS应该对应一个个的main函数咯? 验证一下,找一个,比如dataNode,其CLASS是org.apache.hadoop.hdfs.server.datanode.DataNode。按这路径在src中找到文件DataNode.java,打开,然后搜main:
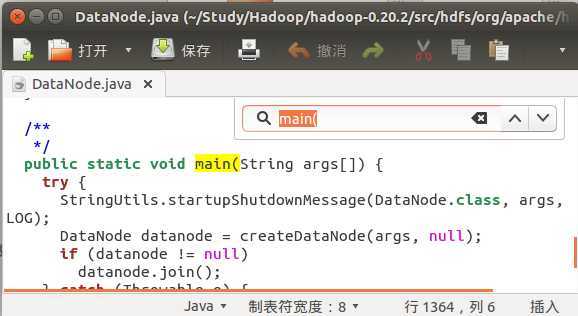
果然,完全应正了我们的想法。
总结一下:整个hadoop程序,是一个java为主的程序,在编译是将.class文件生成在build目录,在运行时,虽然执行的是.sh文件,但一步步,最终都是在执行java命令,传入的入口,就是各个子程序的main函数入口。
想法1:看了这个sh命令后,又有一个想法,之前通过starg-all.sh就把整个程序启动起来了,而且是在后台运行的,输出内容只能从log文件夹内看,能否直接从命令行启动呢? 当然行,输入 bin/hadoop namenode试试,果然,启动了namenode程序,然后日志信息也直接打印在屏幕上了。
想法2:既然从hadoop这个sh文件夹内,可以看到所有的入口,那就可以整理一下,所有的入口成一个列表,方便以后找到其main函数。
|
命令 |
入口 |
|
namenode |
org.apache.hadoop.hdfs.server.namenode.NameNode |
|
secondarynamenode |
org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode |
|
datanode |
org.apache.hadoop.hdfs.server.datanode.DataNode |
|
fs / dfs |
org.apache.hadoop.fs.FsShell |
|
dfsadmin |
org.apache.hadoop.hdfs.tools.DFSAdmin |
|
mradmin |
org.apache.hadoop.mapred.tools.MRAdmin |
|
fsck |
org.apache.hadoop.hdfs.tools.DFSck |
|
balancer |
org.apache.hadoop.hdfs.server.balancer.Balancer |
|
jobtracker |
org.apache.hadoop.mapred.JobTracker |
|
tasktracker |
org.apache.hadoop.mapred.TaskTracker |
|
job |
org.apache.hadoop.mapred.JobClient |
|
queue |
org.apache.hadoop.mapred.JobQueueClient |
|
pipes |
org.apache.hadoop.mapred.pipes.Submitter |
|
version |
org.apache.hadoop.util.VersionInfo |
|
jar |
org.apache.hadoop.util.RunJar |
|
distcp |
org.apache.hadoop.tools.DistCp |
|
daemonlog |
org.apache.hadoop.log.LogLevel |
|
archive |
org.apache.hadoop.tools.HadoopArchives |
|
sampler |
org.apache.hadoop.mapred.lib.InputSampler |
至此整个目录有了一个初步的了解,接下来,那就可以顺着这些入口深入研究了。且慢,还差个调试环境呢! 下一章来。
Hadoop学习笔记(9) ——源码初窥,布布扣,bubuko.com
标签:style blog http color java 使用 io strong
原文地址:http://www.cnblogs.com/zjfstudio/p/3918669.html