Drbd(Distributed Replicated Block Device)为分布式复制块设备 是内核中的一个模块,要想让其工作起来要借助drbdadm等命令工具
Drbd类似于Raid1(mirror模式),但是Raid1的磁盘位于同一个主机上,通过总线直接连接主机,且两块磁盘必须一样大,因为所谓的镜像是按位对应同步存储的,Raid有控制芯片叫控制器(Controller),直接内置在在主板上;而通过PCI插槽提供的叫适配器(adaptor)
Drbd将位于两个主机上的不同磁盘或分区做成镜像设备,当向主节点写入时,会通过TCP/IP协议从网络上复制一份存储在备节点上
Drbd只允许两个节点,主从(primary/secondary)
主节点可以进行读写操作;而从节点不能挂载文件系统,不能进行读写
但是主从角色可以切换,且可以借助HA集群+集群文件系统构成双主模型
DRBD结构图
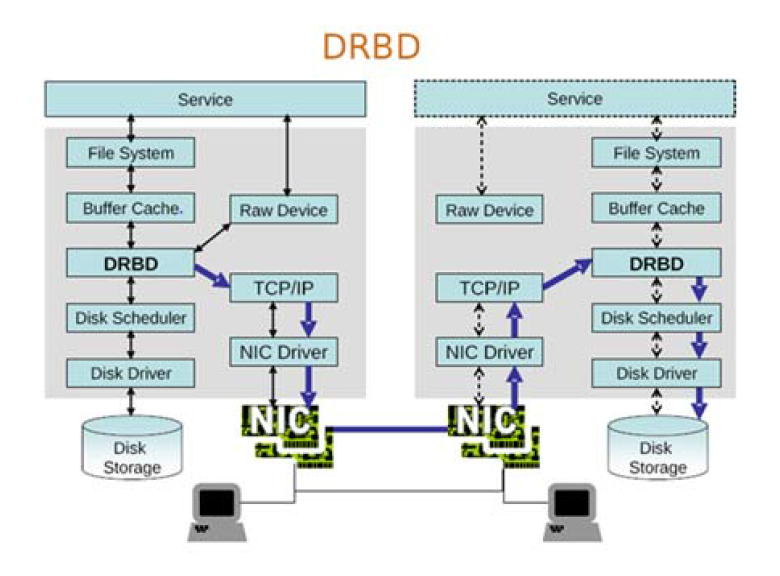
Drbd工作流程图分析:service服务,File System是任何进程要读取磁盘,都要向内核发起文件系统级别的调用来实现,文件系统能把数据等存入磁盘。Buffer Cache是service将数据缓存在内存中,并由Disk Scheduler取出调度排序,发往Disk Driver支配Disk Storage存储。而Raw Device则是不经由文件系统调用,直接块级别存储。DRBD则是直接在内核空间的内存与硬盘驱动之间加入一层,将从Buffer Cache提取的数据镜像一份,源数据继续经由Disk Driver支配Disk Storage存储,而镜像的数据经由TCP/IP网络通过本地网卡发往从drbd主机的drbd层交由Disk Driver支配Disk Storage存储。
DRBD的用户空间管理工具,用于管理主从drbd节点。主要使用drbdadm命令,因其更符合用户的使用习惯。而drbdsetup和drbdmeta为较接近底层的设备,所以使用较少。
DRBD的工作特性:实时,透明,设置数据同步类型
Drbd协议类型
A:数据发出去不管对方有没有收到(异步)性能好可靠性差
B:半同步
C: 数据发出去后要管对方收到后再发(同步)可靠性好但性能差
Drbd资源:定义Drbd的各种必须设置
1:资源名称
2:Drbd设备一般为/dev/drdbX 其主设备号为147,次设备号从0开始用于区分同一类型的不同设备
3:磁盘或者分区,在双方节点上,各自提供的存储设备
4:网络设备的配置,双方数据同步时所使用的网络属性如:是否加密,带宽多少。。。
命令
drbdadm 一个管理工具,配置文件为 /etc/drbd.conf 或/etc/drbd.d/*
Drbd的官方站点 https://www.linbit.com/
安装 Drbd + Corosync 实现高可用的MySql
drbd的rpm在内核版本2.6.33以上才自动加入内核功能,本文的系统版本为CentOS6.7,内核版本为2.6.32-573.el6.x86_64,所以要想使用drbd,只能编译源码,或是使用三方提供的rpm包。
[root@www mail]# uname -r %%而红帽6是2.6.32的内核,最好使用第三方的RPM包
2.6.32-573.el6.x86_64
ftp://rpmfind.net/linux/atrpms/el6-x86_64/atrpms/stable/
直接用yum源安装drbdCentOS 6.x
[root@www mail]rpm -ivh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
[root@www mail]yum -y install drbd83-utils kmod-drbd83
CentOS 7.x[root@www mail]rpm -ivh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
[root@www mail]yum install -y drbd84-utils kmod-drbd84
加载模块:准备一个大小为1G的/dev/sda5分区,但不要格式化 [root@www drbd-8.4.3]# vim /etc/drbd.conf %%drbd的配置文件 # You can find an example in /usr/share/doc/drbd.../drbd.conf.example include "drbd.d/global_common.conf"; %包含drbd.d/global_common.conf文件 include "drbd.d/*.res"; %包含drbd.d/*.res,所有res结尾的文件都独立第一了一个drbd资 %源
[root@www drbd-8.4.3]# vim /etc/drbd.d/global_common.conf %%此文件为主配置文件的一部分
global { %global段为全局配置,#开头则没有启用
usage-count yes; %收集用户的drbd装机信息
# minor-count dialog-refresh disable-ip-verification
}
common { %common段为不同的Drbd资源定义默认属性
protocol C; %默认的Drbd协议类型为C(同步)
handlers {
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when chosing your poison.
%%启动以下三项
pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
}
disk { on-io-error detach; %%节点故障就移除
# on-io-error fencing use-bmbv no-disk-barrier no-disk-flushes
# no-disk-drain no-md-flushes max-bio-bvecs
}
net {
cram-hmac-alg "sha1"; %数据同步时要加密,加密算法为sha1
shared-secret "mydrbdlab"; %加密的共享密钥,可以自己生成一段随机数
# sndbuf-size rcvbuf-size timeout connect-int ping-int ping-timeout max-buffers
# max-epoch-size ko-count allow-two-primaries cram-hmac-alg shared-secret
# after-sb-0pri after-sb-1pri after-sb-2pri data-integrity-alg no-tcp-cork
}
syncer {
rate 100M; %数据同步的带宽为100M
}
}
要想知道更多的参数可以
[root@www drbd-8.4.3]# man drbd.conf
这样主配置文件就配置好了,接下来定义Drbd资源
[root@www drbd-8.4.3]# vim /etc/drbd.d/mydrbd.res
resource web { %%web为自己定义的Drbd资源名称
on www.rs1.com{ %%定义节点rs1
device /dev/drbd0;%%在rs1上drbd设备名为drbd0,一般从0排起
disk /dev/sda5; %%在rs1上磁盘为sda5
address 192.168.139.2:7789; %%drbd监听在rs1的7789端口
meta-disk internal; %%drbd的元数据就在本节点内部
}
on www.rs2.com{ %%定义节点rs2
device /dev/drbd0;
disk /dev/sda5;
address 192.168.139.4:7789;
meta-disk internal;
}
}
[root@www drbd-8.4.3]# scp -r /etc/drbd.* rs2:/etc/ %%将配置文件及其资源定义的文件复制到节 %%点rs2上
drbd.conf 0.1KB/s 00:00
global_common.conf 1.3KB/s 00:00
mydrbd.res 0.6KB/s 00:00
在两个节点上初始化资源
192.168.139.2
[root@www drbd-8.4.3]# drbdadm create-md webWriting meta data...initializing activity logNOT initialized bitmapNew drbd meta data block successfully created.
192.168.139.4
[root@www drbd-8.4.3]# drbdadm create-md webWriting meta data...initializing activity logNOT initialized bitmapNew drbd meta data block successfully created.
192.168.139.2 和192.168.139.4两个节点同时启动drbd
[root@www drbd-8.4.3]# service drbd start[root@www drbd-8.4.3]# service drbd start启动服务后两节点都处于Secondary状态,将其中一个节点设置为Primary
192.168.139.2上
[root@www drbd-8.4.3]# drbdadm primary --force web或者[root@www drbd-8.4.3]# drbdadm -- --overwrite-data-of-peer primary web
查看状态信息
[root@www drbd-8.4.3]# drbd-overview %%查看状态信息 0:mystore SyncSource Primary/Secondary UpToDate/Inconsistent C r----- [======>.............] sync‘ed: 39.7% (3096/5128)M
同步完毕,rs1为主,rs2为从
[root@www drbd-8.4.3]# drbd-overview %%查看状态信息
0:mystore Connected Primary/Secondary UpToDate/UpToDate C r----- 也可使rs1为从节点,rs2为主节点
[root@www drbd-8.4.3]# drbdadm secondary web %%将192.168.139.2变为从节点[root@www drbd-8.4.3]# drbdadm primary --force web %%将192.168.139.4变为主节点
格式化为ext4文件系统并分区
[root@www drbd-8.4.3]# mke2fs -t ext4 /dev/drbd0
挂载并测试drbd
[root@www drbd-8.4.3]# mount /dev/drbd0 /mnt %%将drbd0进行挂载[root@www drbd-8.4.3]# cd /mnt[root@www drbd-8.4.3]# cp /etc/hosts ./ %%复制文件测试[root@www drbd-8.4.3]# ls %%挂载成功hosts lost+found这样一个简单的Drbd就制作完成
如果用Corosync+Pacemaker再配置一个HA高可用集群,将Drbd配置成一个资源,就可以实现双主模型,或者实现主从节点自动切换(可以用crm命令配置)
本文出自 “11097124” 博客,请务必保留此出处http://11107124.blog.51cto.com/11097124/1883811
原文地址:http://11107124.blog.51cto.com/11097124/1883811