标签:classpath jar function target 文件 size web ash att
crawler4j是一个轻量级多线程网络爬虫,开发者可以调用相应的接口在短时间内创建一个多线程网络爬虫。
前期准备
使用maven
为了使用最近版本的crawler4j,请将下面的片段添加到你的pom.xml文件中。
<dependency>
<groupId>edu.uci.ics</groupId>
<artifactId>crawler4j</artifactId>
<version>4.1</version>
</dependency>
不没有maven项目
crawler4j JARs 可以在发行的版本页面和Maven Central(应该是maven中心)找到。
如果你没有maven项目却想使用crawler4j,注意crawler4j jar文件有几个外部的依赖。在最近的版本中,你可以发现一个命名为crawler4j-X Y -with-dependencies.jar包含了所有的依赖的捆绑。你可以下载下来并且将它添加到你的classpath下获得所有的依赖。
过程
使用crawler4j需要创建一个继承WebCrawler的爬虫类。
public class MyCrawler extends WebCrawler { private final static Pattern FILTERS = Pattern.compile(".*(\\.(css|js|gif|jpg" + "|png|mp3|mp3|zip|gz))$"); /** * This method receives two parameters. The first parameter is the page * in which we have discovered this new url and the second parameter is * the new url. You should implement this function to specify whether * the given url should be crawled or not (based on your crawling logic). * In this example, we are instructing the crawler to ignore urls that * have css, js, git, ... extensions and to only accept urls that start * with "http://www.ics.uci.edu/". In this case, we didn‘t need the * referringPage parameter to make the decision. */ @Override public boolean shouldVisit(Page referringPage, WebURL url) { String href = url.getURL().toLowerCase(); return !FILTERS.matcher(href).matches() && href.startsWith("http://www.ics.uci.edu/"); } /** * This function is called when a page is fetched and ready * to be processed by your program. */ @Override public void visit(Page page) { String url = page.getWebURL().getURL(); System.out.println("URL: " + url); if (page.getParseData() instanceof HtmlParseData) { HtmlParseData htmlParseData = (HtmlParseData) page.getParseData(); String text = htmlParseData.getText(); String html = htmlParseData.getHtml(); Set<WebURL> links = htmlParseData.getOutgoingUrls(); System.out.println("Text length: " + text.length()); System.out.println("Html length: " + html.length()); System.out.println("Number of outgoing links: " + links.size()); } } }
WebCrawler is a metasearch engine that blends the top search results from Google Search and Yahoo! Search. WebCrawler also provides users the option to search for images, audio, video, news, yellow pages and white pages. WebCrawler is a registered trademark of InfoSpace, Inc. It went live on April 20, 1994 and was created by Brian Pinkerton at the University of Washington.[2]
补充:
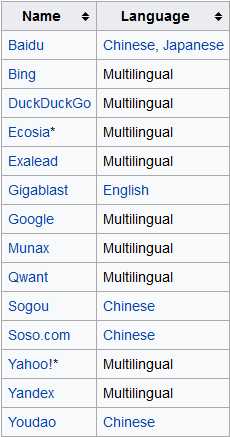
search engines
标签:classpath jar function target 文件 size web ash att
原文地址:http://www.cnblogs.com/s1-myblog/p/6196879.html