标签:reserve 噪声 ges 印象 取值 res 方便 提前 学习
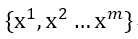
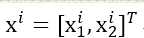
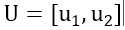

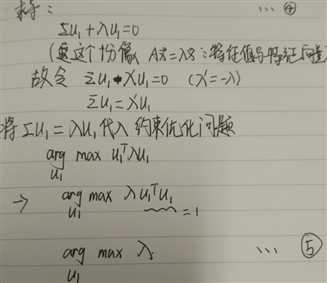
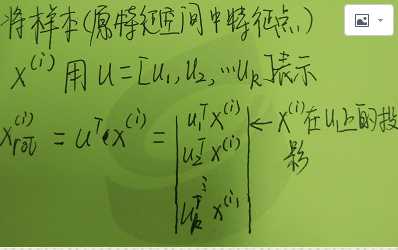
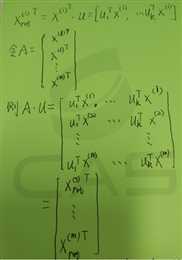
1 #encoding: UTF-8 2 ‘‘‘ 3 Created on 2016??12??14?? 4 5 @author: YYH 6 ‘‘‘ 7 import numpy as np 8 from array import array 9 # 自己实现参考 10 # http://blog.csdn.net/u012162613/article/details/42177327 11 # 传入的数据格式: array 12 # 每一行代表一个样本 13 # 每一列代表一个唯度的信息 14 15 #数据中心化,使得各个维度的信息均为0 16 def meanshift(dataArr): 17 mean = np.mean(dataArr,axis=0)#对每一列求均值 18 newData = dataArr-mean 19 return newData,mean 20 def zeroData(dataArr,mean): 21 newData = dataArr-mean 22 return newData 23 class PCA: 24 def __init__(self, n_components=1,percentage=0.99): 25 self.dstDim = n_components 26 self.reservePercentage = percentage 27 28 def __del__(self): 29 pass 30 def fit(self,dataArr): 31 zeroMeanData,meanVal = meanshift(dataArr) 32 self.meanVal = meanVal#保存数据中心 33 # 求协方差矩阵,rowvar = 0:一行代表一个样本 34 cov = np.cov(zeroMeanData,rowvar=0) 35 #求特征值和特征向量,特征向量是按列放的,即一列代表一个特征向量 36 eigVals,eigVector =np.linalg.eig(cov) 37 38 eigValsIndice = np.argsort(eigVals)#从小到大排列 39 n_eigValsIndice = eigValsIndice[-1:-(self.dstDim+1):-1] #最大的n个特征的下标 40 41 n_eigVect = eigVector[:,n_eigValsIndice]#最大的n个特征值对应的特征向量 42 n_eigVect = np.matrix(n_eigVect) 43 self.n_eigVect = n_eigVect #保存特征向量 44 45 def fit_transform(self,dataArr): 46 zeroMeanData,meanVal = meanshift(dataArr) 47 self.meanVal = meanVal#保存数据中心 48 # 求协方差矩阵,rowvar = 0:一行代表一个样本 49 cov = np.cov(zeroMeanData,rowvar=0) 50 #求特征值和特征向量,特征向量是按列放的,即一列代表一个特征向量 51 eigVals,eigVector =np.linalg.eig(cov) 52 53 eigValsIndice = np.argsort(eigVals)#从小到大排列 54 n_eigValsIndice = eigValsIndice[-1:-(self.dstDim+1):-1] #最大的n个特征的下标 55 n_eigVect = eigVector[:,n_eigValsIndice]#最大的n个特征值对应的特征向量 56 57 zeroMeanData = np.matrix(zeroMeanData) 58 n_eigVect = np.matrix(n_eigVect) 59 self.n_eigVect = n_eigVect #保存特征向量 60 lowDData = zeroMeanData*n_eigVect #低维特征空间的数据 61 # reConData = (lowDData*n_eigVect.T)+meanVal #重构数据 62 return lowDData 63 def transform(self,dataArr): 64 zeroMeanData = zeroData(dataArr,self.meanVal) 65 zeroMeanData = np.matrix(zeroMeanData) 66 lowDData = zeroMeanData*self.n_eigVect #低维特征空间的数据 67 # reConData = (lowDData*n_eigVect.T)+meanVal #重构数据 68 return lowDData 69
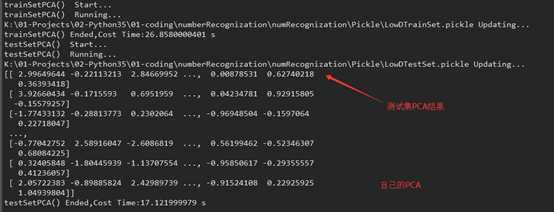
【代码验证】
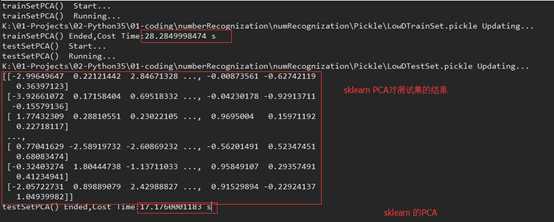
在做手写数字识别时,我分别使用了sklearn的PCA,和自己整理的PCA,达到的准确度都到了96%左右。
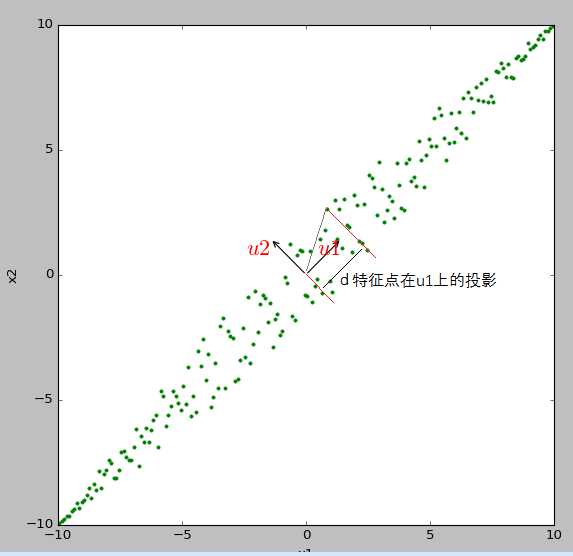
在PCA降维后的数据来看,可能在特征向量上方向不同,导致部分列跟sklearn的符号相反
时间上,可能自己整理实现的PC A现在耗时短点,毕竟目前是比较简单的PC A
【统计学习】主成分分析PCA(Princple Component Analysis)从原理到实现
标签:reserve 噪声 ges 印象 取值 res 方便 提前 学习
原文地址:http://www.cnblogs.com/guiguzhixing/p/6198788.html