标签:des style blog http 使用 io strong 文件
HDFS
Hadoop的核心就是HDFS与MapReduce。那么HDFS又是基于GFS的设计理念搞出来的。
HDFS全称是Hadoop Distributed System。HDFS是为以流的方式存取大文件而设计的。适用于几百MB,GB以及TB,并写一次读多次的场合。而对于低延时数据访问、大量小文件、同时写和任意的文件修改,则并不是十分适合。
优点:
1)适合存储非常大的文件
2)适合流式数据读取,即适合“只写一次,读多次”的数据处理模式
3)适合部署在廉价的机器上
缺点:
1)不适合存储大量的小文件,因为受Namenode内存大小限制
2)不适合实时数据读取,高吞吐量和实时性是相悖的,HDFS选择前者
3)不适合需要经常修改数据的场景
数据块:
每个磁盘都有默认的数据块大小,一般就是521字节。这是磁盘进行数据读写的最小单位。HDFS同样也有块(block)的概念,但是大得多,有64MB。与单一磁盘上的文件系统一样,HDFS上的文件也被划分为块大小的多个分块。但是还是有所不同,比如HDFS中小于一个块大小的文件不会占据整个块的空间。
对分布式文件系统中的快进行抽象的好处:
1)一个文件的大小可能会大于网络中任意一个磁盘的容量,文件的所有块并不需要存储在同一个磁盘上,因此可以利用集群上的任意一个磁盘进行存储,但是对于HDFS来说,它是存储了一个文件。
(这不就正是我们要的效果吗)
2)以抽象块为存储单元,简化了设计。还方便块的备份。
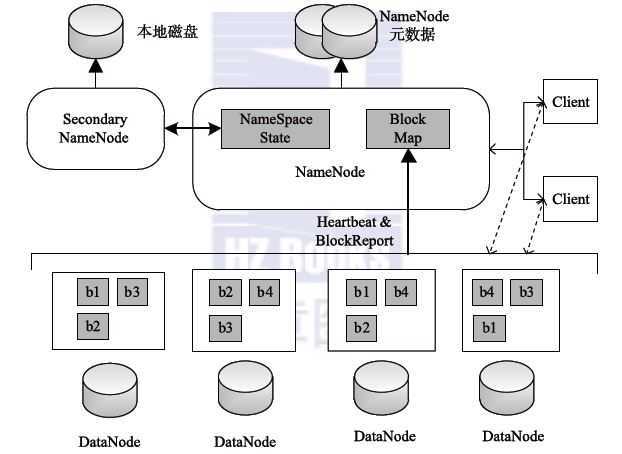
HDFS的架构如上图所示,总体上采用了Master/Slave的架构,主要有以下4个部分组成:
1、Client
客户端,就是我们通过调用接口实现的代码。
2、NameNode
整个HDFS集群只有一个NameNode,它存储整个集群文件分别的元数据信息。这些信息以fsimage和editlog两个文件存储在本地磁盘,Client通过这些元数据信息可以找到相应的文件。此外,NameNode还 负责监控DataNode的健康情况,一旦发现DataNode异常,就将其踢出,并拷贝其上数据至其它DataNode。
3、Secondary NameNode
Secondary NameNode负责定期合并NameNode的fsimage和editlog。这里特别注意,它不是NameNode的热备,所以NameNode依然是Single Point of Failure。它存在的主要目的是为了分担一部分 NameNode的工作(特别是消耗内存的工作,因为内存资源对NameNode来说非常珍贵)。
4、DataNode
DataNode负责数据的实际存储。当一个文件上传至HDFS集群时,它以Block为基本单位分布在各个DataNode中,同时,为了保证数据的可靠性,每个Block会同时写入多个DataNode中(默认为3)
那么文件如何存储的呢?
要存储的文件会分成很多块,存到Datanode里。分块的原则:除了最后一个数据块,其它数据块的大小相同,一般为64MB or 128MB。 每个数据块有副本(一般为3):副本多了浪费空间。
副本存储:在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架的节点上,一个副本放在同一机架的另一个节点上,。
HDFS通信协议
所有的 HDFS 通讯协议都是构建在 TCP/IP 协议上。客户端通过一个可 配置的端口连接到 Namenode , 通过 ClientProtocol 与 Namenode 交互。而 Datanode 是使用 DatanodeProtocol 与 Namenode 交互。再设计上, DataNode 通过周期性的向 NameNode 发送心跳和数据块来保持和 NameNode 的通信,数据块报告的信息包括数据块的属性,即数据块属于哪 个文件,数据块 ID ,修改时间等, NameNode 的 DataNode 和数据块的映射 关系就是通过系统启动时 DataNode 的数据块报告建立的。从 ClientProtocol 和 Datanodeprotocol 抽象出一个远程调用 ( RPC ), 在设计上, Namenode 不会主动发起 RPC , 而是是响应来自客户端和 Datanode 的 RPC 请求。
(这个在我们进行hadoop文件配置的时候就可以感受到,都是通过一个Ip地址加上一个端口号来访问对方的)
文件读取的过程如下:
写入文件的过程如下:
标签:des style blog http 使用 io strong 文件
原文地址:http://www.cnblogs.com/GuoJiaSheng/p/3919075.html