标签:des style blog http color 使用 os io
Hadoop分布式文件系统(HDFS)设计用来可靠的存储超大数据集,同时以高速带宽将数据集传输给用户应用。
在一个超大集群中,数以千计的服务器直接接触存储器和执行用户应用任务。通过许多服务器的分布式存储和计算,资源随需求增长的时候仍然可以保持经济性。
我们解释了HDFS架构,同时介绍了我们在雅虎使用HDFS去管理25PB企业数据的经验。
Hadoop的一个重要特点是将数据和计算能力划分为小部分,通过许多(数千)主机运行,这些主机并行计算得到他们的结果。一个Hadoop集群通过简单增加商用服务器的数量来扩展其计算能力,存储能力和IO带宽。

相同点
HDFS分别存储文件系统元数据和应用程序数据。与在其他分布式文件系统中相同,比如PVFS【2】【14】,Lustre【7】和GFS【5】【8】,
HDFS在一个专门的服务器存储元数据,这个服务器被称为名称节点。应用程序数据存储在其他被称为数据结点的服务器上。
不同点
HDFS中的数据节点并不使用数据保护机制比如RAID(独立磁盘冗余阵列),以确保数据持久性。
相反。比如GFS,其文件内容在多个数据节点是重复的以确保可靠性。
这个策略不仅仅可以确保数据持久性,还有额外的优点:数据变形带宽加倍,而且本地计算的时候服务器有更多机会靠近所需要的数据。
资料
【1】Hadoop快速入门(http://hadoop.apache.org/docs/r1.0.4/cn/quickstart.html)
【2】Hadoop分布式文件系统:架构和设计(http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html)
【3】从Hadoop框架与MapReduce模式中谈海量数据处理(含淘宝技术架构)
备注
1、这篇文档目的是帮助你快速完成单机上的Hadoop安装与使用以便你对Hadoop分布式文件系统(HDFS)和Map-Reduce框架有所体会,比如在HDFS上运行示例程序或简单作业等。
2、【此文与本文完全契合】
Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统。
它和现有的分布式文件系统有很多共同点。但同时,它和其他的分布式文件系统的区别也是很明显的。
HDFS是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,非常适合大规模数据集上的应用。【与本文相互印证】
3、想读懂此文,读者必须先要明确以下几点,以作为阅读后续内容的基础知识储备:
3.1 MapReduce是一种模式。
3.2 Hadoop是一种框架。
3.3 Hadoop是一个实现了mapreduce模式的开源的分布式并行编程框架。
所以,你现在,知道了什么是mapreduce,什么是hadoop,以及这两者之间最简单的联系,而本文的主旨即是,一句话概括:在hadoop的框架上采取mapreduce的模式处理海量数据。下面,咱们可以依次深入学习和了解mapreduce和hadoop这两个东西了。【回顾基础】
Mapreduce模式
mapreduce是一种云计算的核心计算模式,一种分布式运算技术,也是简化的分布式编程模式,它主要用于解决问题的程序开发模型,也是开发人员拆解问题的方法。
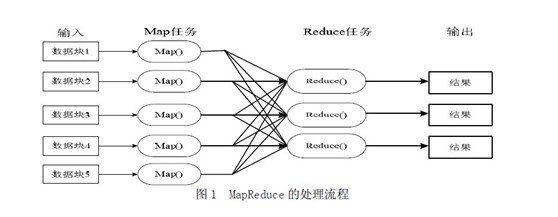
如下图所示,mapreduce模式的主要思想是将自动分割要执行的问题(例如程序)拆解成map(映射)和reduce(化简)的方式,流程图如下图1所示:
在数据被分割后通过Map 函数的程序将数据映射成不同的区块,分配给计算机机群处理达到分布式运算的效果,在通过Reduce 函数的程序将结果汇整,从而输出开发者需要的结果。
MapReduce致力于解决大规模数据处理的问题,因此在设计之初就考虑了数据的局部性原理,利用局部性原理将整个问题分而治之。
MapReduce集群由普通PC机构成,为无共享式架构。在处理之前,将数据集分布至各个节点。处理时,每个节点就近读取本地存储的数据处理(map),将处理后的数据进行合并(combine)、排序(shuffle and sort)后再分发(至reduce节点),避免了大量数据的传输,提高了处理效率。【相互印证】
无共享式架构的另一个好处是配合复制(replication)策略,集群可以具有良好的容错性,一部分节点的down机对集群的正常工作不会造成影响。【相互印证】
Namenode 和 Datanode
HDFS采用master/slave架构。一个HDFS集群是由一个Namenode和一定数目的Datanodes组成。
Namenode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。
集群中的Datanode一般是一个节点一个,负责管理它所在节点上的存储。
HDFS暴露了文件系统的名字空间,用户能够以文件的形式在上面存储数据。从内部看,一个文件其实被分成一个或多个数据块,这些块存储在一组Datanode上。
Namenode执行文件系统的名字空间操作,比如打开、关闭、重命名文件或目录。它也负责确定数据块到具体Datanode节点的映射。Datanode负责处理文件系统客户端的读写请求。在Namenode的统一调度下进行数据块的创建、删除和复制。
文件系统的名字空间 (namespace)
HDFS支持传统的层次型文件组织结构。用户或者应用程序可以创建目录,然后将文件保存在这些目录里。文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。当前,HDFS不支持用户磁盘配额和访问权限控制,也不支持硬链接和软链接。但是HDFS架构并不妨碍实现这些特性。
Namenode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被Namenode记录下来。应用程序可以设置HDFS保存的文件的副本数目。文件副本的数目称为文件的副本系数,这个信息也是由Namenode保存的。

【中断了几天没翻译都忘啦,今日发现一个讲的很好的网站(Hadoop学习笔记一 简要介绍)】
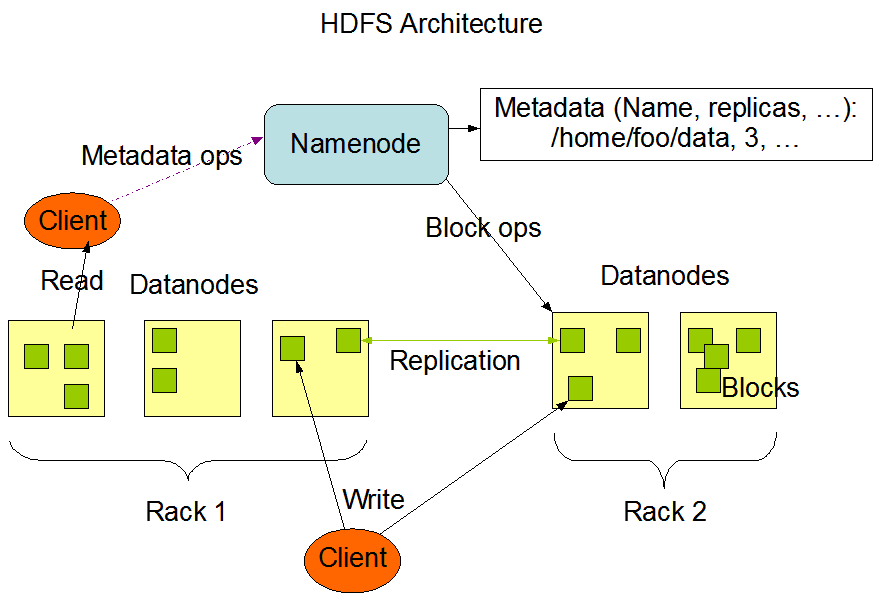
文中对上面那张HDFS Architecture的解释:
从上面的图中可以看出,Namenode,Datanode,Client之间的通信都是建立在TCP/IP的基础之上的。
当Client要执行一个写入的操作的时候,命令不是马上就发送到Namenode,Client首先在本机上临时文件夹中缓存这些数据,当临时文件夹中的数据块达到了设定的Block的值(默认是64M)时,Client便会通知Namenode,Namenode便响应Client的RPC请求,将文件名插入文件系统层次中并且在Datanode中找到一块存放该数据的block,同时将该Datanode及对应的数据块信息告诉Client,Client便这些本地临时文件夹中的数据块写入指定的数据节点。
HDFS采取了副本策略,其目的是为了提高系统的可靠性,可用性。HDFS的副本放置策略是三个副本,一个放在本节点上,一个放在同一机架中的另一个节点上,还有一个副本放在另一个不同的机架中的一个节点上。当前版本的hadoop0.12.0中还没有实现,但是正在进行中,相信不久就可以出来了。&关于MapReduce的内容,建议看看孟岩的这篇MapReduce:The Free Lunch Is Not Over!【又发现一个大牛博客,但不怎么更新了】
分别介绍7个部分的详情
NameNode、DataNode、HDFS Client、Image与Journal、CheckpointNode、BackupNode和升级文件系统快照zz
HDFS名字空间是一个由文件和目录组成的层次性结构。
当HDFS Client想读取文件时,必须与NameNode联系以获取组成该文件的blocks的位置信息,然后选择一个离它最近的DataNode去读取block内容。在写数据时,client向NameNode发送请求,让它指定应该由哪三个DataNodes来保存该block的三个副本。之后客户端就会以pipeline的模式将数据写入到DataNodes。
每一个集群有一个独立的NameNode。每个集群包含数千DataNode和数万HDFS客户端。同时每个数据节点可以多线程的执行多个应用任务。
HDFS会将整个名字空间保存在内存中。由inode数据及每个文件包含的所有blocks列表组成的名字系统元数据叫做image。保存在本机本地文件系统中的该image的一个持久化记录称为一个checkpoint。NameNode也会将称为journal的针对该image的修改日志保存到本机本地文件系统中。为了提高持久性,可以在其他服务器上保存checkpoint和journal的多个副本。
2.2.2、DataNode
DataNode中的每个block副本由本机本地文件系统中的两个文件组成。第一个文件包含数据本身,第二个文件是该block的元数据包括该block数据的校验和及该block的世代戳(generation stamp)。
在每个DataNode启动时,它会连接到NameNode执行一个握手。握手的目的是为了验证名字空间ID及DataNode的软件版本。如果其中只要有一个无法与NameNode匹配,那么DataNode会自动关闭。……名字空间ID是在文件系统创建时分配给它的实例编号。……允许一个新初始化的并且没有任何名字空间ID的DataNode加入到集群中,它会接受集群的名字空间ID。……在正常情况下,DataNode会向NameNode发送心跳信息以证实它自己正在运行以及它所持有的block副本是可用的。默认的心跳周期是3秒钟。【很像计算机网络中的内容】……NameNode每秒可以处理数千个心跳请求而不会影响到其他的NameNode操作。
2.2.3、HDFS Client
当一个应用程序读取一个文件时,HDFS client首先向NameNode询问持有组成该文件的blocks的DataNodes列表。然后直接联系某个DataNode请求对于它所需要的block的传输。当client进行写的时候,它会首先让NameNode选定持有该文件的第一个block的那些DataNodes。客户端会把这些节点组织成一个pipeline,然后发送数据。当第一个block写出后,客户端会继续请求选定持有下一个block的新的DataNodes。新的pipeline会被建立起来,客户端开始发送该文件后面的那些数据。每次选定的DataNodes可能是不同的。
一个HDFS客户端通过向NameNode传输path创建一个新文件。对于该文件的每个block,NameNode返回持有它的副本的那些DataNodes列表。客户端然后将数据通过pipeline的形式传送给选定的DataNodes,DataNodes最终会再联系NameNode对block各副本的创建情况进行确认。
名字空间image是代表应用数据的目录和文件组织方式的文件系统元数据。写入到磁盘中的image的持久化记录称为checkpoint{!image在内存中,checkpoint则是在磁盘中}。
HDFS中的NameNode,除了可以担任客户端请求服务者这一首要角色外,还可以担任其他的一些角色比如CheckpointNode或者是BackupNode。节点可以在启动时设置它的角色。
CheckpointNode会周期性地合并现有的checkpoint和journal,创建一个新的checkpoint和一个空的journal。CheckpointNode通常运行在与NameNode不同的一个节点上,因为它需要与NameNode等同的内存空间。它会从NameNode下载当前的checkpoint和journal文件,然后在本地对它们进行合并,然后将新的checkpoint返回给NameNode。
BackupNode是HDFS最近引入的一个feature。与CheckpointNode类似,BackupNode能够创建周期性的checkpoints,但是除此之外它还在内存中维护了一个文件系统名字空间的最新映像,该映像会一直与NameNode状态保持同步。
在软件升级期间,由软件bug或者人为失误导致的系统崩溃概率会上升。在HDFS中创建快照的目的是为了最小化系统升级期间对存储的数据的潜在威胁。

如果没有错误发生,块的构建就会经过像图2那样的三个阶段。图2展示了一个具有三个DataNodes的流水线及5个pakctes的block。图中,粗线代表了数据包,虚线代表了确认消息,细线代表了用于建立和关闭流水线的控制消息。竖线代表了客户端及3个DataNodes的活动,时间流向是自上而下的。
从t0到t1是流水线建立阶段,t1到t2是数据流阶段,t1代表了第一个数据包被发送的时间点,t2代表了针对最后一个数据包的确认信息的接收时间点。在这里,在第二个包传输时有一个hflush操作。hflush操作标识是与数据打包在一块的,而不是独立的一个操作。最后,t2到t3是针对该block的pipeline关闭阶段。
对于一个大规模集群来说,将所有节点用一种扁平的拓扑结构连接起来或许是不实际的。更常用的做法是通过多用机柜来布置所有结点。机柜内的所有节点共享一个交换机,机柜之间的交换则是通过一个或者多个核心交换机。不同机柜的两个节点的通信会经过多用交换机。大多数情况下,同一个机柜的节点之间网络带宽比不同机柜的两节点之间网络带宽要高。图3解释了一个有两个机柜的集群,每个机柜包含三个结点。

3.3、副本管理
···
3.4、平衡者
3.5、block扫描
3.6、下线
3.7、跨集群数据拷贝
4、在雅虎中的实践
Yahoo!从2004年开始基于分布式文件系统的MapReduce的相关研究。Apache Hadoop项目在2006年成立。在那年年底,Yahoo!已经将Hadoop投入到内部使用,同时有一个用于开发的300个节点的集群。从那时起,HDFS已经成为Yahoo!后台架构的不可或缺的一部分。
5、展望
···
占位
【翻译笔记】Hadoop分布式文件系统,布布扣,bubuko.com
标签:des style blog http color 使用 os io
原文地址:http://my.oschina.net/SnifferApache/blog/303691