标签:技术 turn help 链接 执行 nan remove page code
可能,宅男或老司机某种程度上会喜欢这个工具。事实上,这个工具也确实是应老司机的需求而写,只是还比较简易,短期内可能不会再作改进或增强(譬如绕过防盗链处理)。
完整参考命令行:MiniImageCrawler -numCrawlGoroutine=5 -baseInterval=2 -randomInterval=5 -tickerInterval=10 -savePath="" -imgWidthMin=500 -imgHeightMin=500 http://eladies.sina.com.cn/
或直接:MiniImageCrawler http://eladies.sina.com.cn/
于是即可坐等程序将指定网站的所有(符合条件的)图片抓取到本地。
package main
import (
"ImageCrawler"
"flag"
"fmt"
"helperutils"
"image"
_ "image/jpeg"
_ "image/png"
"log"
"math/rand"
"net/url"
"os"
"runtime"
"sync/atomic"
"time"
)
var numCrawlGoroutine int
var baseInterval, randomInterval int
var tickerInterval int
var savePath string
var imgWidthMin, imgHeightMin int
var urlHost string
func init() {
rand.Seed(time.Now().UnixNano())
}
func parseFlag() {
flag.IntVar(&numCrawlGoroutine, "numCrawlGoroutine", 5, "最大抓取线程数")
flag.IntVar(&baseInterval, "baseInterval", 2, "最短抓取间隔")
flag.IntVar(&randomInterval, "randomInterval", 5, "抓取随机间隔")
flag.IntVar(&tickerInterval, "tickerInterval", 10, "Goroutine数目报告间隔(单位: s)")
flag.StringVar(&savePath, "savePath", "", "图片保存目录(默认为程序所在目录)")
flag.IntVar(&imgWidthMin, "imgWidthMin", 0, "最小图片宽度")
flag.IntVar(&imgHeightMin, "imgHeightMin", 0, "最小图片高度")
flag.Parse()
if len(flag.Args()) == 0 {
panic("请指定起始抓取网页地址!")
} else {
u, err := url.Parse(flag.Args()[0])
if err != nil {
panic(err)
}
urlHost = u.Host
}
if numCrawlGoroutine < 1 {
panic("请设定不小于 1 的最大抓取线程数!")
}
if baseInterval < 1 {
panic("请设定不小于 1 的最短抓取间隔!")
}
if randomInterval < 2 {
panic("请设定合法的抓取随机间隔!")
}
if tickerInterval < 5 {
panic("请设定不小于 5 的报告间隔!")
}
if savePath == "" {
savePath = helperutils.GetAppPath() + urlHost + `\`
if !helperutils.DirectoryExists(savePath) {
if err := os.Mkdir(savePath, os.ModePerm); err != nil {
panic(fmt.Sprintf("Can not make dir: %s", savePath))
}
}
} else {
if !helperutils.DirectoryExists(savePath) {
panic("不合法的图片保存目录设置!")
}
savePath = helperutils.IncludeTrailingBackslash(savePath)
}
if imgWidthMin < 0 {
panic("请设定不小于 0 的最小图片宽度!")
}
if imgHeightMin < 0 {
panic("请设定不小于 0 的最小图片高度!")
}
}
func parsePage(url, homePage string, numChan chan<- string) []string {
ret, err := ImageCrawler.ParsePage(url, homePage, savePath, numChan)
if err != nil {
return nil
}
time.Sleep(time.Duration(rand.Intn(randomInterval)+baseInterval) * time.Second)
return ret
}
func CheckImageSize(fileName string, minWidth, minHeight int) bool {
file, err := os.Open(fileName)
if err != nil {
return false
}
img, _, err := image.Decode(file)
if err != nil {
file.Close()
os.Remove(fileName)
return false
}
pt := img.Bounds().Size()
if pt.X < minWidth || pt.Y < minHeight {
file.Close()
os.Remove(fileName)
return false
}
file.Close()
return true
}
func main() {
parseFlag()
var imgNum, smallNum int64
nameChan := make(chan string)
go func() {
for s := range nameChan {
imgNum += 1
go func(imgName string) {
if !CheckImageSize(imgName, imgWidthMin, imgHeightMin) {
atomic.AddInt64(&smallNum, 1)
}
}(s)
}
}()
worklist := make(chan []string)
pendingNum := 1
go func() {
worklist <- []string{flag.Args()[0]}
}()
ticker := time.NewTicker(time.Duration(tickerInterval) * time.Second)
go func() {
for range ticker.C {
log.Printf("Num of Goroutines: %d\n", runtime.NumGoroutine())
}
}()
tokens := make(chan struct{}, numCrawlGoroutine)
seenUrls := make(map[string]bool)
log.Println("图片抓取已启动...")
timeBegin := time.Now()
for ; pendingNum > 0; pendingNum-- {
list := <-worklist
for _, link := range list {
if !seenUrls[link] {
seenUrls[link] = true
pendingNum++
go func(url string) {
tokens <- struct{}{}
defer func() {
<-tokens
}()
worklist <- parsePage(url, urlHost, nameChan)
}(link)
}
}
}
log.Printf("图片抓取结束。耗时: %s\n", time.Since(timeBegin).String())
log.Println("正在进行收尾统计...")
close(nameChan)
ticker.Stop()
time.Sleep(time.Millisecond * 2000)
invalidNum := atomic.LoadInt64(&smallNum)
log.Printf("抓取总计: 图片总数 %d, 小图片数 %d, 有效图片数 %d\n", imgNum, invalidNum, imgNum-invalidNum)
log.Println("The End.")
}
package ImageCrawler
import (
"fmt"
"io"
"net/http"
"os"
"path/filepath"
"strings"
"golang.org/x/net/html"
)
func ParsePage(url, homePage, savePath string, nameChan chan<- string) ([]string, error) {
resp, err := http.Get(url)
if err != nil {
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return nil, fmt.Errorf("getting %s: %s", url, resp.Status)
}
doc, err := html.Parse(resp.Body)
if err != nil {
return nil, fmt.Errorf("parsing %s as HTML: %v", url, err)
}
var links []string
visitNode := func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "a" {
for _, a := range n.Attr {
if a.Key != "href" {
continue
}
link, err := resp.Request.URL.Parse(a.Val)
if err != nil {
continue
}
addr := link.String()
if strings.HasSuffix(addr, ".jpg") || strings.HasSuffix(addr, ".jpeg") || strings.HasSuffix(addr, ".png") {
DownloadImage(addr, savePath, nameChan)
} else {
if strings.Contains(addr, homePage) {
links = append(links, addr)
}
}
}
} else if n.Type == html.ElementNode && n.Data == "img" {
for _, a := range n.Attr {
if a.Key != "src" {
continue
}
link, err := resp.Request.URL.Parse(a.Val)
if err != nil {
continue
}
addr := link.String()
if strings.HasSuffix(addr, ".jpg") || strings.HasSuffix(addr, ".jpeg") || strings.HasSuffix(addr, ".png") {
DownloadImage(addr, savePath, nameChan)
}
}
}
}
forEachNode(doc, visitNode, nil)
return links, nil
}
func DownloadImage(addr, savePath string, nameChan chan<- string) {
resp, err := http.Get(addr)
if err != nil {
return
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
return
}
fileName := savePath + filepath.Base(addr)
dst, err := os.Create(fileName)
if err != nil {
return
}
io.Copy(dst, resp.Body)
dst.Close()
nameChan <- fileName
}
func forEachNode(n *html.Node, pre, post func(n *html.Node)) {
if pre != nil {
pre(n)
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
forEachNode(c, pre, post)
}
if post != nil {
post(n)
}
}
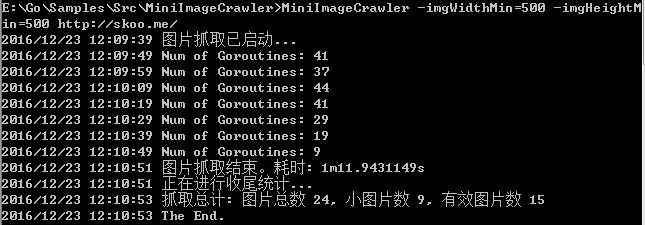
可执行文件下载链接在这里。
标签:技术 turn help 链接 执行 nan remove page code
原文地址:http://www.cnblogs.com/ecofast/p/6214373.html