标签:大写 日志 pre file logstash 打开 pass code 1.2
ELK是一个日志分析和统计框架,是Elasticsearch、Logstash和Kibana三个核心开源组件的首字母缩写,实践中还需要filebeat、redis配合完成日志的搜集。
|
名称 |
版本 |
说明 |
|
Elasticsearch |
2.3 |
分布式搜索引擎,存储和搜索日志 |
|
Logstash |
2.3 |
分析和搜集日志的工具,实践中主要使用它的分析功能 |
|
Kibana |
4.5 |
为Elasticsearch的查询、分析和统计提供友好的web界面 |
|
Filebeat |
1.2 |
日志搜集 |
|
Redis |
2.8 |
缓存filebeat搜集的大量日志数据 |
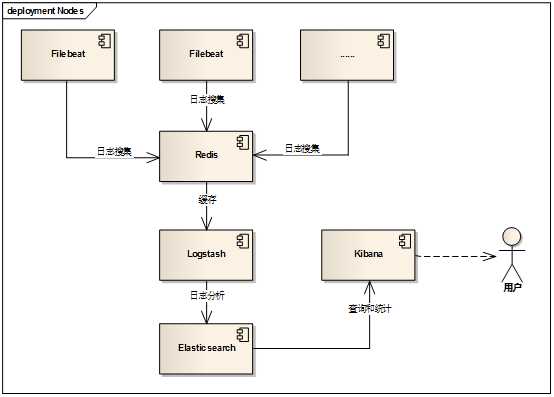
用户只需要操作kibana即可。
其他更多配置参看这里的其他文章;
output: redis: host: "192.168.1.111" port: 6379 #save_topology: true index: "TEST_ELK_LIST" db: 0 #db_topology: 1 #password: "" #timeout: 5 #reconnect_interval: 1
其他更多配置参看这里的其他文章;
input { redis { host => "192.168.1.111" port => 6379 db => 0 data_type => "list" key => "TEST_ELK_LIST" threads => 3 } }
访问kibana,浏览器打开:http://[kibana-ip]:5610
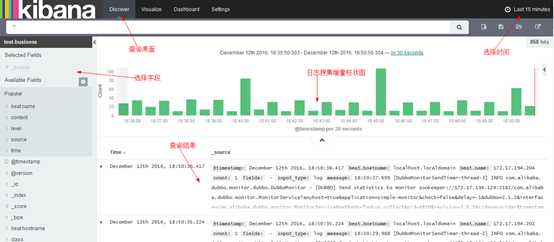
首先选择索引和时间,可选在左边选择需要显示的列,之后就可以通过中间的搜索框进行搜索,下面是查询语法;
关键字:直接输入即可,比如一个手机号;
短语:短语需要用双引号,比如"hello world",大于等于两个字的中文都属于短语;
指定字段:可以用冒号指定字段包含某些关键字,比如:level:ERROR;短语需要用双引号适用于所有地方,data:"异常";
非、与、或:NOT、AND、OR,必须大写,比如:NOT level:ERROR
组合:组合用小括号,比如:(source:"/var/log/" OR source:"/data/log/") AND level:ERROR
必须、不可:+、-,比如来自/var/log但不包括12月23日的:source:(+"/var/log/" -"2016-12-23")
范围:数字范围,字段类型必须是数字,count:[1 TO 2];时间也可以用范围,但用右上角选择更方便;
通配符:跟常用的一致,? 匹配单个字符,* 匹配0到多个字符;
over
标签:大写 日志 pre file logstash 打开 pass code 1.2
原文地址:http://www.cnblogs.com/toSeek/p/6215424.html