标签:通过 stc float current ogr pyw gray cell slax
在对数据进行预处理时,我们经常会遇到数据的维数非常之大,如果不进行相应的特征处理,那么算法的资源开销会很大,这在很多场景下是我们不能接受的。而对于数据的若干维度之间往往会存在较大的相关性,如果能将数据的维度之间进行相应的处理,使它们在保留最大数据信息的同时降低维度之间的相关性,就可以达到降维的效果。PCA(主成分分析)便是利用这样的概念将数据映射到新的维度空间中,选择最重要的几个成分作为新空间向量的基,这样在新的坐标空间中,数据既可以保留大部分的数据信息又可以达到降维的效果。在机器学习实战中对于PCA的描述太过简单,只是利用代码可能并不能为我们详细理解其背后的算法原理,通过学习一些博客,其中有一篇博客http://blog.codinglabs.org/articles/pca-tutorial.html,这篇博客通俗易懂让我从中学习到了很多,现在将学习到的知识总结如下:
数据最初所在空间的维度数目是由数据的特征数量决定的,我们想要把它映射到新的空间中,这个空间的维度数目是由数据最重要的特征所决定并且当数据映射后能够尽可能的保留数据信息,而且数据的分离程度较明显。这里就用到了数学上方差和协方差的概念,PCA算法的主要理论依据便是基于这些概念进行一步步求解优化的。
因为在http://blog.codinglabs.org/articles/pca-tutorial.html这篇博客中原理解释的非常棒,所以以下是基于这篇这博客的原理讲解,感谢博主!
向量内积以及矩阵相乘的几何意义:
两个向量内积从公式上可以看出最终得到了一个实数,也就是说内积运算是将两个向量映射为一个实数。
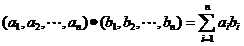
那么内积的几何意义是什么呢?其实它是将向量A投影到了B上的矢量长度。假设A和B是两个n维向量,我们知道n维向量可以等价表示为n维空间中的一条从原点发射的有向线段,为了简单起见我们假设A和B均为二维向量,则A=(x1,y1),B=(x2,y2)。则在二维平面上A和B可以用两条发自原点的有向线段表示,见下图:
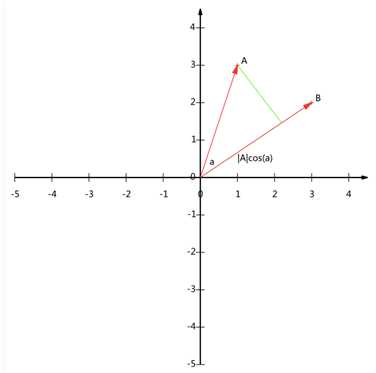
现在我们从A点向B所在直线引一条垂线。我们知道垂线与B的交点叫做A在B上的投影,再设A与B的夹角是a,则投影的矢量长度为|A|cos(a),其中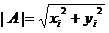
是向量A的模,也就是A线段的标量长度。注意这里我们专门区分了矢量长度和标量长度,标量长度总是大于等于0,值就是线段的长度;而矢量长度可能为负,其绝对值是线段长度,而符号取决于其方向与标准方向相同或相反。同时向量内积还有一个通用的公式:
A?B=|A||B|cos(a)
如果我们假设B的模为1,即让|B|=1,那么就变成了:A?B=|A|cos(a),也就是说设向量B的模为1,则A与B的内积值等于A向B所在直线投影的矢量长度
矩阵运算的几何意义:
如果我们确定了N维空间中的一组基,就可以利用矩阵相乘将向量在该空间中进行线性变换。现在我们有一个向量,要确定它在由N个基向量确定的空间中的具体位置,就可以利用该向量在各个基向量上的投影来确定。通常基向量都是单位正交基,这样我们可以抽取出一个方向上的基向量与该向量做内积运算,利用上一节的内积几何意义不就得到了向量在基向量上的投影,因此可以利用矩阵形式来做向量的基变换。用一个例子来说明:
在二维空间中,一般情况下我们是以(0,1)和(1,0)作为一组基的,但同时(1,1)和(-1,1)也可以成为一组基。一般来说,我们希望基的模是1,因为从内积的意义可以看到,如果基的模是1,那么就可以方便的用向量点乘基而直接获得其在新基上的坐标了!因此将其单位化上面的基可以变为和。现在,我们想获得(3,2)在新基上的坐标,即在两个方向上的投影矢量值,那么根据内积的几何意义,我们只要分别计算(3,2)和两个基的内积,不难得到新的坐标为。下图给出了新的基以及(3,2)在新基上坐标值的示意图: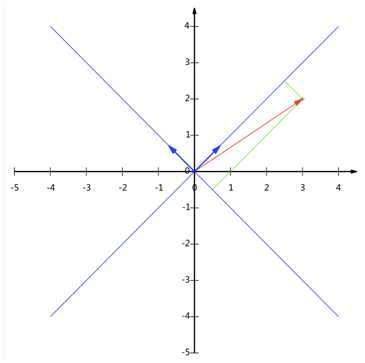
矩阵形式:
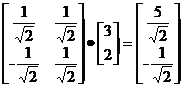
即将右边矩阵中的每一列列向量变换到左边矩阵中每一行行向量为基所表示的空间中去。
PCA算法原理:
我们在做PCA时希望能够得到数据在哪个方向上的分离程度最大并且能够保留数据的信息尽可能多。在数学上方差能够很好的表征数据的离散程度,方差越大数据越分离,我们越容易辨认。而协方差能够很好的表征数据在不同维度上的相关性。因此我们在处理数据时先对数据去均值化,将均值变为0,然后将数据矩阵乘以矩阵的转置得到了我们需要的协方差矩阵。在该协方差矩阵中,主对角线上的元素为方差,其余元素为协方差。
现在所要做的事情就是要选择出方差最大的向量方向作为基向量,以此为基础在选择与第一个基向量正交并且方差第二大的向量作为第二维度的基向量,以此类推。通常前r个方向上的基向量就能够最大化的近似原始数据,这里r远远小于n,从而达到降维的效果。因此整个逻辑就是优化协方差矩阵,将其对角化操作。由于协方差矩阵是个实对称矩阵故而其必然能够对角化,而且它的不同特征值所对应的特征向量都正交。由线性代数的知识我们可以很容易的得到协方差矩阵的特征值和特征向量,特征值表示特征向量的重要程度,特征向量则表示了数据方差变化的方向。对特征值按降序排列后,将其所对应的特征向量构成了新的坐标空间中的基向量。这样将原始数据重构于新的坐标空间,根据矩阵相乘的意义就可以做出映射后的数据。
这里证明一下为什么我们需要的空间向量基就是协方差矩阵的特征向量。设原始数据矩阵X对应的协方差矩阵为C,而P是一组基按行组成的矩阵,设Y=PX,则Y为X对P做基变换后的数据。设Y的协方差矩阵为D,我们推导一下D与C的关系:
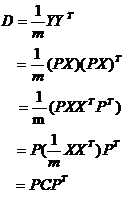
我们要找的P不是别的,而是能让原始协方差矩阵对角化的P,即就是原始数据协方差的特征向量。换句话说,优化目标变成了寻找一个矩阵P,满足PCPT是一个对角矩阵,并且对角元素按从大到小依次排列,那么P的前r行就是要寻找的基,用P的前r行组成的矩阵乘以X就使得X从N维降到了r维并满足上述优化条件。
机器学习实战应用实例:
将数据转换成前N个主成分
1 def loadData(path): 2 fr = open(path) 3 dataSet= [] 4 for line in fr.readlines(): 5 currentData = line.strip().split(‘ ‘) 6 dataSet.append(currentData) 7 dataArr = [map(float,lineData) for lineData in dataSet] 8 return mat(dataArr
#PCA
1 def PCA(dataMat,featureNum): 2 dataMean = np.mean(dataMat , axis = 0) #求均值 3 dataMat = dataMat -dataMean #数据去均值化 4 covDataMat = np.cov(dataMat,rowvar=0) #求协方差 5 featVal,featVec = linalg.eig(covDataMat) #求特征值和特征向量 6 featIndex = argsort(featVal) #对特征值排序后取前k个特征向量 7 featIndex=list(reversed(list(featIndex))) 8 featIndex = featIndex[:featureNum:1] 9 featVec = mat(featVec[:,featIndex]) 10 newDataMat = dataMat * featVec #降维 11 originMat = (newDataMat*featVec.T)+dataMean #重构原始数据 12 return newDataMat,originMat
#画图
1 def plotData(dataMat,originMat): 2 fig =plt.figure() 3 ax = fig.add_subplot(111) 4 ax.scatter(dataMat[:,0].flatten().A[0],dataMat[:,1].flatten().A[0],marker=‘^‘,s=90) 5 ax.scatter(originMat[:,0].flatten().A[0],dataMat[:,1].flatten().A[0],s=50,c=‘red‘) 6 plt.show()
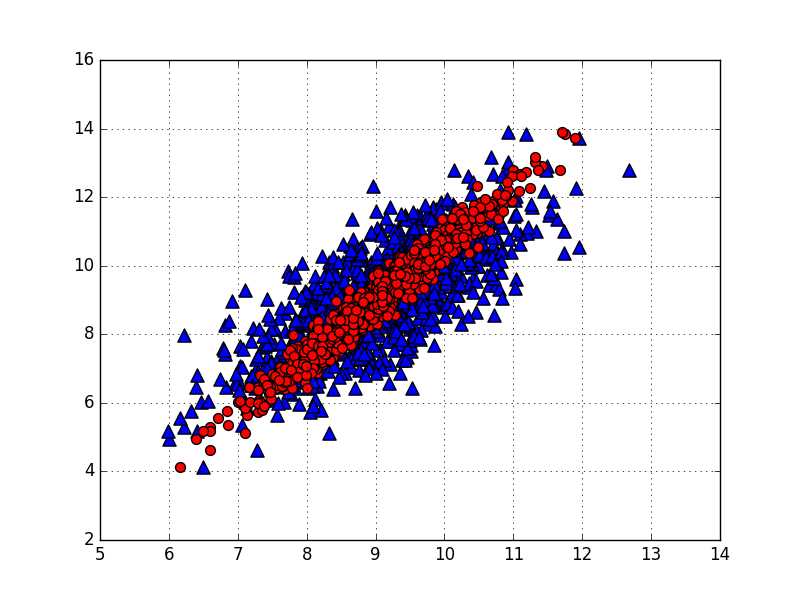
2.针对机器学习实战提供的有关半导体数据,含有590个特征。我们想要做的是,这些特征中有多少主特征,把这些主特征提取出来。由于数据中含有很多缺失值是以NaN标识的,所以第一步要用均值来代替这些数据。
1 def replaceNan(dataMat): 2 m = shape(dataMat)[1] 3 for i in range(m): 4 dataOfMean = mean(dataMat[nonzero(~isnan(dataMat[:,i]))[0],i]) 5 dataMat[nonzero(isnan(dataMat[:,i]))[0],i] = dataOfMean 6 return dataMat
稍微改动下PCA程序在里面加入判别,如果前k个主成分的累积方差占总方差的百分比大于98%就停止,选择这K个特征向量:
def PCA(dataMat,featureNum):
dataMean = np.mean(dataMat , axis = 0)
dataMat = dataMat -dataMean
covDataMat = np.cov(dataMat,rowvar=0)
featVal,featVec = linalg.eig(covDataMat)
featIndex = argsort(featVal)
featIndex=list(reversed(list(featIndex)))
featIndex = featIndex[:featureNum:1]
sumOfFeatVal = sum(featVal)
addtotal = 0.0
for k in range(featureNum):
addtotal +=featVal[featIndex[k]]
percent= addtotal / sumOfFeatVal
if percent>0.98:
print ‘the number of %d has occupied %f‘ % (k, percent)
print ‘the best number of feature is ‘,k
break
print ‘the number of %d has occupied %f‘%(k,percent)
fig = plt.figure()
ax = fig.add_subplot(111)
percentFeat = featVal[featIndex][0:20] / sumOfFeatVal
x = arange(20)
ax.plot(x, percentFeat, ‘o-‘, c=‘r‘)
plt.xlabel(‘the number of Princple feature‘)
plt.ylabel(‘var percent(%)‘)
plt.grid()
plt.show()
featVec = mat(featVec[:,featIndex])
newDataMat = dataMat * featVec
originMat = (newDataMat*featVec.T)+dataMean
return newDataMat,originMat,featVal

最后的统计结果:
the number of 0 has occupied 0.592541 the number of 1 has occupied 0.833779 the number of 2 has occupied 0.925279 the number of 3 has occupied 0.948285 the number of 4 has occupied 0.962877 the number of 5 has occupied 0.968065 the number of 6 has occupied 0.971291 the number of 7 has occupied 0.974438 the number of 8 has occupied 0.977069 the number of 9 has occupied 0.979382 the number of 10 has occupied 0.981557 the best number of feature is 10
参考:
1.博客http://blog.codinglabs.org/articles/pca-tutorial.html
2.《机器学习实战》
标签:通过 stc float current ogr pyw gray cell slax
原文地址:http://www.cnblogs.com/sunbird-cym/p/6217798.html