标签:报文 initial 回车 输出 工作 because nec 取消 ble
ChannelHandler类似于Servlet的Filter过滤器,负责对I/O事件或者I/O操作进行拦截和处理,它可以选择性地拦截和处理自己感兴趣的事件,也可以透传和终止事件的传递。基于ChannelHandler接口,用户可以方便地进行业务逻辑定制,例如打印日志、统一封装异常信息、性能统计和消息编解码等。
ChannelHandler支持注解,目前支持的注解有两种。
对于大多数的ChannelHandler会选择性地拦截和处理某个或者某些事件,其他的事件会忽略,由下一个ChannelHandler进行拦截和处理。这就会导致一个问题:用户ChannelHandler必须要实现ChannelHandler的所有接口,包括它不关心的那些事件处理接口,这会导致用户代码的冗余和臃肿,代码的可维护性也会变差。
为了解决这个问题,Netty提供了ChannelHandlerAdapter基类,它的所有接口实现都是事件透传,如果用户ChannelHandler关心某个事件,只需要覆盖ChannelHandlerAdapter对应的方法即可,对于不关心的,可以直接继承使用父类的方法,这样子类的代码就会非常简洁和清晰。
@Skip @Override public void channelRegistered(ChannelHandlerContext ctx) throws Exception { ctx.fireChannelRegistered(); } @Skip @Override public void channelActive(ChannelHandlerContext ctx) throws Exception { ctx.fireChannelActive(); } @Skip @Override public void channelInactive(ChannelHandlerContext ctx) throws Exception { ctx.fireChannelInactive(); }
这些透传方法被@Skip注解了,这些方法在执行的过程中会被忽略,直接跳到下一个ChannelHandler中执行对应的方法。
利用NIO进行网络编程时,往往需要将读取到的字节数组或者字节缓冲区解码为业务可以使用的POJO对象。为了方便业务将ByteBuf解码成业务POJO对象,Netty提供了ByteToMessageDecoder抽象工具解码类。
用户的解码器继承ByteToMessageDecoder,只需要实现void decode(ChannelHandler Context ctx, ByteBuf in, List<Object> out)抽象方法即可完成ByteBuf到POJO对象的解码。
由于ByteToMessageDecoder并没有考虑TCP粘包和组包等场景,读半包需要用户解码器自己负责处理。正因为如此,对于大多数场景不会直接继承ByteToMessageDecoder,而是继承另外一些更高级的解码器来屏蔽半包的处理。
MessageToMessageDecoder实际上是Netty的二次解码器,它的职责是将一个对象二次解码为其他对象。
为什么称它为二次解码器呢?从SocketChannel读取到的TCP数据报是ByteBuffer,实际就是字节数组,我们首先需要将ByteBuffer缓冲区中的数据报读取出来,并将其解码为Java对象;然后对Java对象根据某些规则做二次解码,将其解码为另一个POJO对象。因为MessageToMessageDecoder在ByteToMessageDecoder之后,所以称之为二次解码器。
二次解码器在实际的商业项目中非常有用,以HTTP+XML协议栈为例,第一次解码往往是将字节数组解码成HttpRequest对象,然后对HttpRequest消息中的消息体字符串进行二次解码,将XML格式的字符串解码为POJO对象,这就用到了二次解码器。类似这样的场景还有很多,不再一一枚举。
事实上,做一个超级复杂的解码器将多个解码器组合成一个大而全的MessageToMessageDecoder解码器似乎也能解决多次解码的问题,但是采用这种方式的代码可维护性会非常差。例如,如果我们打算在HTTP+XML协议栈中增加一个打印码流的功能,即首次解码获取HttpRequest对象之后打印XML格式的码流。如果采用多个解码器组合,在中间插入一个打印消息体的Handler即可,不需要修改原有的代码;如果做一个大而全的解码器,就需要在解码的方法中增加打印码流的代码,可扩展性和可维护性都会变差。用户的解码器只需要实现void decode(ChannelHandlerContext ctx, I msg, List<Object> out)抽象方法即可,由于它是将一个POJO解码为另一个POJO,所以一般不会涉及到半包的处理,相对于ByteToMessageDecoder更加简单些。
如何区分一个整包消息,通常有如下4种做法。
如果消息是通过长度进行区分的,LengthFieldBasedFrameDecoder都可以自动处理粘包和半包问题,只需要传入正确的参数,即可轻松搞定“读半包”问题。
下面我们看看如何通过参数组合的不同来实现不同的“半包”读取策略。
第一种常用的方式是消息的第一个字段是长度字段,后面是消息体,消息头中只包含一个长度字段。它的消息结构定义如图17-16所示。

使用以下参数组合进行解码。
lengthFieldOffset = 0;
lengthFieldLength = 2;
lengthAdjustment = 0;
initialBytesToStrip = 0。
解码后的字节缓冲区内容:

因为通过ByteBuf.readableBytes()方法我们可以获取当前消息的长度,所以解码后的字节缓冲区可以不携带长度字段,由于长度字段在起始位置并且长度为2,所以将initialBytesToStrip设置为2,参数组合修改为:
lengthFieldOffset = 0;
lengthFieldLength = 2;
lengthAdjustment = 0;
initialBytesToStrip = 2。
解码后的字节缓冲区内容如图:

从图17-18的解码结果看,解码后的字节缓冲区丢弃了长度字段,仅仅包含消息体,不过通过ByteBuf.readableBytes()方法仍然能够获取到长度字段的值。
在大多数的应用场景中,长度仅用来标识消息体的长度,这类协议通常由消息长度字段+消息体组成,如图17-18所示的例子。但是,对于一些协议,长度还包含了消息头的长度。在这种应用场景中,往往需要使用lengthAdjustment进行修正,修正后的参数组合方式如下。由于整个消息的长度往往都大于消息体的长度,所以,lengthAdjustment为负数,图17-19展示了通过指定lengthAdjustment字段来包含消息头的长度。
lengthFieldOffset = 0;
lengthFieldLength = 2;
lengthAdjustment = -2;
initialBytesToStrip = 0。

第二种常用的方式是当标识消息长度的字段位于消息头的中间或者尾部时,需要使用lengthFieldOffset字段进行标识,下面的参数组合给出了如何解决消息长度字段不在首位的问题。
lengthFieldOffset = 2;
lengthFieldLength = 3;
lengthAdjustment = 0;
initialBytesToStrip = 0。

由于消息头1的长度为2,所以长度字段的偏移量为2;消息长度字段Length为3,所以lengthFieldLength值为3。由于长度字段仅仅标识消息体的长度,所以lengthAdjustment和initialBytesToStrip都为0。
第三种常用的方式是长度字段夹在两个消息头之间或者长度字段位于消息头的中间,前后都有其他消息头字段,在这种场景下如果想忽略长度字段以及其前面的其他消息头字段,则可以通过initialBytesToStrip参数来跳过要忽略的字节长度,它的组合效果如下。
lengthFieldOffset = 1;
lengthFieldLength = 2;
lengthAdjustment = 1;
initialBytesToStrip = 3。

首先,由于HDR1的长度为1,所以长度字段的偏移量lengthFieldOffset为1;长度字段为2个字节,所以lengthFieldLength为2。由于长度字段是消息体的长度,解码后如果携带消息头中的字段,则需要使用lengthAdjustment进行调整,此处它的值为1,表示的是HDR2的长度,最后由于解码后的缓冲区要忽略长度字段和HDR1部分,所以initialBytesToStrip为3。解码后的结果为13个字节,HDR1和Length字段被忽略。
事实上,通过4个参数的不同组合,可以达到不同的解码效果,用户在使用过程中可以根据业务的实际情况进行灵活调整。
MessageToByteEncoder负责将POJO对象编码成ByteBuf,用户的编码器继承MessageToByteEncoder,实现void encode(ChannelHandlerContext ctx, I msg, ByteBuf out)接口接口,示例代码如下。
public class IntegerEncoder extends MessageToByteEncoder { @Override public void encode(ChannelHandlerContext ctx, Integer msg,ByteBuf out) throws Exception { out.writeInt(msg); } }
用户的编码器继承MessageToMessageEncoder解码器,实现void encode(Channel HandlerContext ctx, I msg, List out)方法即可。注意,它与MessageToByteEncoder的区别是输出是对象列表而不是ByteBuf。
如果协议中的第一个字段为长度字段,Netty提供了LengthFieldPrepender编码器,它可以计算当前待发送消息的二进制字节长度,将该长度添加到ByteBuf的缓冲区头中。

通过LengthFieldPrepender可以将待发送消息的长度写入到ByteBuf的前2个字节,编码后的消息组成为长度字段+原消息的方式。
通过设置LengthFieldPrepender为true,消息长度将包含长度本身占用的字节数,打开LengthFieldPrepender后(0x000E):

相对于ByteBuf和Channel,ChannelHandler的类继承关系稍微简单些,但是它的子类非常多。由于ChannelHandler是Netty框架和用户代码的主要扩展和定制点,所以它的子类种类繁多、功能各异,系统ChannelHandler主要分类如下:
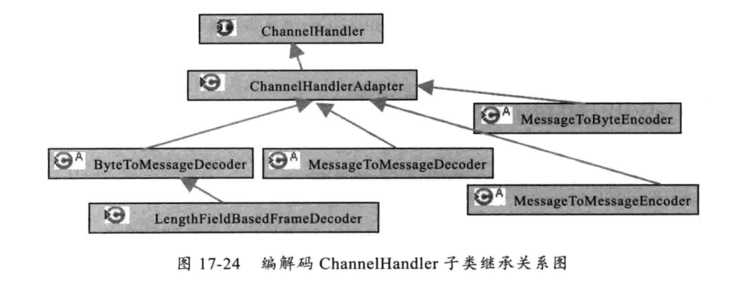
顾名思义,ByteToMessageDecoder解码器用于将ByteBuf解码成POJO对象。
首先看channelRead方法的源码:
@Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { //首先判断需要解码的msg对象是否是ByteBuf,如果是ByteBuf才需要进行解码,否则直接透传。 if (msg instanceof ByteBuf) { RecyclableArrayList out = RecyclableArrayList.newInstance(); try { ByteBuf data = (ByteBuf) msg; //通过cumulation是否为空判断解码器是否缓存了没有解码完成的半包消息 first = cumulation == null; if (first) { //如果为空,说明是首次解码或者最近一次已经处理完了半包消息,没有缓存的半包消息需要处理,直接将需要解码的ByteBuf赋值给cumulation; cumulation = data; } else { //如果cumulation缓存有上次没有解码完成的ByteBuf,则进行复制操作,将需要解码的ByteBuf复制到cumulation中 //在复制之前需要对cumulation的可写缓冲区进行判断,如果不足则需要动态扩展 if (cumulation.writerIndex() > cumulation.maxCapacity() - data.readableBytes()) { //扩展的代码很简单,利用字节缓冲区分配器重新分配一个新的ByteBuf,将老的cumulation复制到新的ByteBuf中,释放cumulation。 //此处内存扩展没有采用倍增或者步进的方式,分配的缓冲区恰恰够用,此处的算法可以优化下,以防止连续半包导致的频繁缓冲区扩张和内存复制。 expandCumulation(ctx, data.readableBytes()); } //半包解码前:(半包消息1= cumulation.readableBytes()) //半包解码后:(半包消息2= data.readableBytes()=半包消息1+msg.readableBytes()) cumulation.writeBytes(data); data.release(); } //复制操作完成之后释放需要解码的ByteBuf对象,调用callDecode方法进行解码 //对ByteBuf进行循环解码,循环的条件是解码缓冲区对象中有可读的字节 //调用抽象decode方法,由用户的子类解码器进行解码 //解码后需要对当前的pipeline状态和解码结果进行判断 //如果当前的ChannelHandlerContext已经被移除,则不能继续进行解码,直接退出循环; //如果输出的out列表长度没变化,说明解码没有成功,需要针对以下不同场景进行判断。 //A.如果用户解码器没有消费ByteBuf,则说明是个半包消息,需要由I/O线程继续读取后续的数据报,在这种场景下要退出循环。 //B.如果用户解码器消费了ByteBuf,说明可以解码可以继续进行。业务解码器需要遵守Netty的某些契约,解码器才能正常工作,否则可能会导致功能错误 //最重要的契约就是:如果业务解码器认为当前的字节缓冲区无法完成业务层的解码,需要将readIndex复位,告诉Netty解码条件不满足应当退出解码,继续读取数据报。 //如果用户解码器没有消费ByteBuf,oldInputLength == in.readableBytes(),但是却解码出了一个或者多个对象,这种行为被认为是非法的,需要抛出DecoderException异常。 //最后通过isSingleDecode进行判断,如果是单条消息解码器,第一次解码完成之后就退出循环。 callDecode(ctx, cumulation, out); } catch (DecoderException e) { throw e; } catch (Throwable t) { throw new DecoderException(t); } finally { if (cumulation != null && !cumulation.isReadable()) { cumulation.release(); cumulation = null; } int size = out.size(); decodeWasNull = size == 0; for (int i = 0; i < size; i ++) { ctx.fireChannelRead(out.get(i)); } out.recycle(); } } else { ctx.fireChannelRead(msg); } }
MessageToMessageDecoder负责将一个POJO对象解码成另一个POJO对象。
首先看channelRead方法的源码:
@Override public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception { //先通过RecyclableArrayList创建一个新的可循环利用的RecyclableArrayList, RecyclableArrayList out = RecyclableArrayList.newInstance(); try { //对解码的消息类型进行判断,通过类型参数校验器看是否是可接收的类型,如果是则校验通过 if (acceptInboundMessage(msg)) { @SuppressWarnings("unchecked") I cast = (I) msg; try { //直接调用decode抽象方法,由具体实现子类进行消息解码 decode(ctx, cast, out); } finally { //解码完成之后,调用ReferenceCountUtil的release方法来释放被解码的msg对象。 ReferenceCountUtil.release(cast); } } else { //如果需要解码的对象不是当前解码器可以接收和处理的类型,则将它加入到RecyclableArrayList中不进行解码。 out.add(msg); } } catch (DecoderException e) { throw e; } catch (Exception e) { throw new DecoderException(e); } finally { int size = out.size(); //最后,对RecyclableArrayList进行遍历,循环调用ChannelHandlerContext的fireChannelRead方法, //通知后续的ChannelHandler继续进行处理。循环通知完成之后,通过recycle方法释放RecyclableArrayList对象。 for (int i = 0; i < size; i ++) { ctx.fireChannelRead(out.get(i)); } out.recycle(); } }
最通用和重要的解码器——基于消息长度的半包解码器。
@Override protected final void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception { //调用内部的decode(ChannelHandlerContext ctx, ByteBuf in)方法,如果解码成功,将其加入到输出的List<Object> out列表中。 Object decoded = decode(ctx, in); if (decoded != null) { out.add(decoded); } } protected Object decode(ChannelHandlerContext ctx, ByteBuf in) throws Exception { //判断discardingTooLongFrame标识,看是否需要丢弃当前可读的字节缓冲区,如果为真,则执行丢弃操作 if (discardingTooLongFrame) { long bytesToDiscard = this.bytesToDiscard; //判断需要丢弃的字节长度,由于丢弃的字节数不能大于当前缓冲区可读的字节数,所以需要通过Math.min(bytesToDiscard, in.readableBytes())函数进行选择, //取bytesToDiscard和缓冲区可读字节数之中的最小值。 int localBytesToDiscard = (int) Math.min(bytesToDiscard, in.readableBytes()); //计算获取需要丢弃的字节数之后,调用ByteBuf的skipBytes方法跳过需要忽略的字节长度, in.skipBytes(localBytesToDiscard); //然后bytesToDiscard减去已经忽略的字节长度。 bytesToDiscard -= localBytesToDiscard; this.bytesToDiscard = bytesToDiscard; //最后判断是否已经达到需要忽略的字节数,达到的话对discardingTooLongFrame等进行置位 failIfNecessary(false); } //对当前缓冲区的可读字节数和长度偏移量进行对比,如果小于长度偏移量,则说明当前缓冲区的数据报不够,需要返回空,由I/O线程继续读取后续的数据报。 if (in.readableBytes() < lengthFieldEndOffset) { return null; } int actualLengthFieldOffset = in.readerIndex() + lengthFieldOffset; //通过读索引和lengthFieldOffset计算获取实际的长度字段索引,然后通过索引值获取消息报文的长度字段 //根据长度字段自身的字节长度进行判断,共有以下6种可能的取值。 //长度所占字节为1,通过ByteBuf的getUnsignedByte方法获取长度值; //长度所占字节为2,通过ByteBuf的getUnsignedShort方法获取长度值; //长度所占字节为3,通过ByteBuf的getUnsignedMedium方法获取长度值; //长度所占字节为4,通过ByteBuf的getUnsignedInt方法获取长度值; //长度所占字节为8,通过ByteBuf的getLong方法获取长度值; //其他长度不支持,抛出DecoderException异常。 long frameLength = getUnadjustedFrameLength(in, actualLengthFieldOffset, lengthFieldLength, byteOrder); //如果长度小于0,说明报文非法,跳过lengthFieldEndOffset个字节,抛出Corrupted FrameException异常。 if (frameLength < 0) { in.skipBytes(lengthFieldEndOffset); throw new CorruptedFrameException( "negative pre-adjustment length field: " + frameLength); } //根据lengthFieldEndOffset和lengthAdjustment字段进行长度修正 frameLength += lengthAdjustment + lengthFieldEndOffset; //如果修正后的报文长度小于lengthFieldEndOffset,则说明是非法数据报,需要抛出CorruptedFrameException异常。 if (frameLength < lengthFieldEndOffset) { in.skipBytes(lengthFieldEndOffset); throw new CorruptedFrameException( "Adjusted frame length (" + frameLength + ") is less " + "than lengthFieldEndOffset: " + lengthFieldEndOffset); } //如果修正后的报文长度大于ByteBuf的最大容量,说明接收到的消息长度大于系统允许的最大长度上限, //需要设置discardingTooLongFrame,计算需要丢弃的字节数,根据情况选择是否需要抛出解码异常。 if (frameLength > maxFrameLength) { //丢弃的策略如下:frameLength减去ByteBuf的可读字节数就是需要丢弃的字节长度, //如果需要丢弃的字节数discard小于缓冲区可读的字节数,则直接丢弃整包消息。 //如果需要丢弃的字节数大于当前可读字节数,说明即便当前所有可读的字节数全部丢弃,也无法完成任务,则设置discardingTooLongFrame为true,下次解码的时候继续丢弃。 //丢弃操作完成之后,调用failIfNecessary方法根据实际情况抛出异常。 long discard = frameLength - in.readableBytes(); tooLongFrameLength = frameLength; if (discard < 0) { // buffer contains more bytes then the frameLength so we can discard all now in.skipBytes((int) frameLength); } else { // Enter the discard mode and discard everything received so far. discardingTooLongFrame = true; bytesToDiscard = discard; in.skipBytes(in.readableBytes()); } failIfNecessary(true); return null; } //如果当前的可读字节数小于frameLength,说明是个半包消息,需要返回空,由I/O线程继续读取后续的数据报,等待下次解码。 // never overflows because it‘s less than maxFrameLength int frameLengthInt = (int) frameLength; if (in.readableBytes() < frameLengthInt) { return null; } //对需要忽略的消息头字段进行判断,如果大于消息长度frameLength,说明码流非法,需要忽略当前的数据报,抛出CorruptedFrameException异常。 if (initialBytesToStrip > frameLengthInt) { in.skipBytes(frameLengthInt); throw new CorruptedFrameException( "Adjusted frame length (" + frameLength + ") is less " + "than initialBytesToStrip: " + initialBytesToStrip); } //通过ByteBuf的skipBytes方法忽略消息头中不需要的字段,得到整包ByteBuf。 in.skipBytes(initialBytesToStrip); int readerIndex = in.readerIndex(); int actualFrameLength = frameLengthInt - initialBytesToStrip; //通过extractFrame方法获取解码后的整包消息缓冲区 //根据消息的实际长度分配一个新的ByteBuf对象,将需要解码的ByteBuf可写缓冲区复制到新创建的ByteBuf中并返回, //返回之后更新原解码缓冲区ByteBuf为原读索引+消息报文的实际长度(actualFrameLength)。 ByteBuf frame = extractFrame(ctx, in, readerIndex, actualFrameLength); in.readerIndex(readerIndex + actualFrameLength); return frame; }
至此,基于长度的半包解码器介绍完毕,对于使用者而言,实际不需要对LengthFieldBasedFrameDecoder进行定制。只需要了解每个参数的用法,再结合用户的业务场景进行参数设置,即可实现半包消息的自动解码,后面的业务解码器得到的是个完整的整包消息,不用再额外考虑如何处理半包。这极大地降低了开发难度,提升了开发效率。
MessageToByteEncoder负责将用户的POJO对象编码成ByteBuf,以便通过网络进行传输。
@Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { ByteBuf buf = null; try { //首先判断当前编码器是否支持需要发送的消息,如果不支持则直接透传; if (acceptOutboundMessage(msg)) { @SuppressWarnings("unchecked") I cast = (I) msg; //对于直接内存分配ioBuffer(堆外内存),对于堆内存通过heapBuffer方法分配。 if (preferDirect) { buf = ctx.alloc().ioBuffer(); } else { buf = ctx.alloc().heapBuffer(); } try { //编码使用的缓冲区分配完成之后,调用encode抽象方法进行编码, encode(ctx, cast, buf); } finally { //编码完成之后,调用ReferenceCountUtil的release方法释放编码对象msg。 ReferenceCountUtil.release(cast); } //对编码后的ByteBuf进行以下判断。 //如果缓冲区包含可发送的字节,则调用ChannelHandlerContext的write方法发送ByteBuf; //如果缓冲区没有包含可写的字节,则需要释放编码后的ByteBuf,写入一个空的ByteBuf到ChannelHandlerContext中。 if (buf.isReadable()) { ctx.write(buf, promise); } else { buf.release(); ctx.write(Unpooled.EMPTY_BUFFER, promise); } //发送操作完成之后,在方法退出之前释放编码缓冲区ByteBuf对象。 buf = null; } else { //如果不支持则直接透传; ctx.write(msg, promise); } } catch (EncoderException e) { throw e; } catch (Throwable e) { throw new EncoderException(e); } finally { //发送操作完成之后,在方法退出之前释放编码缓冲区ByteBuf对象。 if (buf != null) { buf.release(); } } }
MessageToMessageEncoder负责将一个POJO对象编码成另一个POJO对象,例如将XML Document对象编码成XML格式的字符串。
@Override public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception { RecyclableArrayList out = null; try { //创建RecyclableArrayList对象,判断当前需要编码的对象是否是编码器可处理的类型,如果不是,则忽略,执行下一个ChannelHandler的write方法。 if (acceptOutboundMessage(msg)) { out = RecyclableArrayList.newInstance(); @SuppressWarnings("unchecked") I cast = (I) msg; try { //具体的编码方法实现由用户子类编码器负责完成 encode(ctx, cast, out); } finally { ReferenceCountUtil.release(cast); } //如果编码后的RecyclableArrayList为空,说明编码没有成功,释放RecyclableArrayList引用。 if (out.isEmpty()) { out.recycle(); out = null; throw new EncoderException( StringUtil.simpleClassName(this) + " must produce at least one message."); } } else { ctx.write(msg, promise); } } catch (EncoderException e) { throw e; } catch (Throwable t) { throw new EncoderException(t); } finally { //如果编码成功,则通过遍历RecyclableArrayList,循环发送编码后的POJO对象 if (out != null) { final int sizeMinusOne = out.size() - 1; if (sizeMinusOne >= 0) { for (int i = 0; i < sizeMinusOne; i ++) { ctx.write(out.get(i)); } ctx.write(out.get(sizeMinusOne), promise); } out.recycle(); } } }
LengthFieldPrepender负责在待发送的ByteBuf消息头中增加一个长度字段来标识消息的长度,它简化了用户的编码器开发,使用户不需要额外去设置这个长度字段。
@Override protected void encode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out) throws Exception { int length = msg.readableBytes() + lengthAdjustment; //首先对长度字段进行设置,如果需要包含消息长度自身,则在原来长度的基础之上再加上lengthFieldLength的长度。 if (lengthIncludesLengthFieldLength) { length += lengthFieldLength; } //如果调整后的消息长度小于0,则抛出参数非法异常。 if (length < 0) { throw new IllegalArgumentException( "Adjusted frame length (" + length + ") is less than zero"); } //对消息长度自身所占的字节数进行判断,以便采用正确的方法将长度字段写入到ByteBuf中,共有以下6种可能。 switch (lengthFieldLength) { case 1: //长度字段所占字节为1:如果使用1个Byte字节代表消息长度,则最大长度需要小于256个字节。对长度进行校验,如果校验失败,则抛出参数非法异常; //若校验通过,则创建新的ByteBuf并通过writeByte将长度值写入到ByteBuf中。 if (length >= 256) { throw new IllegalArgumentException( "length does not fit into a byte: " + length); } out.add(ctx.alloc().buffer(1).writeByte((byte) length)); break; case 2: //长度字段所占字节为2:如果使用2个Byte字节代表消息长度,则最大长度需要小于65536个字节,对长度进行校验,如果校验失败,则抛出参数非法异常; //若校验通过,则创建新的ByteBuf并通过writeShort将长度值写入到ByteBuf中。 if (length >= 65536) { throw new IllegalArgumentException( "length does not fit into a short integer: " + length); } out.add(ctx.alloc().buffer(2).writeShort((short) length)); break; case 3: //长度字段所占字节为3:如果使用3个Byte字节代表消息长度,则最大长度需要小于16777216个字节,对长度进行校验,如果校验失败,则抛出参数非法异常; //若校验通过,则创建新的ByteBuf并通过writeMedium将长度值写入到ByteBuf中。 if (length >= 16777216) { throw new IllegalArgumentException( "length does not fit into a medium integer: " + length); } out.add(ctx.alloc().buffer(3).writeMedium(length)); break; case 4: //长度字段所占字节为4:创建新的ByteBuf,并通过writeInt将长度值写入到ByteBuf中。 out.add(ctx.alloc().buffer(4).writeInt(length)); break; case 8: //长度字段所占字节为8:创建新的ByteBuf,并通过writeLong将长度值写入到ByteBuf中。 out.add(ctx.alloc().buffer(8).writeLong(length)); break; default: //其他长度值:直接抛出Error。 throw new Error("should not reach here"); } //最后将原需要发送的ByteBuf复制到List<Object> out中,完成编码。 out.add(msg.retain()); }
标签:报文 initial 回车 输出 工作 because nec 取消 ble
原文地址:http://www.cnblogs.com/wade-luffy/p/6222960.html