标签:unix 连接 原理 标准 整数 while循环 系统 字节 芯片
1.1 信息就是位+上下文
include <stdio.h> int main() { printf("hello,world\n"); }
这段C程序源代码是以文本文件的形式保存,名称为hello.c。程序员利用编辑器编写的源代码都是文本文件。
大部分系统都是使用ASCII码表示文本字符,每个字符都是以单字节的整数值表示,每个字是一个整数值,如下图所示为代码的第一行。其他的所有文件都称为二进制文件。
| # | i | n | c | l | u | d | e | <space> | < | s | t | d | i | o | . | h | > |
| 35 | 105 | 110 | 99 | 108 | 117 | 100 | 101 | 32 | 60 | 115 | 116 | 100 | 105 | 111 | 46 | 104 | 62 |
系统中所有的信息--磁盘文件、存储器中的程序、存储器中的用户数据、网络上的数据等,都是有一串位表示的。区分不同数据的唯一方法是这些数据的上下文。如果上下文表示了这个文件是一个文本文件,那么就如同上图,每个数字对应的是一个字符。如果是个二进制文件,例如:图像、声音、视频、可执行的文件,那么文件中的数字都是代表其本身的意义。同一个数字,文件类型的不同,代表意义就不同。
1.2 程序被其他程序翻译成不同的格式
hello程序要被计算机执行,需要转换成低级机器语言指令。低级机器语言指令由二进制的数构成。
从文本文件形式的源代码转化到机器能读懂的二进制文件是由编译器完成。编译器也是程序。编译器转化过程分为四个阶段:
hello.c源文件 -> 预处理器:被修改的源文件= hello.i(仍是文本)
hello.i -> 编译器 = hello.s汇编程序(仍是文本) hello.s -> 汇编器 = hello.o (二进制) hello.o -> 链接器 = hello 可执行程序 (二进制)
一,预处理阶段:根据#include <stdio.h>命令 将读取系统头文件stdio.h的内容,将其插入到hello.c文件中,得到了hello.i文件。(stdio.h也是C源代码)
二,编译阶段: 将C语言源代码翻译成汇编语言源代码。汇编语言属于低级的机器语言指令。汇编语言跟硬件相关性很强,不同的硬件会有不同的汇编语言。汇编语言属于低级语言。不同的高级语言,在相同硬件的机器上通过自身语言的编译器编译出的汇编语言是相同的。
三,汇编阶段:汇编器将hello.s汇编语言源代码翻译成机器指令,并把这些指令打包成hello.o(二进制文件)。hello.o是二进制文件,它的每个字节的二进制数字代表的是机器语言指令,并不代表一个文本字符。所以,用文本编辑器打开一个二进制文件时,里面显示的是乱码。
四,链接阶段:hello.c中调用了printf函数。这个函数是每个C编译器都会提供的标准C库的一个函数。printf函数存在于名为printf.o的已经编译好了的目标文件中。通过连接,就可以将printf.o目标文件合并到hello.o文件中,最终得到了hello文件,这是一个可执行目标文件。
1.3 了解编译系统如何工作是大有益处的
1.4 处理器读并解释存储在存储器中的指令
unix以及类unix系统中,shell是一个程序。它是人机交互界面,用户通过shell给机器发出指令。它接收用户输入的指令,如果第一个字符不是内置的shell命令,那么shell会认为是一个可执行文件的名称,加载并执行这个文件。
1.4.1 系统的硬件组成
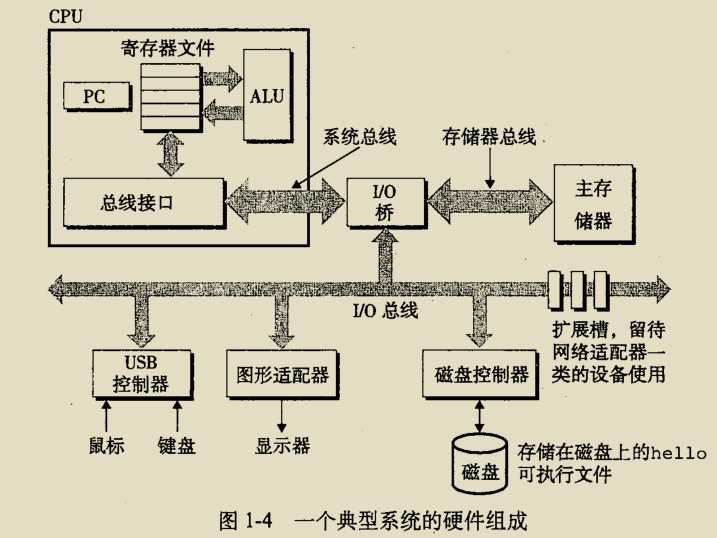
1.总线
总线是一组电子管,各个计算机的部件通过它传送数据信息。总线传送数据的长度,是一个定长的字节快,称为字。字的字节数称为字长,根据系统的不同而不同。32位总线的字长是4字节,64位总线的字长就是8字节。总线传送数据都是一个字一个字的传送,那么根据系统不同,32位的机器每次能传送4个字节,64位的每次能传送8个字节。
2.I/O设备
键盘、鼠标、显示器、磁盘这些都是I/O设备。每个I/O设备都通过一个控制器或适配器与总线相连。
3.主存
主存由一组动态随机存取储存器芯片组成。从逻辑上讲,主存每个储存单位为1个字节,每个字节都有其唯一的地址,地址从0开始。
4.处理器
CPU核心是一个字长的存储设备,称为程序计数器(PC)。PC在任何时刻,都指向主存中的某条机器语言指令(即保存的是该指令所在主存的地址)。
标签:unix 连接 原理 标准 整数 while循环 系统 字节 芯片
原文地址:http://www.cnblogs.com/mysic/p/6224379.html