标签:包括 对象 and issues 版本 机器人 机器 creating reset
英文版:https://gym.openai.com/docs
2016年 5 月 4日,OpenAI发布了人工智能研究工具集 OpenAI Gym。OpenAI Gym是一款用于研发和比较学习算法的工具包。它与很多数值计算库兼容,比如tensorflow和theano。现在支持的语言主要是python。
openai gym 是一个增强学习(reinforcement learning,RL)算法的测试床(testbed)。增强学习和有监督学习的评测不一样。有监督学习的评测工具是数据。只要提供一批有标注的数据18:34:13就能进行有监督学习的评测。增强学习的评测工具是环境。需要提供一个环境给 Agent 运行,才能评测 Agent 的策略的优劣。OpenAI Gym 是提供各种环境的开源工具包。
增强学习有几个基本概念:
(1) agent:智能体,也就是机器人,你的代码本身。
(2) environment:环境,也就是游戏本身,openai gym提供了多款游戏,也就是提供了多个环境。
(3) action:行动,比如玩超级玛丽,向上向下等动作。
(4) state:状态,每次智能体做出行动,环境会相应地做出反应,返回一个状态和奖励。
(5) reward:奖励:根据游戏规则的得分。智能体不知道怎么才能得分,它通过不断地尝试来理解游戏规则,比如它在这个状态做出向上的动作,得分,那么下一次它处于这个环境状态,就倾向于做出向上的动作。
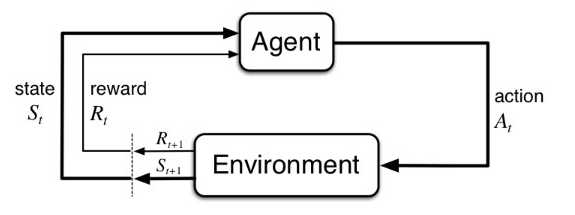
OpenAI Gym由两部分组成:
gym的代码在这上面:https://github.com/openai/gym
gym的核心接口是Env,作为统一的环境接口。Env包含下面几个核心方法:
1、reset(self):重置环境的状态,返回观察。
2、step(self,action):推进一个时间步长,返回observation,reward,done,info
3、render(self,mode=’human’,close=False):重绘环境的一帧。默认模式一般比较友好,如弹出一个窗口。
1.Linux(没试过):
apt-get install -y python-numpy python-dev cmake zlib1g-dev libjpeg-dev xvfb libav-tools xorg-dev python-opengl libboost-all-dev libsdl2-dev swig
2.Windows(有两种方法):
(1)使用pip:
pip install gym
(2)使用git:
git clone https://github.com/openai/gym cd gym pip install -e . # minimal install pip install -e .[all] # full install (this requires cmake and a recent pip version)
接下来以cartpole-v0(https://gym.openai.com/envs/CartPole-v0)举例。

这个游戏的规则是让杆不倒。Openai gym提供了行动的集合,环境的集合等等。Cartpole-v0来说,动作空间包括向左拉和向右拉两个动作。其实你并不需要关心它的动作空间是什么,当你的学习算法越好,你就越不需要解释这些动作。
运行CartPole-v0环境1000个时间步(timestep)。
import gym env = gym.make(‘CartPole-v0‘) env.reset() for _ in range(1000): env.render() env.step(env.action_space.sample()) # take a random action
可以看到随机控制算法发散,游戏很快结束。
如果我们想做得好一点,观察周围的环境是必须的。环境的step函数返回四个值:
这是一个典型的“智能体-环境循环”的实现。每个时间步长(timestep),智能体选择一个行动,环境返回一个观察和奖励值。
过程一开始调用reset,返回一个初始的观察。并根据done判断是否再次reset。
import gym env = gym.make(‘CartPole-v0‘) for i_episode in range(20): observation = env.reset() for t in range(100): env.render() print(observation) action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("Episode finished after {} timesteps".format(t+1)) break
以上代码有20个episode,打印每次的环境观察值,随机采取行动,返回环境的观察值、奖励、done和调试信息。当done为true时,该episode结束,开始下一个episode。可以看到,观察了环境,每次坚持的时间好像稍微长了一点。
运行结果如下:
[-0.061586 -0.75893141 0.05793238 1.15547541] [-0.07676463 -0.95475889 0.08104189 1.46574644] [-0.0958598 -1.15077434 0.11035682 1.78260485] [-0.11887529 -0.95705275 0.14600892 1.5261692 ] [-0.13801635 -0.7639636 0.1765323 1.28239155] [-0.15329562 -0.57147373 0.20218013 1.04977545] Episode finished after 14 timesteps [-0.02786724 0.00361763 -0.03938967 -0.01611184] [-0.02779488 -0.19091794 -0.03971191 0.26388759] [-0.03161324 0.00474768 -0.03443415 -0.04105167]
import gym env = gym.make(‘CartPole-v0‘) print(env.action_space) #> Discrete(2) print(env.observation_space) #> Box(4,)
在上面这个例子中,action取非负整数0或1。Box表示一个n维的盒子,因此observation是一个4维的数组。我们可以试试box的上下限。
print(env.observation_space.high) #> array([ 2.4 , inf, 0.20943951, inf]) print(env.observation_space.low) #> array([-2.4 , -inf, -0.20943951, -inf])
Box和discrete是最常见的space。你可以从space中取样或者验证是否属于它。
from gym import spaces space = spaces.Discrete(8) # Set with 8 elements {0, 1, 2, ..., 7} x = space.sample() assert space.contains(x) assert space.n == 8
环境
Gym的主要目的是提供一个大环境集合,具有一个公共接口,并且允许比较算法。你可以列出这些环境。
from gym import envs print(envs.registry.all()) #> [EnvSpec(DoubleDunk-v0), EnvSpec(InvertedDoublePendulum-v0), EnvSpec(BeamRider-v0), EnvSpec(Phoenix-ram-v0), EnvSpec(Asterix-v0), EnvSpec(TimePilot-v0), EnvSpec(Alien-v0), EnvSpec(Robotank-ram-v0), EnvSpec(CartPole-v0), EnvSpec(Berzerk-v0), EnvSpec(Berzerk-ram-v0), EnvSpec(Gopher-ram-v0), ...
这列出了一系列的EnvSpec。它们为特定任务定义特定参数,包括运行的实验数目和最多的步数。比如,EnvSpec(Hopper-v1)定义了一个环境,环境的目标是让一个2D的模拟机器跳跃。EnvSpec(Go9x9-v0)定义了9*9棋盘上的围棋游戏。
这些环境ID被视为不透明字符串。为了确保与未来的有效比较,环境永远不会以影响性能的方式更改,只能由较新的版本替代。 我们目前使用v0为每个环境添加后缀,以便将来的替换可以自然地称为v1,v2等。
Gym使得记录算法在环境中的性能变得简单,同时能记录学习过程的视频。只要使用monitor如下:
import gym env = gym.make(‘CartPole-v0‘) env.monitor.start(‘/tmp/cartpole-experiment-1‘) for i_episode in range(20): observation = env.reset() for t in range(100): env.render() print(observation) action = env.action_space.sample() observation, reward, done, info = env.step(action) if done: print("Episode finished after {} timesteps".format(t+1)) break env.monitor.close()
跑了一下发现有错:
env.monitor is deprecated. Wrap your env with gym.wrappers.Monitor to record data.
改为如下:
from gym.wrappers import Monitor env = Monitor(directory=‘/tmp/cartpole-experiment-0201‘,video_callable=False, write_upon_reset=True)(env) env.close()
(mark一下找bug思路,gym\monitoring\tests里面有测试的案例,参考test_monitor.py写代码。)
产生的结果放到‘/tmp/cartpole-experiment-1‘这个文件夹中,你可以加载到评分板。

monitor支持将一个环境的多个案例写入一个单独的目录。
然后你可以把你的结果加载到OpenAI Gym:
import gym gym.upload(‘/tmp/cartpole-experiment-1‘, api_key=‘ sk_FYp0Gc1dQU69epifs7ZE6w‘)
输出应该是这样:
[2016-04-22 23:16:03,123] Uploading 20 episodes of training data [2016-04-22 23:16:04,194] Uploading videos of 2 training episodes (6306 bytes) [2016-04-22 23:16:04,437] Creating evaluation object on the server with learning curve and training video [2016-04-22 23:16:04,677] **************************************************** You successfully uploaded your agent evaluation to OpenAI Gym! You can find it at: https://gym.openai.com/evaluations/eval_tmX7tssiRVtYzZk0PlWhKA
估值
每次加载会产生一个估值对象。官方文件说,应该创建一个Gist(被墙了)显示怎么复制你的结果。估值页会有一个如下方框:
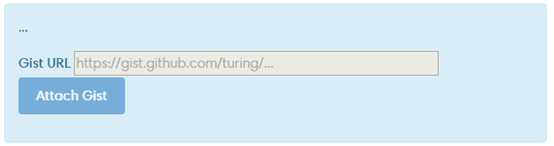
你还可以在加载的时候提供你的gist,通过一个writeup参数
import gym gym.upload(‘/tmp/cartpole-experiment-1‘, writeup=‘https://gist.github.com/gdb/b6365e79be6052e7531e7ba6ea8caf23‘, api_key=‘ sk_FYp0Gc1dQU69epifs7ZE6w‘)
这一步是将你的结果提交到在线网站上进行评估,你的结果会被自动评分,并且会产生一个漂亮的界面,如:
https://gym.openai.com/evaluations/eval_Ir5NHkdNRGqvmpBDcdNNNw
在大多数环境中,你的目标是用最少的步数达到性能的要求(有一个阈值)。而在一些特别复杂的环境中,阈值是什么还不清楚,因此,你的目标是最优化性能。
注意,现在writeup被舍弃了,所以不需要writeup。
另外,api_key是指
再mark一个错误:
raise error.Error("[%s] You didn‘t have any recorded training data in {}. Once you‘ve used ‘env.monitor.start(training_dir)‘ to start recording, you need to actually run some rollouts. Please join the community chat on https://gym.openai.com if you have any issues.".format(env_id, training_dir))
这是由于之前更改monitor,改成调用wrappers里面的文件时候出的错。将结果放到‘/tmp/cartpole-experiment-1‘这个文件夹的时候出错,也就是在monitor这一步出错,通过查看文件夹里面的文件也可看到文件夹里面的文件大小都很小,内容也不对,如下:


因此从monitor入手更改。
改完之后产生的文件如下:
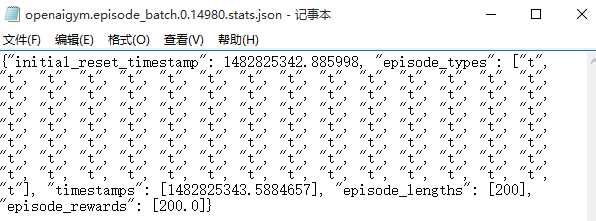
标签:包括 对象 and issues 版本 机器人 机器 creating reset
原文地址:http://www.cnblogs.com/mandalalala/p/6227201.html