标签:位置 作用 localhost yarn amp 技术分享 分配 cut oca
Spark 使用主从架构,有一个中心协调器和许多分布式worker。
中心协调器被称为driver。Driver 和被称为executor 的大量分布式worker 通信
Driver 运行在它自己的Java 进程,而每个executor 是单独的Java 进程。Driver
和它的所有executor 一起被称为Spark 应用。
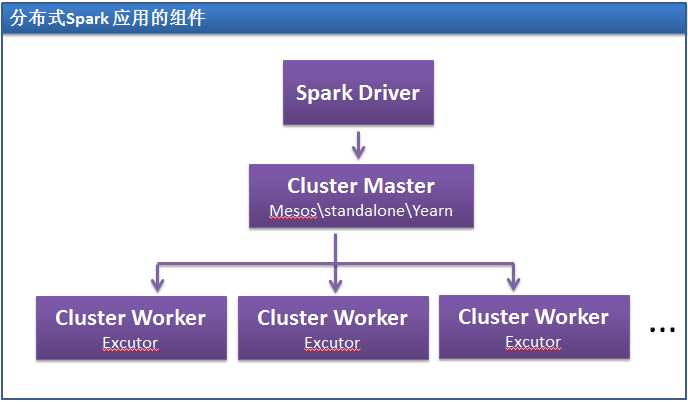
Spark 应用运行在一组使用被称为集群管理器的外部服务的机器上。注意,Spark
打包了一个内置的集群管理器,叫做Standalong 集群管理器。Spark 也可以工作
于Hadoop YARN 和Apache Mesos 这两个开源的集群管理器。
Driver 是你的程序的main() 方法所在的进程。该进程运行用户代码创建
SparkContext,创建RDD,执行变换和动作。当运行一个Spark Shell,你就创
建了一个driver 程序 。一旦driver 终止,整个应用就结束了。
当driver 运行时,它有两个职责:
Spark 的driver 有责任转换用户程序到被称为任务的物理执行单元。从上层看,
所有的Spark 程序都遵循同样的结构:它们从输入创建RDD,通便变换从这些RDD
得到新的RDD,然后执行动作来采集数据或保存数据。Spark
程序隐含创建了操作的逻辑合理的有向无环图(DAG)。当driver 运行时,它
转换该图到物理执行计划。
Spark 执行多种优化,比如“流水线”映射转换合并,并转换执行图到一组
stage。每个stage 又由一组task 组成。Task 则被捆绑在一起准备被发送到集
群。Task 是Spark 处理中的最小单元。典型的用户程序要执行成百上千个单
独的任务。
有了物理执行计划,driver 必须协调各独立任务到executor 中。当excutor 启
动后,它们会将自己注册到driver,所以driver 随时都能看到完整的executor
视图。每个executor 表现为能执行任务和保存RDD 数据的进程。
Spark Driver 会寻找当前的executor 组,然后基于数据分布尝试调度每个task
到合适的位置。当任务执行时,可能会对正缓存的数据有副作用。Driver 也
要记录缓存数据的位置并用来调度将来访问这些数据的任务。
Driver 从web 接口暴露出了这些Spark 应用的运行信息,默认端口是4040。
例如,在本地模式,可用的UI 是http://localhost:4040。
Spark Executor 是worker 进程,其职责是运行给定的Spark 作业中的单个任务。
Executor 在Spark 应用开始的时候被启动一次,一般会在应用的整个生命周期都
运行。虽然executor 出错了Spark 也可以继续。Executor 有两个任务。一个是运
行构成应用的任务并返回结果到driver。第二个是通过每个executor 中都存在的
被称为块管理器(Block Manager)的服务为用户程序中缓存的RDD 提供内存存
储。因为RDD 被直接缓存在execturo 中,任务可以和数据在一起运行。
1. 用户用spark-submit 提交了一个应用。
2. spark-submit 启动driver 程序,并调用用户指定的main()方法。
3. driver 程序联系集群管理器请求资源来启动各executor。
4. 集群管理器代表driver 程序启动各executor。
5. Driver 进程运行整个用户应用。程序中基于RDD 的变换和动作,driver 程序
以task 的形式发送到各executor。
6. Task 在executor 进程运行来计算和保存结果。
7. 如果driver 的main()方法退出或者调用了SparkContext.stop(),就会终止
executor 的运行并释放从集群管理器分配的资源。
标签:位置 作用 localhost yarn amp 技术分享 分配 cut oca
原文地址:http://www.cnblogs.com/jeffry/p/6232453.html