标签:alt gre ted rgs size 演示 element contain ++
作用:查找指定目录(一个或多个)及子目录下的所有重复文件,分组列出,并可手动选择或自动随机删除多余重复文件,每组重复文件仅保留一份。(支持文件名有空格,例如:"file name" 等)
实现:find遍历指定目录查找所有文件,并对找到的所有文件进行MD5校验,通过比对MD5值分类处理重复文件。
不足: find 遍历文件耗时;
MD5校验大文件耗时;
对所有文件校验比对耗时(可考虑通过比对文件大小进行第一轮的重复性筛选,此方式针对存放大量大文件的目录效果明显,本脚本未采用);
演示:
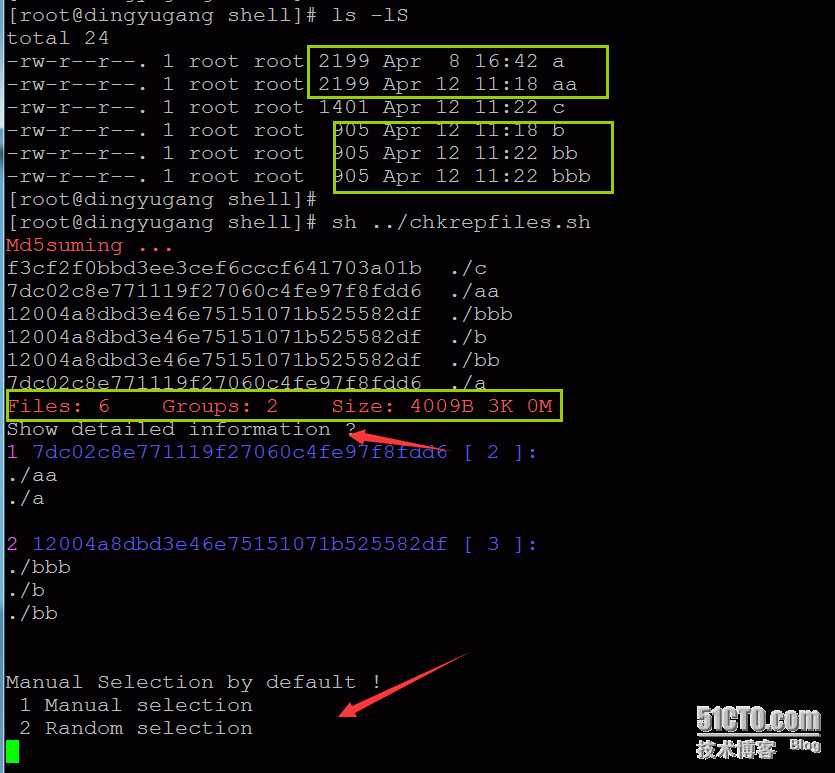
注释:
脚本执行过程中显示MD5校验过程,完毕后,统计信息如下:
Files: 校验的文件总数
Groups: 重复文件组的数量
Size:此处统计的大小为,多余文件的总大小,即将要删除的多余的重复文件的大小,换句话说就是,删除重复文件后,磁盘空间会节省的空间。
可在“Show detailed information ?”提示后,按键“y”,进行重复文件组的查看,以便确认,也可直接跳过,进入删除文件方式的选择菜单:
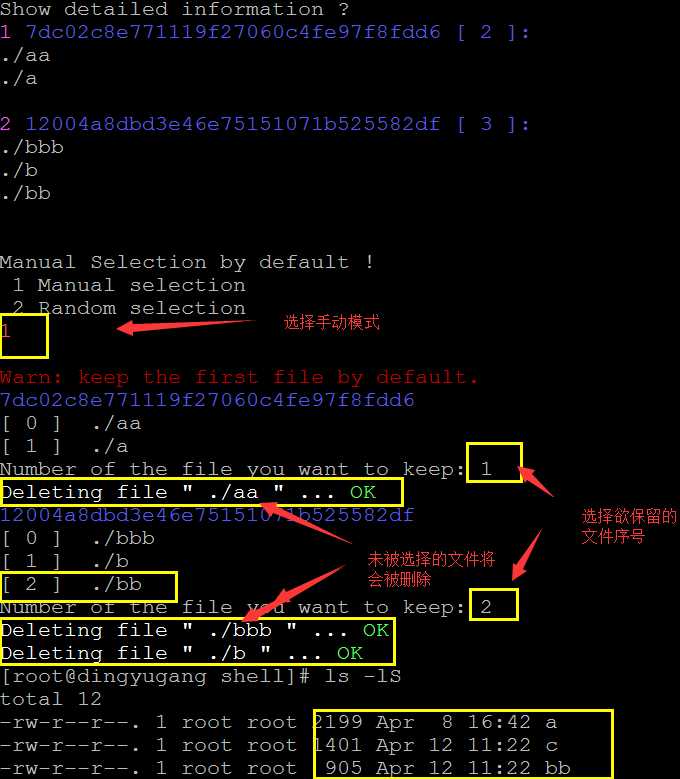
删除文件方式有两种,一种是手动选择方式(默认的方式),每次列出一组重复文件,手动选择欲留下的文件,其他文件将会被删除,若没有选择 则默认保留列表的第一个文件,演示如下:
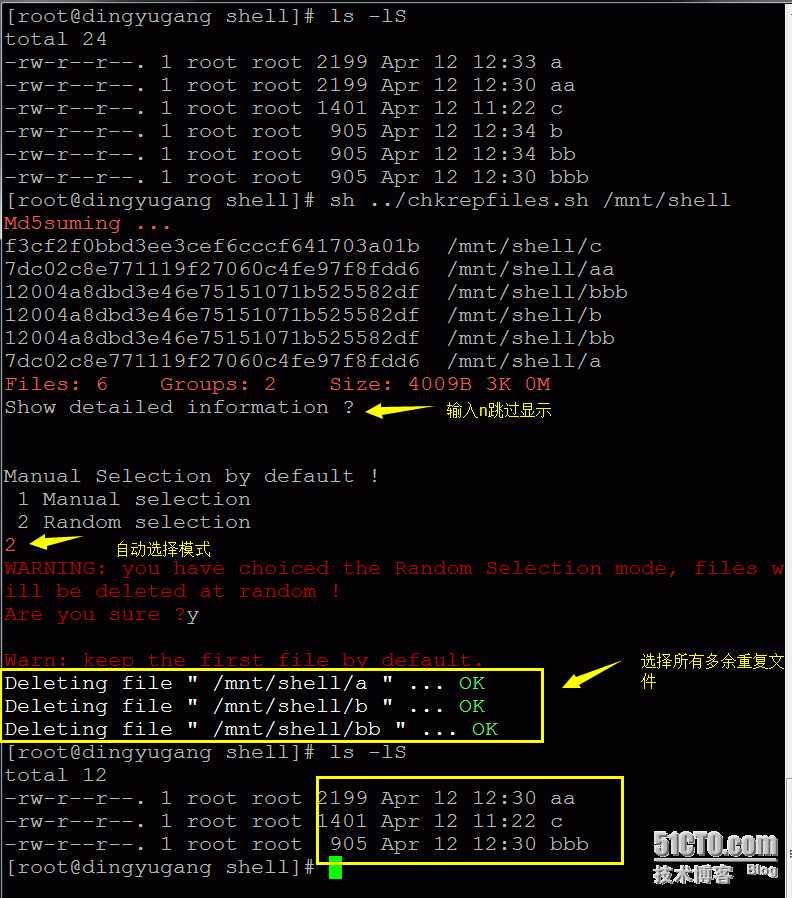
另一种方式是自动选择方式,默认保留每组文件的第一个文件,其他重复文件自动删除。(为防止删除重要文件,建议使用第一种方式),演示如下:
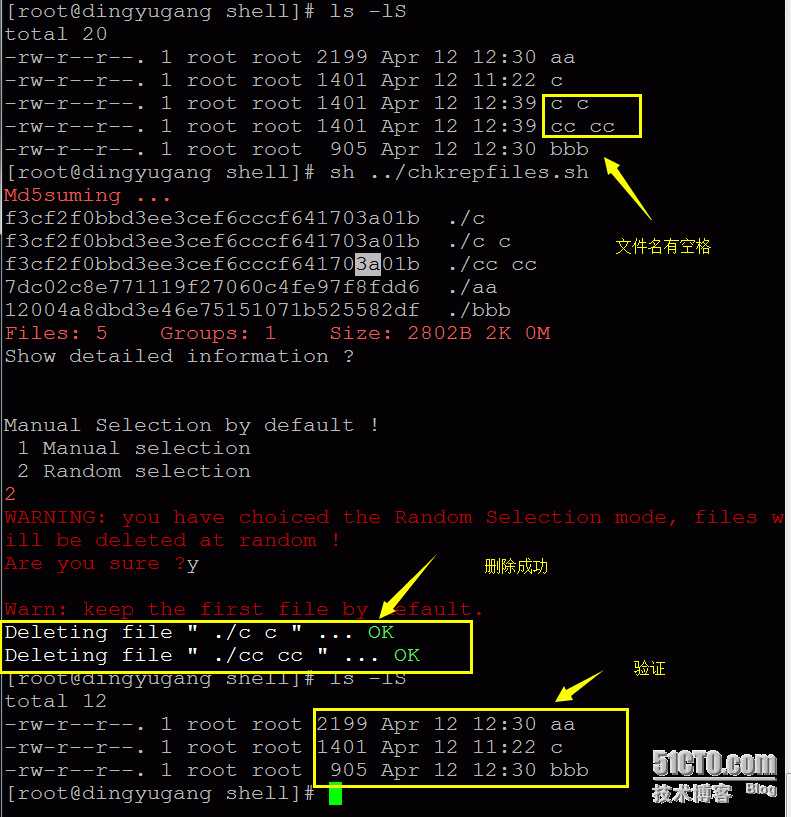
支持文件名空格的情况,演示如下:
代码专区:
#!/bin/bash #Author: LingYi #Date: 2016.4.12 #Func: Delete duplicate files #EG : $0 [ DIR1 DIR2 ... DIRn ] #Define the mnt file, confirming the write authority by yourself. md5sum_result_log="/tmp/$(date +%Y%m%d%H%M%S)" echo -e "\033[1;31mMd5suming ...\033[0m" find $@ -type f -print0 | xargs -0 -I {} md5sum {} | tee -a $md5sum_result_log files_sum=$(cat $md5sum_result_log | wc -l) # Define array, using the value of md5 as index, filename as element. # Firstly, you must do advance declaration to make sure the it‘s supported by bash. declare -A md5sum_value_arry while read md5sum_value md5sum_filename do #Space in a file name, in order to support this case ,using the ‘+’ as the segmentation charater. #So, if ‘+‘ appears in a file name, there will be problems. The use should choose the manual mode to delete redundant files. md5sum_value_arry[$md5sum_value]="${md5sum_value_arry[$md5sum_value]}+$md5sum_filename" (( _${md5sum_value}+=1 )) done <$md5sum_result_log # counting the duplicate file groups and the size of redundant files in this loop. groups_sum=0 repfiles_size=0 for md5sum_value_index in ${!md5sum_value_arry[@]} do if eval [[ \${_${md5sum_value_index}} -gt 1 ]]; then let groups_sum++ need_print_indexes="$need_print_indexes $md5sum_value_index" eval repfile_sum=\$\(\( \$_$md5sum_value_index - 1 \)\) repfile_size=$( ls -lS "`echo ${md5sum_value_arry[$md5sum_value_index]}|awk -F‘+‘ ‘{print $2}‘`" | awk ‘{print $5}‘) repfiles_size=$(( repfiles_size + repfile_sum*repfile_size )) fi done #Outputing the statistical information. echo -e "\033[1;31mFiles: $files_sum Groups: $groups_sum \ Size: ${repfiles_size}B $((repfiles_size/1024))K $((repfiles_size/1024/1024))M\033[0m" [[ $groups_sum -eq 0 ]] && exit #The use chooses whether to check the file grouping or not. read -n 1 -s -t 300 -p ‘Show detailed information ?‘ user_ch [[ $user_ch == ‘n‘ ]] && echo || { [[ $user_ch == ‘q‘ ]] && exit for print_value_index in $need_print_indexes do echo -ne "\n\033[1;35m$((++i)) \033[0m" eval echo -ne "\\\033[1\;34m$print_value_index [ \$_${print_value_index} ]:\\\033[0m" echo ${md5sum_value_arry[$print_value_index]} | tr ‘+‘ ‘\n‘ done | more } #The user can choose the way of deleting file here. echo -e "\n\nManual Selection by default !" echo -e " 1 Manual selection\n 2 Random selection" echo -ne "\033[1;31m" read -t 300 USER_CH echo -ne "\033[0m" [[ $USER_CH == ‘q‘ ]] && exit [[ $USER_CH -ne 2 ]] && USER_CH=1 || { echo -ne "\033[31mWARNING: you have choiced the Random Selection mode, files will be deleted at random !\nAre you sure ?\033[0m" read -t 300 yn [[ $yn == ‘q‘ ]] && exit [[ $yn != ‘y‘ ]] && USER_CH=1 } #Handle files according to the user‘s selection echo -e "\033[31m\nWarn: keep the first file by default.\033[0m" for exec_value_index in $need_print_indexes do #This loop contains an array of files that are about to be deleted. for((i=0,j=2;i<$(echo ${md5sum_value_arry[$exec_value_index]} | grep -o ‘+‘ | wc -l); i++,j++)) do file_choices_arry[i]="$(echo ${md5sum_value_arry[$exec_value_index]}|awk -F‘+‘ ‘{print $J}‘ J=$j)" done eval file_sum=\$_$exec_value_index if [[ $USER_CH -eq 1 ]]; then #If the user selects a manual mode, handle the duplicate file group one by one in a loop. echo -e "\033[1;34m$exec_value_index\033[0m" for((j=0; j<${#file_choices_arry[@]}; j++)) do echo "[ $j ] ${file_choices_arry[j]}" done read -p "Number of the file you want to keep: " num_ch [[ $num_ch == ‘q‘ ]] && exit seq 0 $((${#file_choices_arry[@]}-1)) | grep -w $num_ch &>/dev/null || num_ch=0 else num_ch=0 fi #If the user selects the automatic deletion mode, then delete the redundant files for((n=0; n<${#file_choices_arry[@]}; n++)) do [[ $n -ne $num_ch ]] && { echo -ne "\033[1mDeleting file \" ${file_choices_arry[n]} \" ... \033[0m" rm -f "${file_choices_arry[n]}" [[ $? -eq 0 ]] && echo -e "\033[1;32mOK" || echo -e "\033[1;31mFAIL" echo -ne "\033[0m" } done done
Find and delete duplicate files
标签:alt gre ted rgs size 演示 element contain ++
原文地址:http://www.cnblogs.com/lydygly/p/6233447.html