http://mp.weixin.qq.com/s?__biz=MjM5ODYwMjI2MA==&mid=2649736156&idx=1&sn=23931f48282f6ef38f3d3e1875631dbf&scene=2&srcid=0627YxiA6JDyQNbECRBTfjjc&from=timeline&isappinstalled=0#wechat_redirect

jasonysli李跃森本文作者数据平台部存储引擎组PGXZ项目负责人,2013年从华为加入腾讯,从事数据库和存储相关的工作。多年来一直致力于数据库引擎的研究和开发,从事过多款数据库内核的设计和开发工作,包括内存数据库,分析型数据库,事物型数据库,当前负责PGXZ项目的开发。

小编

分布式关系数据集群是一项基础类的IT技术,广泛应用于事务处理领域。对微信支付后台大量数据的处理提供强有力的支持,保证数据处理的准确性及使用的顺畅。PGXZ是典型的MPP(大规模并行处理),Share Nothing的分布式数据库架构,在此种架构中各个处理单元都有自己私有的CPU/内存/硬盘等,不存在共享资源,各处理单元之间通过协议通信,并行处理和扩展能力更好。典型代表GreenPlum, DB2 DPF和Hadoop ,各节点相互独立,各自处理自己的数据,处理后的结果可能向上层汇总或在节点间流转。
我们常说的 Sharding 其实就是Share Nothing架构,它是把某个表从物理存储上被水平分割,并分配给多台服务器(或多个实例),每台服务器可以独立工作,具备共同的schema,比如阿里的TDDL和我厂的TDSQL,只需增加服务器数就可以增加处理能力和容量。
本质上来讲,PGXZ内部是垂直按照分布列进行节点级的水平分隔,是某种Sharding的实现,但PGXZ把这些分布逻辑和细节屏蔽到了数据库的内部,对外提供和单机数据库一样的接口,在保证了易用的同时还提供了强大的数据库能力。PGXZ的CN和DN的每个节点都是一个PostgreSQL的实例,从实现上来讲,PGXZ就是在PG的代码上加了集群的相关功能,从而做成了一个MPP的数据库集群。本文主要解析PGXZ为了实现MPP架构对PG做的修改。 PGXZ的架构简图如下:
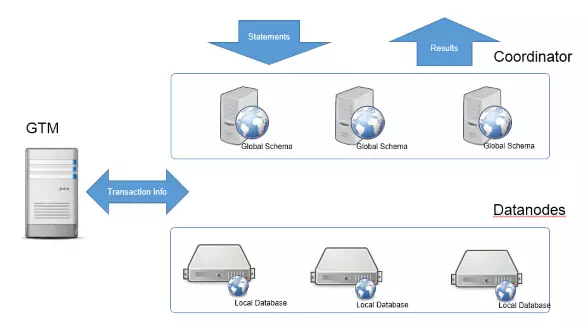
Coord:协调节点,对外提供接口,负责数据的分发和查询规划,多个节点位置对等;CN上只存储系统的元数据,并不存储实际的业务数据。
Datanode:存储实际数据,并执行协调节点分发的执行请求,实际存储数据的节点;DN上存储业务数据;各个DN可以存储在不同的物理机上,相互之间隔离,这也就是所谓的Share Nothing。
GTM:全局事务管理器,负责全局事务管理;GTM上不存储数据 PGXC执行SQL的过程:
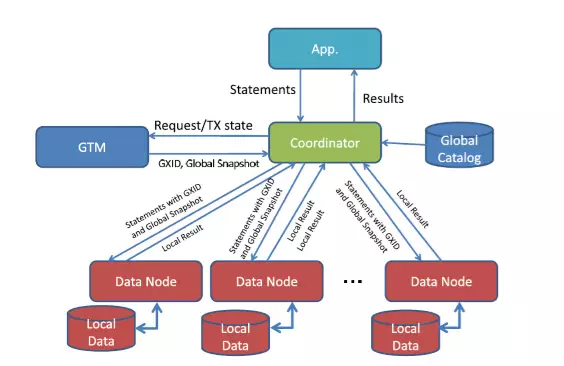
Step1:业务发送请求到Coord节点,Coord节点向GTM请求 事务信息。Step2:Coord发送SQL语句和事务信息到Datanode。Step3:Datanode执行完SQL后返回结果给CN。Step4:CN收集DN的结果并汇总会后返回给业务。
PGXZ的元数据管理首先介绍下集群的节点管理,节点管理涉及到两张表:PGXC_NODE,管理集群的DN和CN,保存集群所有的DN和CN信息。字段信息如下:
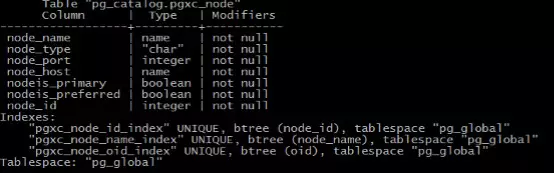
包含CN访问节点时必须的信息,主要是节点名称,节点是CN还是DN,端口,IP等等。PGXZ提供了ADD NODE,ALTER NODE,ROMOVE NODE等命令来对系统的节点进行添加,修改,删除,这些命令的底层就是操作的PGXC_NODE表。
PGXC_GROUP,PGXZ提供了一个节点组的概念,通过组可以把大规模的集群成几个小规模的集群,在建表时指定对应的存储组,进而达到业务上物理隔离的目的。表结构如下:
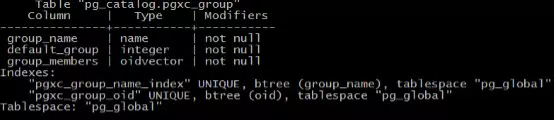
主要有组名称,组中成员节点OID等字段。CREATE NODE GROUP,DROP NODE GROUP等命令主要对PGXC_GROUP表进行操作。
为了管理集群中表的信息,PGXZ在PG原有的元数据的基础增加PGXC_CLASS对集群中的表进行管理:
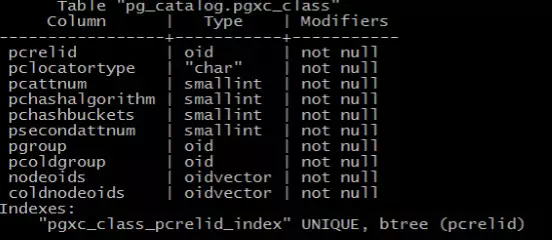
pcrelid是集群表对应在CN或者DN上pg_class记录的Oid,这个列建了唯一性索引,保证记录的不可重复。
pclocatortype描述集群表的分布方式:
‘H‘:哈希分布,使用分布列的hash值对分布节点数取模决定数据存储到哪个节点。该中分布释放无法做到线性扩容和缩容。
‘R‘:复制表,这个表中的数据在所有分布节点上是完全相同的,也就是每个写入操作都会复制到分布节点。该种表一般用在数据量很小的表上。
‘N‘: 随机分布,表中的记录随机分布到所有的存储节点。
‘S‘:Sharding分布,表中的数据使用分布列的哈希值在一个逻辑的分布表上进行取模获得写入的节点。这种分布模式的表可以做到很好的扩容和缩容特性。
pcattnum是集群表的第一分布列,从1开始。
Psecondattum是集群的第二分布列,在双KEY分布时用来计算数据的存储位置,当前该列类型只能是timestamp。
这个表在DN和CN上都有存储,在每次建表操作时CN协调集群内部的所有节点完成建表操作,在每个节点上创建对应的PGXC_CLASS记录,完成建表操作。
CN在生成执行计划时根据PGXC_CLASS来决定请求发送往哪些节点。
PGXZ集群内部的连接管理PGXZ在CN中新加了Pooler进程来管理CN到其他CN和DN的连接,这个进程起到连接池的作用。
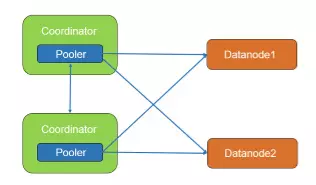
通过Pooler进程,CN可以高效的获取到其他节点的连接,保证事务的执行效率。
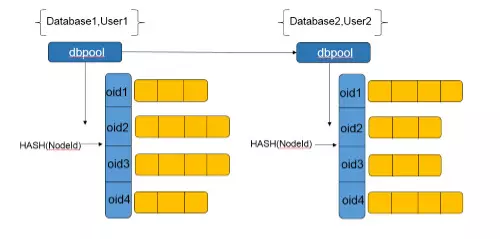
Pooler进程中有多个dbpool,每个dbpool对应一组数据库和用户名的组合,不同的用户名和数据库的组合对应不同的dbpool。
dbpool在该用户首次登录这个数据库的时候创建,使用hash表来管理该用户往各个节点的对应数据库的连接池。每个节点的连接池存放在以nodeid为键的hash表中。这个连接池具有普通数据库连接池所需的特性,包括最大连接数,最小连接数,连接生命周期等等。
PGXZ中的分布式事务PGXZ通过2PC事务来保证事务执行的原子性,这里拿CREATE TABLE为例子进行解析:
第一步,CN向所有节点发起BEGIN TRANSACTION,保证整个操作的原子性,这个操作由CN内部发起,业务无感知。
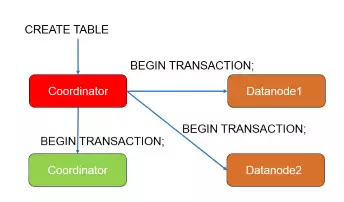
第二步,CN向所有节点发起CREATE TABLE命令,每个节点完成建表操作。
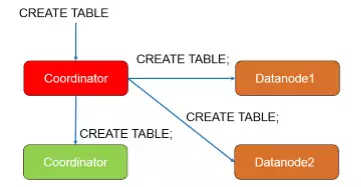
第三步,CN向每个节点开启两阶段事务,这个阶段包括发起请求的节点自己。阶段结束后,所有节点完成PREPARE。
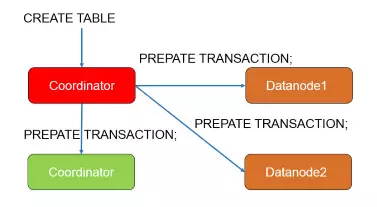
第四步, CN向所有节点发起两阶段事务提交请求,至此,建表操作结束。
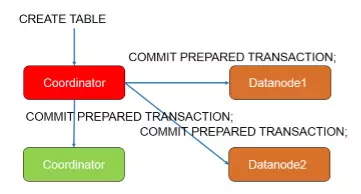
说到两阶段事务,对应的故障和处理方法是一定要讨论的。在第一和第二个阶段发生故障时,事务此时还是普通事务,直接回滚所有节点的事务即可,不会有其他的副作用。但是在第三阶段以后情况有所不同,在事务被PREPARED以后,事务中的信息在两阶段事务中进行了持久化,这个事务必须通过COMMIT PREPARED或者ROLLBACK PREPARED来完成。
在一些极端的场景下,比如节点硬件故障,磁盘空间不足,COMMIT PREPARED或者ROLLBACK PREPARED阶段会被异常结束,这些系统的事务状态当前是未决的。因为两阶段事务的持久化信息中很有可能会包含锁的信息,如果这些事务得不到很及时的处理就会对后续的业务处理造成较大的影响。我们提供了一个2PC事务的自动处理工具,在系统监测到残留的2PC事务时,运行工具来处理系统的两阶段事务,保证业务的正常运行。
工具会扫描系统的2PC事务状态并做出处理,处理的方式如下表:

通过上面的方法,在系统发生故障时,可以有效的降低2PC事务带来的影响。
总结:除了元数据管理,集群连接管理,2PC事务意外,PGXZ在查询优化器的层面也做了很多优化来解决分布式后的查询优化。这里篇幅所有限不做详细的解析。
思考:数据库存储架构的发展主要有Shared Nothing和Share Everything。Share Everything的集群商业软件有SybaseIQ,Oracle RACK等,但是在开源软件软件领域目前还没有相应的解决方案。当前具备POSIX接口的分布式文件系统已经在很多的生产环境投入使用,我们是不是也可以畅想下基于DFS的Share Everything架构的数据库集群?