标签:男人 cte sha auto play event html 关系 htm
前两天写了一个python脚本,试图以分析网页源码的方式得到优酷视频的下载地址,结果只得到视频的纯播放地址,下载纯播放地址得到的文件也无法正常播放视频。
这里共享一下播放地址得到的方法(想看的可以展开折叠):

# 实验视频地址:http://v.youku.com/v_show/id_XMTY3OTYyODM2NA==.html?f=27873045&from=y1.2-3.2
# 解析到播放地址:http://static.youku.com/v1.0.0646/v/swf/loader.swf?VideoIDS=XMTY3OTYyODM2NA==&ShowId=0&category=98&Cp=0&Light=on&THX=off&unCookie=0&frame=0&pvid=1470928536391FWGhzj&uepflag=0&Tid=0&isAutoPlay=true&Version=/v1.0.159&show_ce=0&winType=interior&Type=Folder&Fid=27873045&Pt=1&Ob=1&plchid=&playmode=2&embedid=AjQxOTkwNzA5MQJ2LnlvdWt1LmNvbQIvdl9zaG93L2lkX1hNVFkzT1RjMU5qQTRNQT09Lmh0bWw=&ysuid=1470556998734i3T&vext=bc%3D%26pid%3D1470928536391FWGhzj%26unCookie%3D0%26frame%3D0%26type%3D1%26fob%3D1%26fpo%3D1%26svt%3D0%26cna%3DpcwtEK7f7lUCAXDtLY6srtly%26emb%3DAjQxOTkwNzA5MQJ2LnlvdWt1LmNvbQIvdl9zaG93L2lkX1hNVFkzT1RjMU5qQTRNQT09Lmh0bWw%3D%26dn%3D%E7%BD%91%E9%A1%B5%26hwc%3D1%26mtype%3Doth&cna=pcwtEK7f7lUCAXDtLY6srtly&pageStartTime=0
# 但这不是下载地址,汗
# 解析方法:
# <div class="player" id="player"...<object type="application/x-shockwave-flash"
# data="(.*?)" ... id="movie_player">...
# <param name="flashvars" value="(.*?)">...
# 正则提取出items,(.*?)处为提取对象,存储在items中
# items[0] = ‘http://static.youku.com/v1.0.0646/v/swf/loader.swf‘
# items[1] = ‘VideoIDS=XMTY3OTYyODM2NA==&ShowId=0&category=98&Cp=0&Light=on&THX=off&unCookie=0&frame=0&pvid=1470928536391FWGhzj&uepflag=0&Tid=0&isAutoPlay=true&Version=/v1.0.159&show_ce=0&winType=interior&Type=Folder&Fid=27873045&Pt=1&Ob=1&plchid=&playmode=2&embedid=AjQxOTkwNzA5MQJ2LnlvdWt1LmNvbQIvdl9zaG93L2lkX1hNVFkzT1RjMU5qQTRNQT09Lmh0bWw=&ysuid=1470556998734i3T&vext=bc%3D%26pid%3D1470928536391FWGhzj%26unCookie%3D0%26frame%3D0%26type%3D1%26fob%3D1%26fpo%3D1%26svt%3D0%26cna%3DpcwtEK7f7lUCAXDtLY6srtly%26emb%3DAjQxOTkwNzA5MQJ2LnlvdWt1LmNvbQIvdl9zaG93L2lkX1hNVFkzT1RjMU5qQTRNQT09Lmh0bWw%3D%26dn%3D%E7%BD%91%E9%A1%B5%26hwc%3D1%26mtype%3Doth&cna=pcwtEK7f7lUCAXDtLY6srtly&pageStartTime=0‘
# url = items[0] + ‘?‘ + items[1]
# url就是播放地址
今天在研究盗链时,心想可不可以直接在优酷返回的包里找到视频的下载链接。
琢磨了一秒钟,心里面觉得这个方法应该是可行的,于是打开抓包神器wireshark。
启动的同时,在优酷主页里随便点开一个视频,让它开始播放。wireshark里很快出现很多包,我加上筛选条件“http”,让它只抓取http协议相关的包。
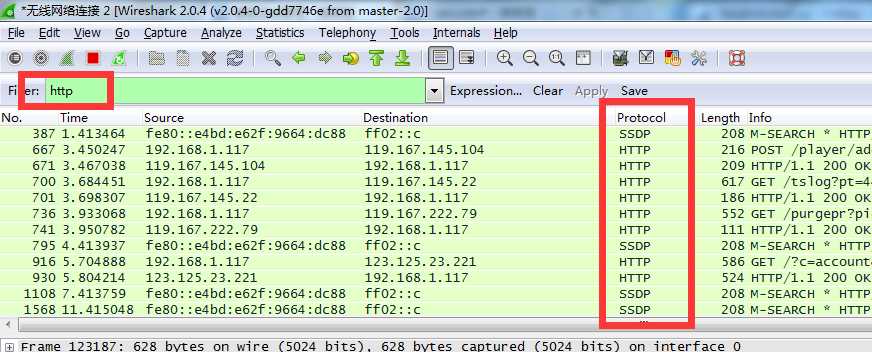
其中重点关注 info 中开头为 GET 方式请求的包,因为这种包最容易分析,音视频图片的下载链接往往就包含在这些包的应用层里面。
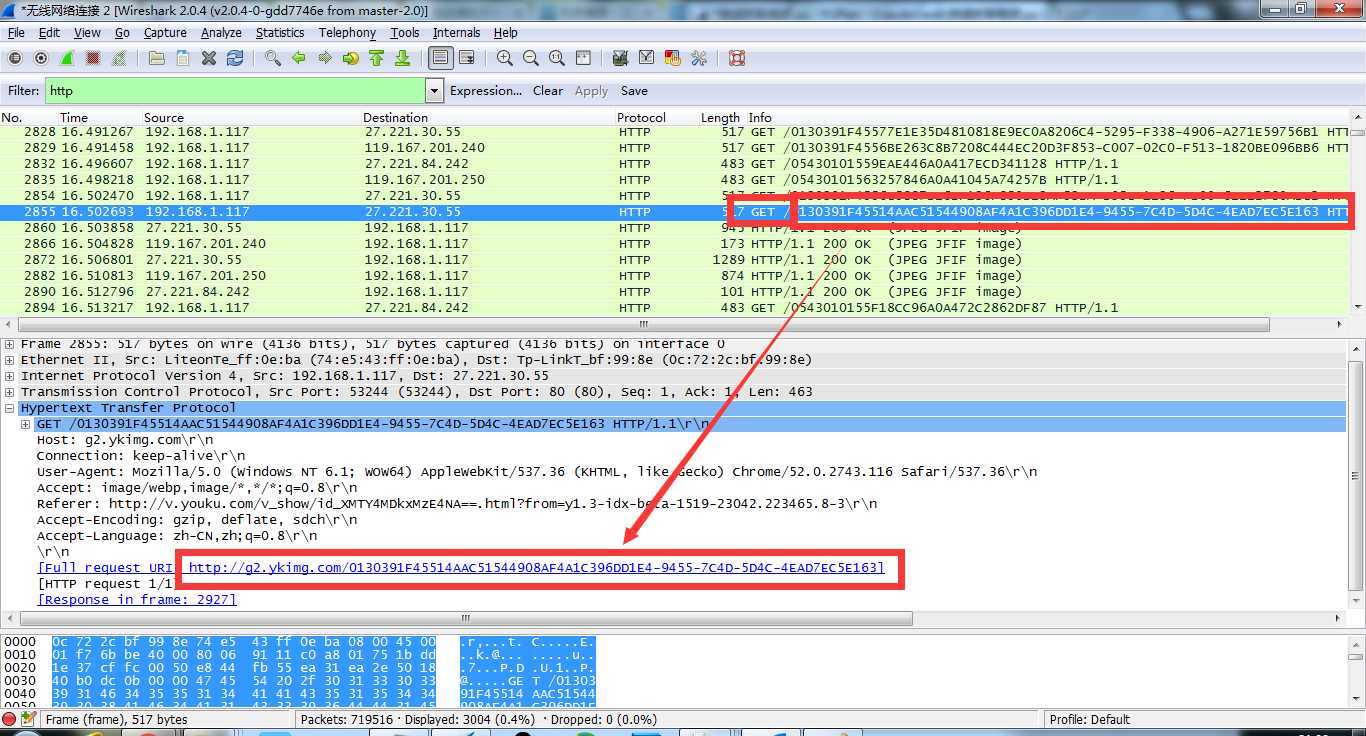
例如上图得到的就是一张logo的图片。
我在这里面找与视频相关的包的链接,大概找到两种:
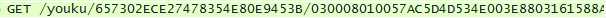
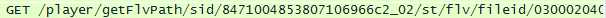
这两种链接打开就可以播放,但也并不是全部都可以。而且我点开了好多链接,能播放的基本都是广告……
然后我对 /youku 开头的进行了重点分析,别问我为什么,男人的直觉 =_=
对链接进行复制之后,尝试用迅雷下载,结果发现文件十分的小,而且下载之后也无法播放。
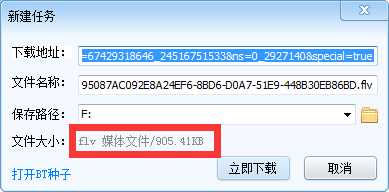
类似的链接还有很多段,它们下载得到的文件名一样,但是大小不同,而且单独下载之后都无法播放。我猜这是TCP协议分块传输的关系。
这个时候我发现链接后面有一些参数,于是我把整个链接粘贴到记事本里,然后把参数部分删掉。
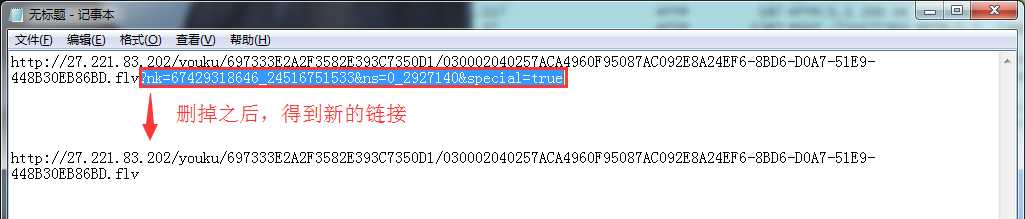
得到新的链接,把它复制到迅雷中,发现可以下载,而且大小和之前比不可同日而语。
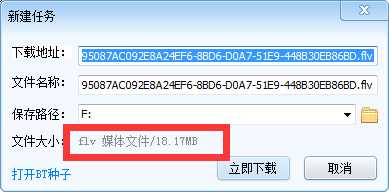
我猜想这个视频应该是可以播放的,果不其然,下载之后打开果然可以顺利播放,而且正是我在网页中播放的视频。
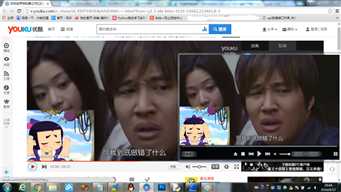
到这里基本可以确定这个方法是可以获得优酷的视频下载链接,但是还有点小问题,用我们得到的链接下载的视频只有6分钟,而原视频有26分钟,可想而知,下载的视频应该是完整视频的一部分。但我想其它部分的链接就在wireshark中,用同样的方法分析包就可以得到其它部分的链接。在这里我就不一一实验了。
这种方法获取优酷视频的下载链接的方法是利用了wireshark软件进行抓包,通过抓取网络中传输的包并进行分析,直接得到请求的视频的地址,然后进行下载。
Freecode# : www.cnblogs.com/yym2013
标签:男人 cte sha auto play event html 关系 htm
原文地址:http://www.cnblogs.com/yym2013/p/5766626.html
