标签:png attach tail orm margin mod pad 控制 mapped
这部分将简要介绍下NUMA架构的成因和具体原理,已经了解的读者可以直接跳到第二节。
在NUMA架构出现前,CPU欢快的朝着频率越来越高的方向发展。受到物理极限的挑战,又转为核数越来越多的方向发展。如果每个core的工作性质都是share-nothing(类似于map-reduce的node节点的作业属性),那么也许就不会有NUMA。由于所有CPU Core都是通过共享一个北桥来读取内存,随着核数如何的发展,北桥在响应时间上的性能瓶颈越来越明显。于是,聪明的硬件设计师们,先到了把内存控制器(原本北桥中读取内存的部分)也做个拆分,平分到了每个die上。于是NUMA就出现了!
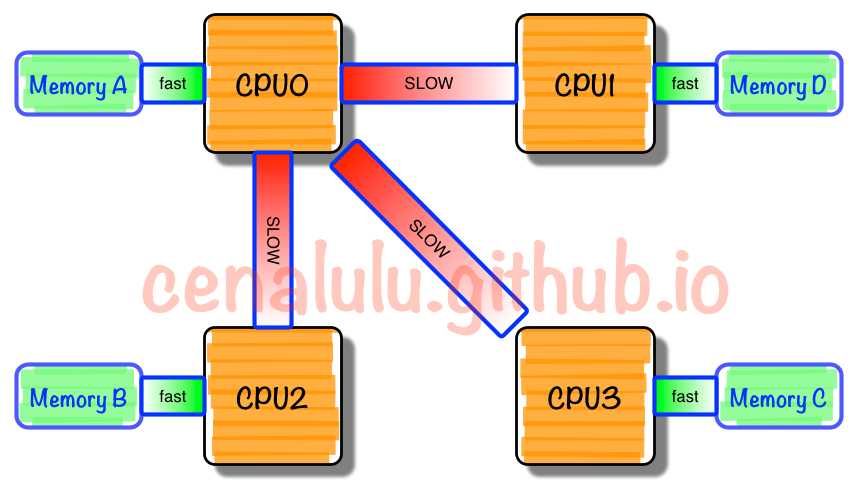
NUMA中,虽然内存直接attach在CPU上,但是由于内存被平均分配在了各个die上。只有当CPU访问自身直接attach内存对应的物理地址时,才会有较短的响应时间(后称Local
Access)。而如果需要访问其他CPU attach的内存的数据时,就需要通过inter-connect通道访问,响应时间就相比之前变慢了(后称Remote
Access)。所以NUMA(Non-Uniform Memory Access)就此得名。
假设你是Linux教父Linus,对于NUMA架构你会做哪些优化?下面这点是显而易见的:
既然CPU只有在Local-Access时响应时间才能有保障,那么我们就尽量把该CPU所要的数据集中在他local的内存中就OK啦~
没错,事实上Linux识别到NUMA架构后,默认的内存分配方案就是:优先尝试在请求线程当前所处的CPU的Local内存上分配空间。如果local内存不足,优先淘汰local内存中无用的Page(Inactive,Unmapped)。
那么,问题来了。。。
大神解释的非常详尽,有兴趣的读者可以直接看原文。博主这里做一个简单的总结:
CPU
0上Reclaim默认策略优先淘汰/Swap本Chip上的内存,使得大量有用内存被换出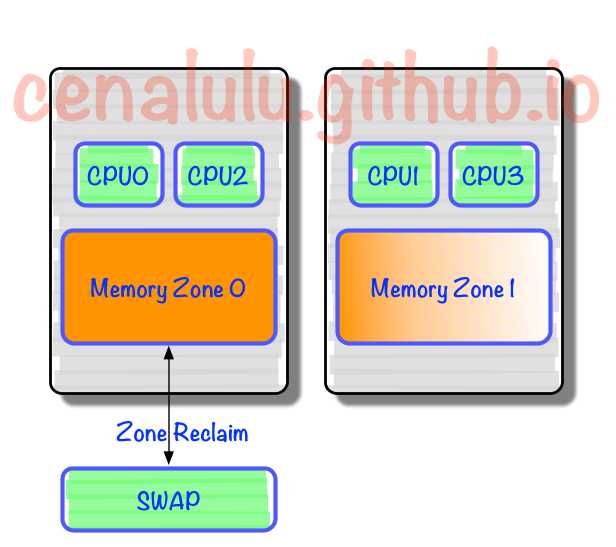
1. NUMA的几个概念(Node,socket,core,thread)
参考链接 http://blog.csdn.net/ustc_dylan/article/details/45667227
对于socket,core和thread会有不少文章介绍,这里简单说一下,具体参见下图:
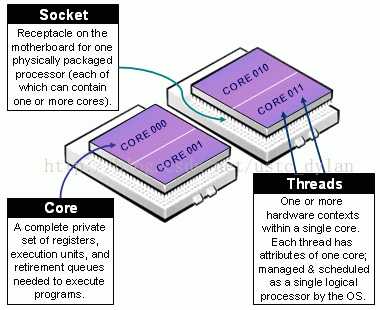
一句话总结:socket就是主板上的CPU插槽; Core就是socket里独立的一组程序执行的硬件单元,比如寄存器,计算单元等; Thread:就是超线程hyperthread的概念,逻辑的执行单元,独立的执行上下文,但是共享core内的寄存器和计算单元。
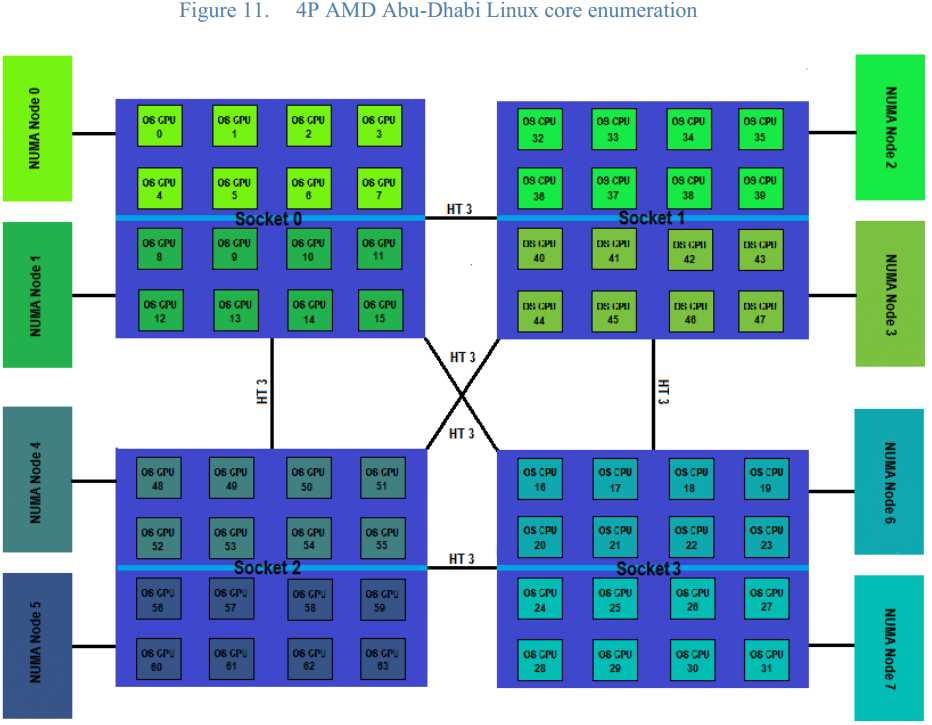
NUMA体系结构中多了Node的概念,这个概念其实是用来解决core的分组的问题,具体参见下图来理解(图中的OS CPU可以理解thread,那么core就没有在图中画出),从图中可以看出每个Socket里有两个node,共有4个socket,每个socket 2个node,每个node中有8个thread,总共4(Socket)× 2(Node)× 8 (4core × 2 Thread) = 64个thread。
另外每个node有自己的内部CPU,总线和内存,同时还可以访问其他node内的内存,NUMA的最大的优势就是可以方便的增加CPU的数量,因为Node内有自己内部总线,所以增加CPU数量可以通过增加Node的数目来实现,如果单纯的增加CPU的数量,会对总线造成很大的压力,所以UMA结构不可能支持很多的核。
dylan@hp3000:~$ lscpuArchitecture: x86_64CPU op-mode(s): 32-bit, 64-bitByte Order: Little EndianCPU(s): 48 //共有48个逻辑CPU(threads)On-line CPU(s) list: 0-47Thread(s) per core: 2 //每个core有2个threadsCore(s) per socket: 6 //每个socket有6个coresSocket(s): 4 //共有4个socketsNUMA node(s): 4 //共有4个NUMA nodesVendor ID: GenuineIntelCPU family: 6Model: 45Stepping: 7CPU MHz: 1200.000BogoMIPS: 4790.83Virtualization: VT-xL1d cache: 32K //L1 data cache 32kL1i cache: 32K //L1 instruction cache 32k (牛x机器表现,冯诺依曼+哈弗体系结构)L2 cache: 256KL3 cache: 15360KNUMA node0 CPU(s): 0-5,24-29NUMA node1 CPU(s): 6-11,30-35NUMA node2 CPU(s): 12-17,36-41NUMA node3 CPU(s): 18-23,42-47
标签:png attach tail orm margin mod pad 控制 mapped
原文地址:http://www.cnblogs.com/yml435/p/6244048.html