标签:几何 统计 基于 特征 固定 分享 迭代 http 支持向量机
感知机是二类分类的线性分类模型,其输入为实例的特征向量,感知机对应于输入空间(特征空间)中将实例划分为正负两类的分离超平面,属于判别模型。导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。感知机学习算法分为原始形式和对偶形式,是神经网络和支持向量机的基础。
感知机定义:
假设输入空间(特征空间)是X,输出空间是Y,Y的取值为+1和-1,输入x表示实例的特征向量,对应于输入空间(特征空间)的;输入y表示实例的类别。由输入空间到输出空间的如下函数:
f(x) = sign(w · x + b)
称为感知机,w、b为模型参数,w为权值或权值向量,b为偏置,w·x表示为二者内积。几何上来说,w·x+b=0对应于特征空间的一个超平面,w是超平面的法向量,b是超平面的截距。也就是找到一个超平面将数据的正负实例分开。

为了找出这样的超平面,及确定感知机的模型参数,需要确定一个学习策略,即定义损失函数并将损失函数最小化。、
损失函数选择误分类点到超平面S的总距离,所以首先写出输入空间中任一点x0到超平面的S的距离:
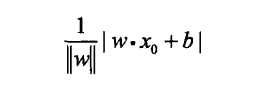
||w||是w的L2范数
其次,对于误分类数据(xi,yi)来说, -yi(w·xi + b) > 0 成立,因此,误分类点xi到超平面S的距离就可以写成:
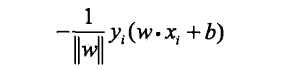
这样,假设超平面S 的误分类点集合为M. 那么所有误分类点到超平面S 的总距离为:
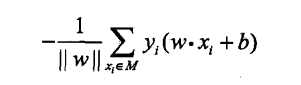
不考虑![]() ,就得到感知机的损失函数:
,就得到感知机的损失函数:
![]()
其中M为误分类点的集合,这个损失函数就是感知机学习的经验风险函数。误分类点越少,误分类点离超平面越近,损失函数值就越小。
获得了损失函数,下一步就是极小化这个损失函数,即:
![]()
具体的方法采用梯度下降算法,极小化过程不是一次使M中所有的误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降,假设误分类点集合M是固定的,那么损失函数L(w,b)的梯度由:
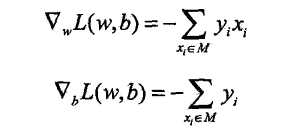
随机选取一个误分类点(xi,yi),对w,b进行更新:
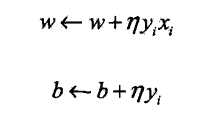
η是学习率通过迭代可以期待损失函数L(w,b)不断减小,直到为0,综上可得如下算法:

感知机学习算法由于采用不同的初值或选取不同的误分类点,解可以不同。



当训练数据集线性可分时,感知机学习算法是收敛的,感知机算法在训练数据集上的误分类次数k满足不等式:
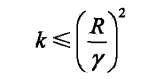
标签:几何 统计 基于 特征 固定 分享 迭代 http 支持向量机
原文地址:http://www.cnblogs.com/pang-zp/p/6259928.html