标签:托管 pre 线程 http 方法 string 代码 echart 技术
第一个大错误是没能及时释放非托管资源,导致程序运行长的之后抛出OutOfMemoryException.
这个小Demo主要的非托管资源一个是http请求的httpWebresopne和流,另外一个是RedisCline。导致这个问题出现不是我不知道要释放非托管资源,而是代码疏忽。这个写代码习惯应该是很久了,因为以前程序并没有运行很久在,这个问题并没有暴露出来
刚开始时候是这样写的
using (StreamReader reader = new StreamReader(stream, Encoding.UTF8)) { return reader.ReadToEnd(); }
之间在using语句里面执行,这样还没有释放对象就返回了
改进:
string Source = string.Empty; … using (Stream stream = response.GetResponseStream())//原始 { using (StreamReader reader = new StreamReader(stream, Encoding.UTF8)) { Source = reader.ReadToEnd(); } } … return Source;
对待非托管资源,两个推荐方法
第二大错误,将异步等同与多线程
异步不等于多线程
对于I/O密集型应该使用异步,对于CPU密集型用多线程。爬虫中获取网络资源是I/O密集型,而html解析是cpu密集型的。由于爬虫中非要获取资源才能解析,我并没有采用异步
其实他们编译结果是一样的
我踩的第一大坑httpwebrequest默认连个连接,不管开多少线程还是那个速度
需要在app.config里面添加
<system.net>
<connectionManagement>
<add address="*" maxconnection="100000"></add>
</connectionManagement>
</system.net>
缺陷:
sqlserver中很多表是1对多关系,由于数据不够规范导致一对多变成一对一很多数据冗余

数据展示
采用echart,关于echart请看我的博客http://www.cnblogs.com/zuin/p/6122818.html
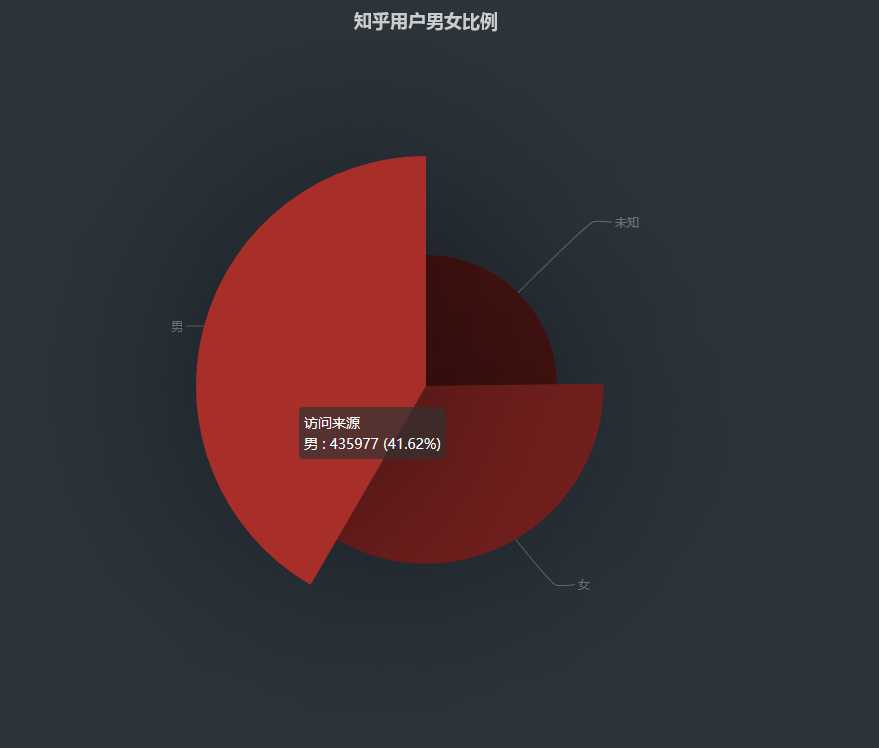
男女比例
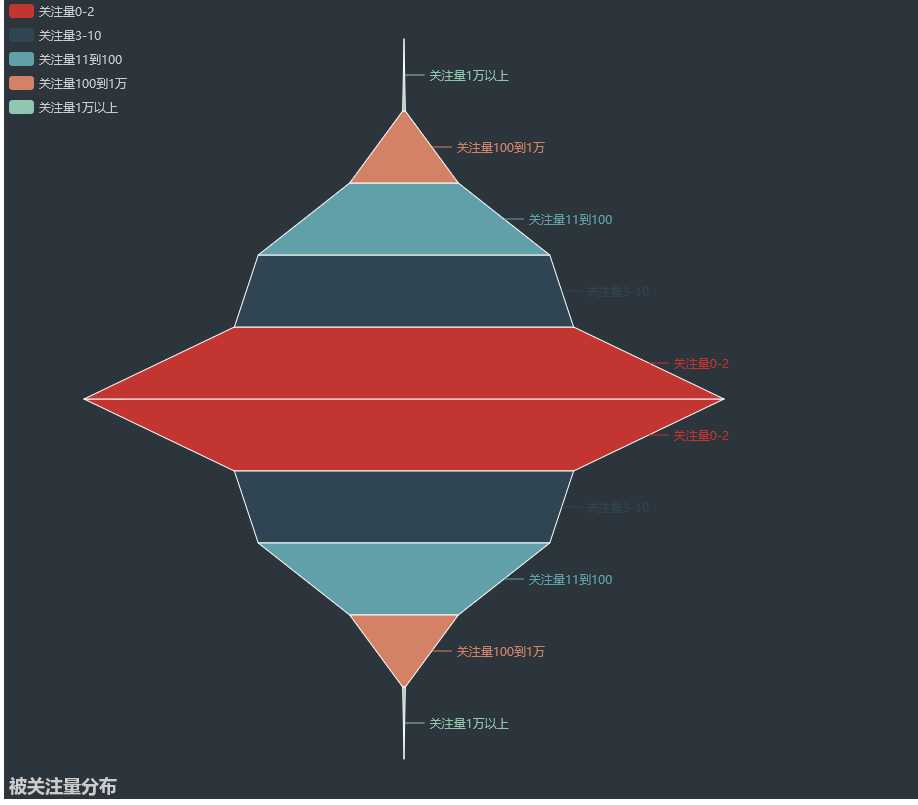
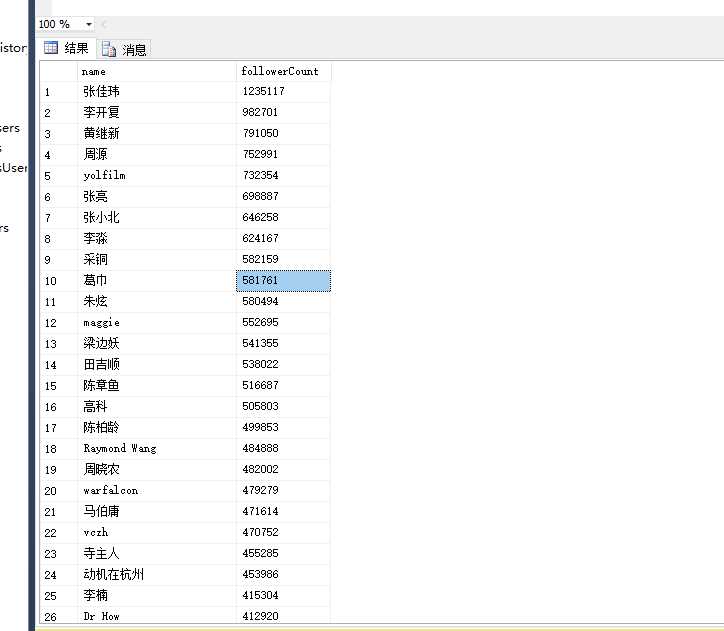
被关注量分布
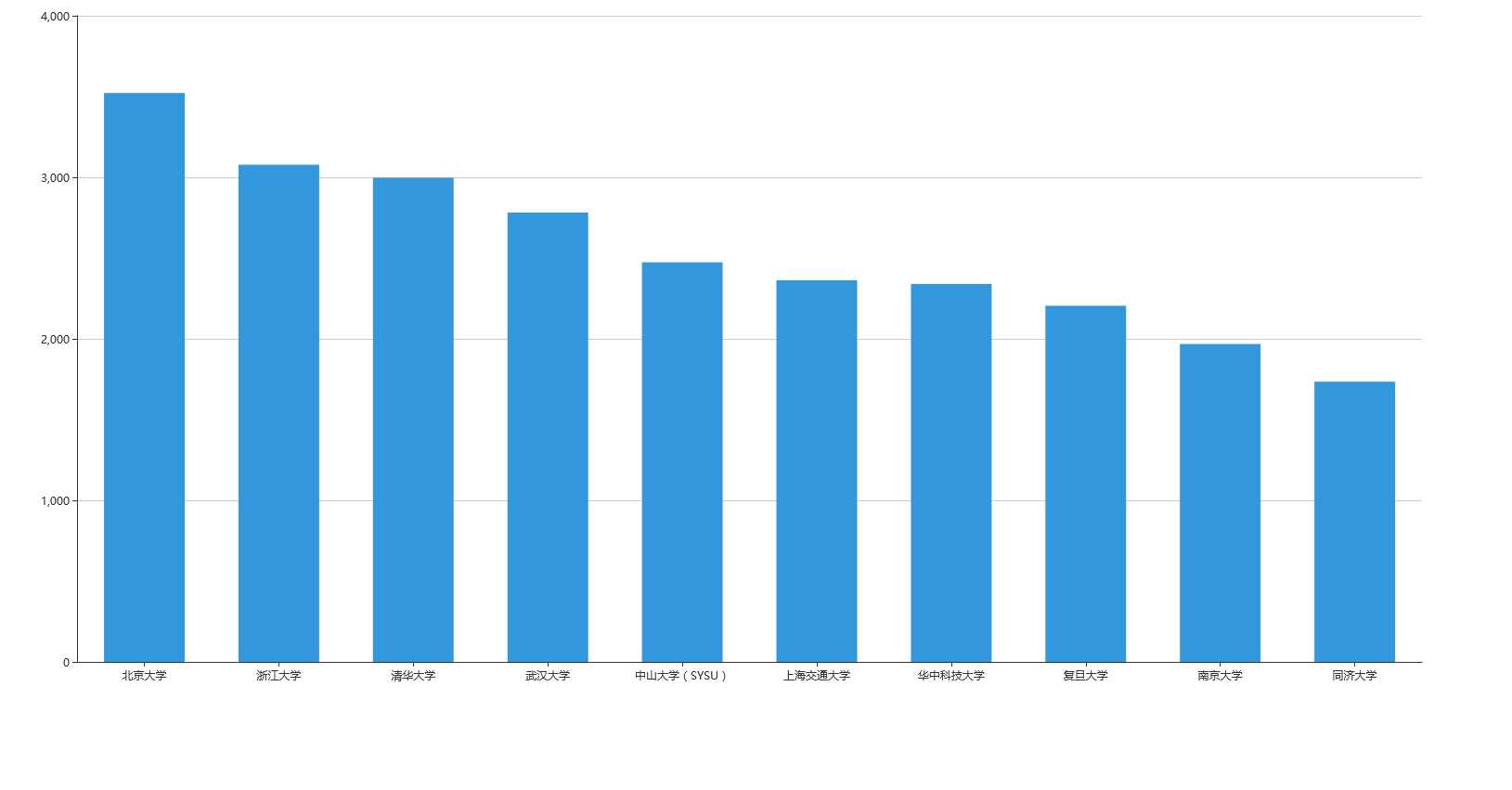
校友数最多的10个学校
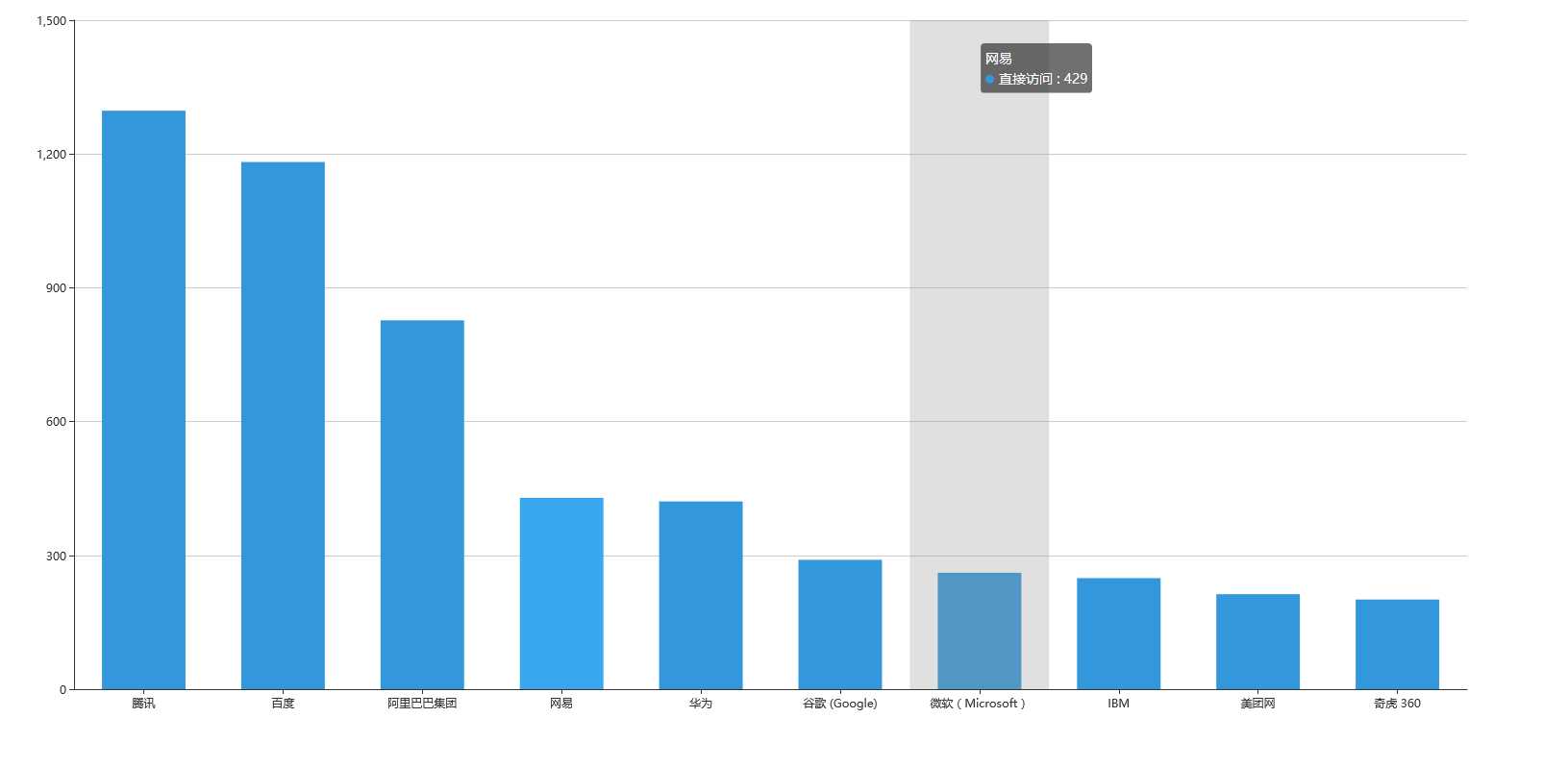
员工最多的10个公司
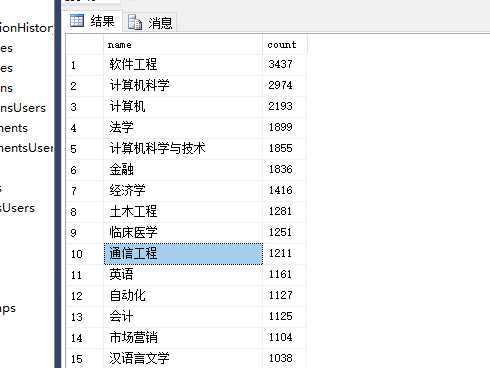
主修专业人数前10
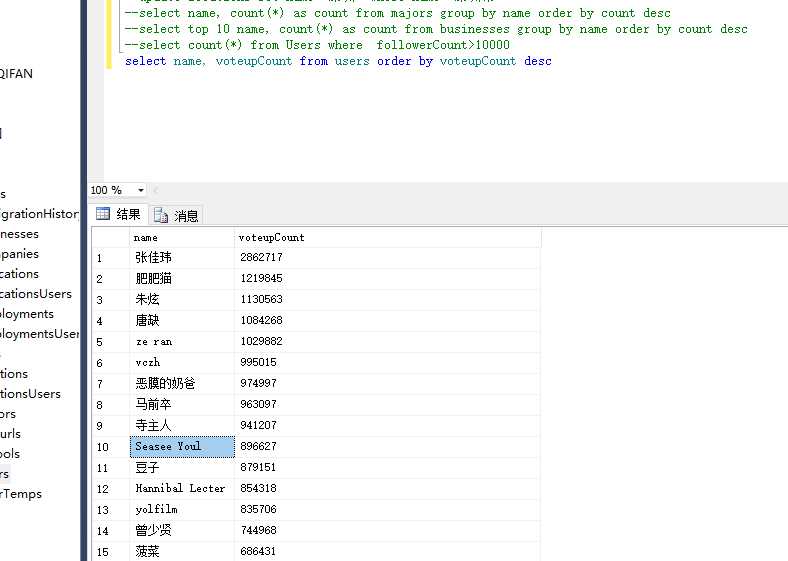
或赞数最多的top10
标签:托管 pre 线程 http 方法 string 代码 echart 技术
原文地址:http://www.cnblogs.com/zuin/p/6261772.html