标签:utc 自动 pip 配置 源码 mode 网页 代码风格 end
twemproxy概述
twemproxy是搭建分布式缓存集群的重要组件之一。他能将来自客户端的redis包通过key分片发送到不同的redis服务器,而不是发到单个redis服务器上。因此,可以使本来集中到一个redis上的信息被分流到几个redis上,这就使得 twemproxy能支持redis集群。不难想到,因为twemproxy的分片功能,可以轻松地对redis集群进行水平扩展(简单地理解成在一个业务中加入更多的redis服务器),同时对于代码稍加改造,我们就可以得到能读写分离的redis集群,这大大提高了redis集群的性能。这使得各大公司如豌豆荚、阿里、百度等都对于这份代码进行了修改,能使其满足分布式缓存集群的要求。当然,twemproxy并不负责数据一致性的工作。
源码下载地址:https://github.com/twitter/twemproxy/
twemproxy架构
为了能更好地了解twemproxy的代码结构,我们就需要了解twemproxy的架构,明白与它交互的组件。下面就是一般twemproxy的架构图
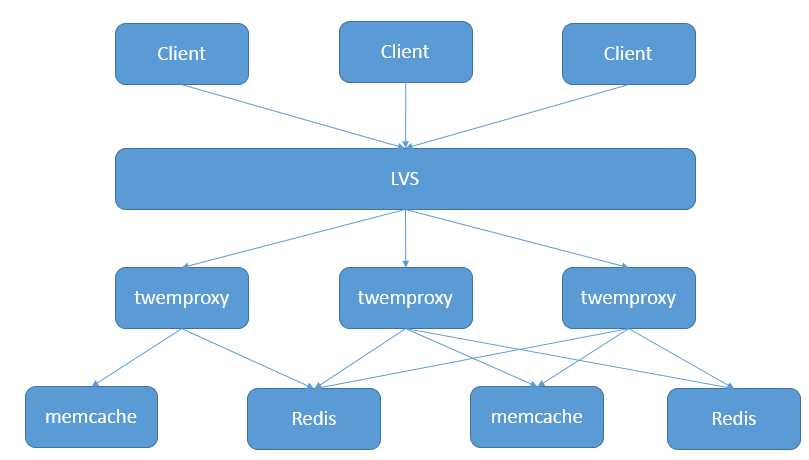 图1 twemproxy架构图
图1 twemproxy架构图
图1中,client是客户端,这里的客户端可以是很多应用,如网页,也可以是一些需要redis支持的服务器。LVS是Linux虚拟服务器,它主要用于负载均衡,当然这一个层的负载均衡可以通过其他手段完成,如HAproxy等,当然也可以不需要这一层,可以让客户端直连twemproxy。memchache和redis是twemproxy目前支持的两种高速缓存服务器,考虑到高可用性和具体功能,一般会使用redis服务器。
从这幅架构图上,我们能开始逐一说明twemproxy的特性,阅读源码文件夹下的《README.md》的features,至于他是如何实现的,就需要我们去解读代码,这不是这一章要完成的任务。

图2 twemproxy特性
1.Fast,即快速,据测试,直连twenproxy和直连redis相比几乎没有性能损失,这已经很逆天了,最重要的是他还没有进行读写分离就能达到这样的效果,确实fast
2.Lightweight,即轻量级,就我个人而言,它代码量就是轻量级的,因为透明连接池,内存零拷贝以及epoll模型的使用,使得它足够快速和轻量级。
3.Enables pipelining of requests and responses,Keeps connection count on the backend caching servers low,即保持前端的连接数,减少后端的连接数,这里主要得益于透明连接池的使用,前端主要指的是client和lvs,后端指的是redis和memchache,这个好处特别明显,既可以减少了redis的连接负载,又保持了保持了前端的功能。
4.Enables pipelining of requests and responses,即将请求和回复管道化,这里我的理解是他将请求包和回复包一一对应起来后,使得它的请求和回复更明确。
5.Supports multiple server pools simultaneously,Shard data automatically across multiple servers这两个特性,这个是通过我在前面讲到过twemproxy的分片功能来实现的。
6.Implements the complete memcached ascii and redis protocol,支持这两个协议,当然现在只支持其中大部分的协议而不是全部,这个会在后面专门说明。
7.Supports multiple hashing modes including consistent hashing and distribution.就是他支持很多哈希算法来哈希key。
8.Easy configuration of server pools through a YAML file.他的配置文件是通过YAML文件来配置的
9.Can be configured to disable nodes on failures.自动指出失败的节点。
10.Observability via stats exposed on the stats monitoring port.这是他的监控功能,一般比较少用。
通过上述的功能分析,我们可以理出一个我们值得关注的实现上的功能列表:
1.内存管理,这是导致特性1和4的关键之一,他通过一些方法,如内存用完后不立即释放将其放入内存队列里以备它用,内存零拷贝等手段使内存使用效率大幅提高。对应源码中的nc_mbuf 文件
2.透明连接池,这是导致特性1,3的关键之一,当然连接池内的连接同样的是使用完后不立即释放将其放入连接队列里以备它用。对应源码中的nc_connection 文件
3.分片,这是导致特性5,6的关键,也是twenproxy的核心功能。当然后面的7,8也导致了分片能得以进行。对应源码中的proto文件夹、hashkit文件夹
4.配置文件,这影响了特性8,同时这份代码在配置上的代码风格非常简约,对应源码中的nc_conf 文件
5.监控,不是特别了解但是它完成了9,10特性,对应源码中的nc_proxy 、nc_stats 文件
twemproxyLinux下安装
1.首先安装autoconf2.69,这个请参考我的博文http://www.cnblogs.com/onlyac/p/5408420.html
2.进入源码目录
cd twemproxy
3.使用autoconf进行编译准备
autoreconf -fvi
./configure CFLAGS="-g -gstabs -O3 -fno-strict-aliasing" --enable-debug=full
4.编译以及安装
make && make install
这样编译以及安装完的程序nutcracker已在src目录下生成了。
总结
在这篇文章中,我们首先概述了twemproxy,接着通过架构分析,我们得提取了会成为我们阅读源码的一些重要关注点和twemproxy的工作环境,最后阐述了如何安装twemproxy。
标签:utc 自动 pip 配置 源码 mode 网页 代码风格 end
原文地址:http://www.cnblogs.com/onlyac/p/6262096.html