标签:bsp csv ade archive machine das head 分类 src
0. 训练数据集:Iris dataset (鸢尾花数据集),获取网址https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data
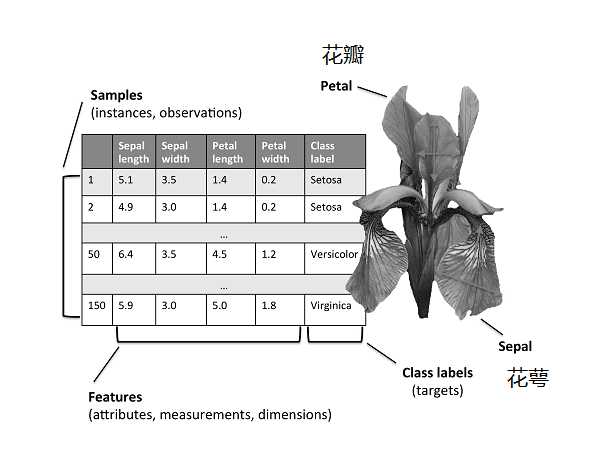
如下图所示,鸢尾花数据集中每行数据前四列为特征值分别是花瓣长/宽、花萼长/宽,鸢尾花分三类:Setosa,Versicolor,Virginica
可以用如下示例代码保存数据集并显示最后5行
1 import pandas as pd 2 df = pd.read_csv(‘https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data‘, header=None) 3 df.tail()
通过对数据集中的鸢尾花四个特征值,对数据集分类,确定属于哪一类的鸢尾花,这里选取前100个数据分析,示例代码如下:
1 import matplotlib.pyplot as plt 2 import numpy as np 3 import pandas as pd 4 5 df = pd.read_csv(‘https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data‘, header=None) 6 7 8 # select setosa and versicolor 9 y = df.iloc[0:100, 4].values 10 y = np.where(y == ‘Iris-setosa‘, -1, 1) 11 12 # extract sepal length and petal length 13 X = df.iloc[0:100, [0, 2]].values 14 15 # plot data 16 plt.scatter(X[:50, 0], X[:50, 1], 17 color=‘red‘, marker=‘o‘, label=‘setosa‘) 18 plt.scatter(X[50:100, 0], X[50:100, 1], 19 color=‘blue‘, marker=‘x‘, label=‘versicolor‘) 20 21 plt.xlabel(‘sepal length [cm]‘) 22 plt.ylabel(‘petal length [cm]‘) 23 plt.legend(loc=‘upper left‘) 24 25 plt.tight_layout() 26 27 plt.show()
输出结果如下:
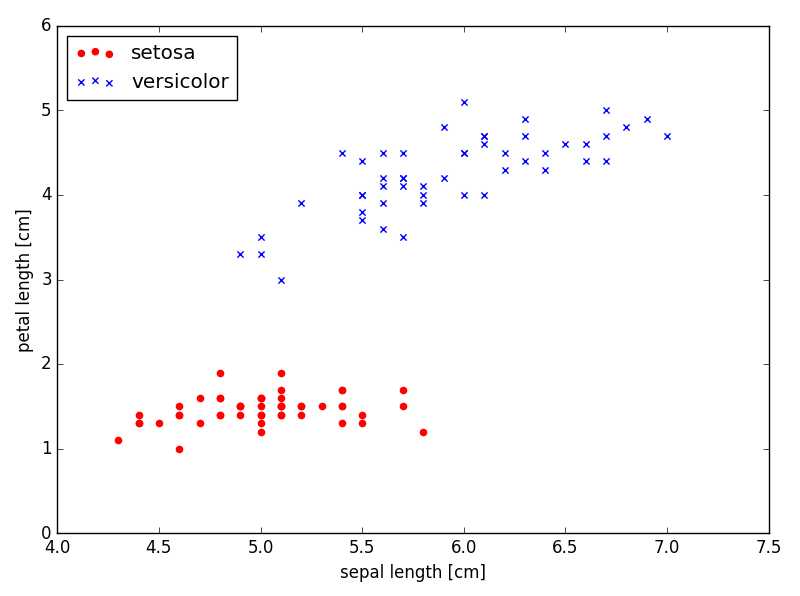
通过对四个特征中两个(花瓣长,花萼长)的统计,可以看到蓝色和红色有了明显的界限,实现了分类。
标签:bsp csv ade archive machine das head 分类 src
原文地址:http://www.cnblogs.com/fox17/p/6266669.html