标签:技术分享 select 分析 lin 信息 images 部分 存储空间 比例
原文:Benatia, A., Ji, W., Wang, Y., & Shi, F. (2016, August). Sparse Matrix Format Selection with Multiclass SVM for SpMV on GPU. In Parallel Processing (ICPP), 2016 45th International Conference on (pp. 496-505). IEEE.
SpMV(Sparse Matrix-Vector Multiplication)是指的将一个稀疏矩阵与稠密向量相乘的操作。在矩阵比较稀疏的情况下,稠密矩阵不适合做矩阵相乘运算,因为大部分运算和存储空间浪费在了数值0的运算上。使用稀疏矩阵进行SpMV的时候,其性能因不同的稀疏矩阵格式以及不同的输入矩阵而影响,因此对于给定的矩阵,重要之处在于如何选择一个最好的稀疏矩阵格式来表示,这也是论文要解决问题。论文的主要思想是利用机器学习的方法寻找最佳表示方法,首先分析稀疏矩阵的一些特征,然后利用数据集的这些特征训练一个SVM多值分类器,最后用分类器对给定的稀疏矩阵选择合适的稀疏矩阵格式。
在实验过程中,文中使用了四中稀疏矩阵格式:COO、CSR、ELL和HYB。COO是最原始的一种稀疏矩阵存储格式,使用三个数组来分别记录每个元素的行号、列号和数值,这种方式简单,但是空间上并不是最优。CSR是比较常用的一种格式,也使用了三个数组,分别是每个元素的数值和其对应的列号,另外再用一个数组表示某一行第一个元素在数值列表中的位置。ELL则是用两个和原始矩阵行数相同的矩阵来分别存储列号和数值,行号就用自身所在的行来表示。HYB则是为了解决ELL中行数比较多的时候造成其他行浪费的问题,HYB把多出来的元素用COO单独存储。
SpMV要达到最佳性能主要受两个方面的影响,一是取决于矩阵的稀疏程度,二是受不同的GPU而影响。给定一个稀疏矩阵,选择GPU上最合适的存储格式是一个分类问题,也即可以把四种格式当成四个分类:coo、csr、ell和hyb,这样就把最佳格式的选取问题转换成了一个根据稀疏矩阵特征的分类问题。文中使用的机器学习方法进行分类,其步骤为:
文中使用的数据集是University of Florida Sparse Matrix Collection,并且做了一些调整,比如由于COO比例较小可能会影响分类,而且通过实验数据表明COO对整体性能的影响不大,所以移除了COO格式的数据。另外,在该数据集上的实验也表明了对于稀疏矩阵来说,选择最优格式能够显著提升其性能。
特征的选取具体如下:
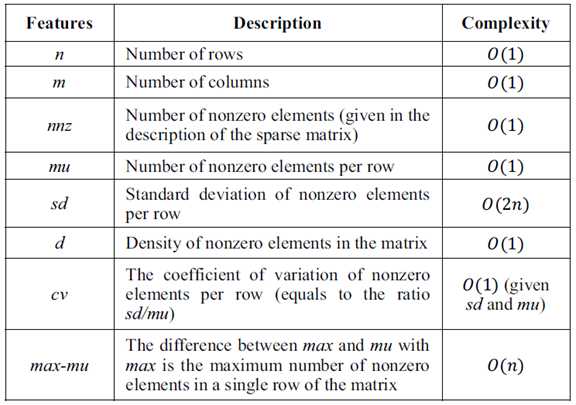
对于上述的特征,选取的数据集能够进行很好的覆盖,并且这些特征之间的相关性都比较小,也就是说每一个特征都能够反映出矩阵的信息。文中使用SVM方法来对特征集进行分类,具体实现是使用的LibSVM。另外作者发现对原始的数据点做一次对数变换之后,能够得到更加适合的尺度。有了特征数据,确定了分类算法,接下来就是进行训练,具体的训练过程为:将矩阵对应的8维特征数据点与对应的最佳格式标记起来,然后将这些数据点分成5份,随机选择80%来进行训练,剩下的20%进行测试。
从测试集的分类上来看,该分类器在两个系列的GPU,Fermi和Maxwell上,分类准确度分别为82.0%和88.5%。为了评估分类器对于最佳稀疏矩阵格式选择的提升效果,作者使用了LUB(Loss Under Best)的计算方法,该方法通过计算分类器的选择与最佳选择的平均性能损失来衡量准确度。通过LUB方法得出的结论是:在两个系列的GPU上,LUB平均都小于2%,并且在最坏的情况下也不会超过3%。在只使用一种稀疏矩阵存储格式的情况下,分类器能够平均提升8.9%至85.5%的性能,与最坏选取的比较则更为明显。从分类器的收敛情况上看,Maxwell相对于Fermi来说,能够更快地达到收敛。另外与决策树相对比来说,使用多值SVM分类器有着最好的准确率和最佳性能的选择。
总的来说,论文运用的机器学习方法相对于最佳稀疏矩阵格式的选取,能够达到98%的准确率,并且能够避免选择到最差的格式。
论文笔记:Sparse Matrix Format Selection with Multiclass SVM for SpMV on GPU
标签:技术分享 select 分析 lin 信息 images 部分 存储空间 比例
原文地址:http://www.cnblogs.com/lianera/p/6273321.html