标签:img rdd variables task 技术分享 image port 扁平化 strong
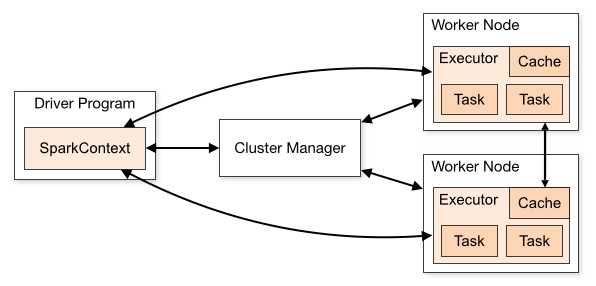
SparkContext
通常作为入口函数,可以创建并返回一个RDD。
如把Spark集群当作服务端那Spark Driver就是客户端,SparkContext则是客户端的核心;
如注释所说 SparkContext用于连接Spark集群、创建RDD、累加器(accumlator)、广播变量(broadcast variables)
map操作:
会对每一条输入进行指定的操作,然后为每一条输入返回一个对象;
flatMap操作:
“先映射后扁平化”
操作1:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象
操作2:最后将所有对象合并为一个对象
zip函数:
x = [1, 2, 3] y = [4, 5, 6, 7] xy = zip(x, y) print xy #[(1, 4), (2, 5), (3, 6)]
from pyspark import SparkContext sc = SparkContext(‘local‘) ‘‘‘ 在一个Spark程序的开始部分,有好多是用sparkContext的parallelize制作RDD的, 是ParallelCollectionRDD,创建一个并行集合。 doc这里包含2个task ‘‘‘ doc = sc.parallelize([[‘a‘, ‘b‘, ‘c‘], [‘b‘, ‘d‘, ‘d‘]]) print(doc.count()) # 2 ‘‘‘ map操作:会对每一条输入进行指定的操作,然后为每一条输入返回一个对象; flatMap操作:“先映射后扁平化” 操作1:同map函数一样:对每一条输入进行指定的操作,然后为每一条输入返回一个对象 操作2:最后将所有对象合并为一个对象 ‘‘‘ words = doc.map(lambda d: d).collect() print(words) words = doc.flatMap(lambda d: d).collect() print(words) words = doc.flatMap(lambda d: d).distinct().collect() print(words) ‘‘‘ zip(list1, list2)把list1,list2变成一个list(e1(list1), e1(list2),e2...) 这里把字符给标号(0 : len(words)) ‘‘‘ word_dict = {w: i for w, i in zip(words, range(len(words)))} ‘‘‘ broadcast将变量word_dict高效的传递给每一个子节点 word_dict_b就是word_dict在子节点处理函数中的别名,内容是一致的区别就是要是用.value来用里面的值 ‘‘‘ word_dict_b = sc.broadcast(word_dict) def word_count_per_doc(d): dict_tmp = {} wd = word_dict_b.value for w in d: dict_tmp[wd[w]] = dict_tmp.get(wd[w], 0) + 1 return dict_tmp ‘‘‘ 每一个doc都会调用一次 word_count_per_doc ‘‘‘ print(doc.map(word_count_per_doc).collect()) print("successful!")
SparkContext, map, flatMap, zip以及例程wordcount
标签:img rdd variables task 技术分享 image port 扁平化 strong
原文地址:http://www.cnblogs.com/luntai/p/6273720.html