标签:src 电话 打印 type 文字 gre javascrip 身份证 单词
为什么要用正则表达式?
原因:我们通常在网页上回搜索一些关键字或者检索特殊的内容,这时候我们需要对网页的内容进行检索,正则表达式可以方便的解决这个问题。通俗的讲就是验证各种各样的字符串:比如验证邮箱的格式,验证身份证,验证手机号码等。
什么是正则表达式?
正则表达式是用某种模式去匹配一类字符创的一个公式。
创建正则表达式的两种方法:
(1)隐式创建:var regExp=/正则表达式/gi(g表示global全局搜索,i表示不区分大小写)
(2)显式创建:var regExp=new RegExp("正则表达式","gi")
另外除了gi外还有一个m,代表是否换行检索,比如现在搜索以某个字母开头的段落,这时候m可以表示换行检索,否则只能检索到第一个开头的。
子表达式:
举个例子:
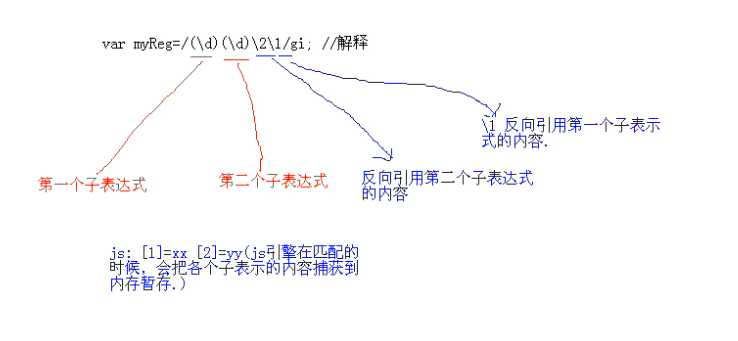
正则表达式
第一点:--------------有关正则前沿介绍 正则表达式是用来进行文本处理的技术,是语言无关的,在几乎所有语言中都有实现。javascript中还会用到。一个正则表达式就是由普通字符以及特殊字符(称为元字符)组成的文字模式。该模式描述在查找文字主体时待匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。就像通配符“*.jpg”、“%ab%”,它是对字符串进行匹配的特殊字符串正则表达式是非常复杂的,不要希望一次都掌握,理解正则表达式能做什么(字符串的匹配、字符串的提取、字符串的替换),掌握常用的正则表达式用法,以后用到再查就行。
第二点:--------------有关正则使用地方 项目中的采集器、敏感词过滤、URLRewite、Validator也会涉及到正则表达式。
第三点:--------------元字符介绍 要想学会正则表达式,理解元字符是一个必须攻克的难关。不用刻意记
1).:匹配任何单个字符。例如正则表达式“b.g”能匹配如下字符串:“big”、“bug”、“b g”,但是不匹配“buug”,“b..g”可以匹配“buug”。
2)[ ] :匹配括号中的任何一个字符。例如正则表达式“b[aui]g”匹配bug、big和bag,但是不匹配beg、baug。可以在括号中使用连字符“-”来指定字符的区间来简化表示,例如正则表达式[0-9]可以匹配任何数字字符,这样正则表达式“a[0-9]c”等价于“a[0123456789]c”就可以匹配“a0c”、“a1c”、“a2c”等字符串;还可以制定多个区间,例如“[A-Za-z]”可以匹配任何大小写字母,“[A-Za-z0-9]”可以匹配任何的大小写字母或者数字。
3)( ) :将 () 之间括起来的表达式定义为“组”(group),并且将匹配这个表达式的字符保存到一个临时区域,这个元字符在字符串提取的时候非常有用。把一些字符表示为一个整体。改变优先级、定义提取组两个作用。
4)| :将两个匹配条件进行逻辑“或”运算。‘z|food‘ 能匹配 "z" 或 "food"。‘(z|f)ood‘ 则匹配 "zood" 或 "food"。
5)+ :匹配前面的子表达式一次或多次,和*对比(0到多次)。例如正则表达式9+匹配9、99、999等。 “zo+”能匹配 “zo”以及 “zoo” ,不能匹配"z"。
6)*:匹配0至多个在它之前的子表达式,和通配符*没关系。例如正则表达式“zo*”能匹配 “z” 、“zo”以及 “zoo”;因此“.*”意味着能够匹配任意字符串。"z(b|c)*"→zb、zbc、zcb、zccc、zbbbccc。"z(ab)*"能匹配z、zab、zabab(用括号改变优先级)。
7)? :匹配前面的子表达式零次或一次。例如,"do(es)?" 可以匹配 "do" 或 "does" 。一般用来匹配“可选部分”。
8){n} :匹配确定的 n 次。"zo{2}"→zoo。例如,“e{2}” 不能匹配“bed”中的“e”,但是能匹配“seed”中的两个“e”。
9){n,} :至少匹配n次。例如,“e{2,}”不能匹配“bed”中的“e”,但能匹配 “seeeeeeeed”中的所有“e”。
10){n,m} :最少匹配 n 次且最多匹配 m 次。“e{1,3}”将匹配“seeeeeeeed”中的前三个“e”。
11)^(shift+6) :匹配一行的开始。例如正则表达式“^regex”能够匹配字符串“regex我会用”的开始,但是不能匹配“我会用regex”。
12)^另外一种意思:非!(暂时不用理解)
13)$ :匹配行结束符。例如正则表达式“浮云$” 能够匹配字符串“一切都是浮云”的末尾,但是不能匹配字符串“浮云呀”
第三点:-------------简写正则表达式 注意这些简写表达式是不考虑转义符的,这里的\就表示字符\,而不是C#字符串级别的\,在C#代码中需要使用@或者\双重转义。
区分C#级别的转移和正则表达式级别的转移,恰好C#的转义符和正则表达式的转义符都是\而已。正则表达式的转移是在C#之后的(层层盘剥)。
把C#的转义符想成%就明白了。在C#看来@"\-"就是\-这个普通的字符串,只不过在正则表达式分析引擎看来他有了特殊含义。
"\\d"或者@"\d" \d:代表一个数字,等同于[0-9]
\D:代表非数字,等同于[^0-9]
\s:代表换行符、Tab制表符等空白字符
\S:代表非空白字符
\w:匹配字母或数字或下划线或汉字,即能组成单词的字符
\W:非\w ,等同于[^\w] d:digital;s:space、w:word。
大写就是“非”
第四点:-------------.NET中的正则表达式 正则表达式在.Net就是用字符串表示,这个字符串格式比较特殊,无论多么特殊,在C#语言看来都是普通的字符串,具体什么含义由Regex类内部进行语法分析。
正则表达式(Regular Expression)的主要类:Regex.IsMatch方法用于判断一个字符串是否匹配正则表达式。 字符串匹配例子: Regex.IsMatch("bbbbg","^b.*g $"); Regex.IsMatch("bg", "^b.*g $ "); Regex.IsMatch("gege", "^b.*g $ "); 一定不能忘了^和$,否则也能匹配yesbagit
案例1:判断是否是合法的邮政编码(6位数字) Regex.IsMatch("100830","^[0-9]{6}$") Regex.IsMatch("119", @"^\d{6}$"); 解释:由元字符定义得知"[0-9]"表示0到9的任意字符,"{6}"表示前面的字符匹配6此,因此“[0-9]{6}”中的{6}表示对数字匹配6次(000000123)。简写表达式得知“[0-9]”可以被“\d”代替,所以第二种写法“\d{6}”也是正确的。 案例2:判断一个字符串是不是身份证号码,即是否是15或18位数字。 错误写法:Regex.IsMatch("123456789123456789", @"^\d{15}|\d{18}$"),表示15位数字开头或者18位数字结尾 正确写法:Console.WriteLine(Regex.IsMatch("0111111111111111", @"^\d{15}$|^\d{18}$"))或者@"^(\d{15}|\d{18})$" 案例3:判断字符串是否为正确的国内电话号码,不考虑分机。
比如“010-95555”、“01095555”、“95555”都是正确的号码。区号为3位或者4位。 Regex.IsMatch("123456-95555", @"^\d{3,4}\-?\d+$") "^\d{3,4}\-?\d+$"表示被匹配的字符序列应该是由三至四位数字组成,由于长途区号的连字符“-”可有可无,所以这里使用“?”元字符进行说明。由于连字符“-”在正则表达式 中有特殊含义(表示范围,比如[0-9]),所以要对其进行转义。 案例4:判断一个字符串是否是合法的Email地址。 一个Email地址的特征就是以一个字符序列开始,后边跟着“@”符号,后边又是一个字符序列,后边跟着符号“.”,最后是字符序列 Regex.IsMatch("email12@mail.com", @"^\w+@\w+\.\w+$"); []括号中的任意字符,\w字母、数字、下划线,+一到多个。由于.在正则表达式中有特殊的含义,因此对于真正想表达“.”则需要转移“\.”。
案例5: 1、匹配IP地址,4段用.分割的最多三位数字。 192.168.54.77、333.333.333.333假设都是正确的。 @"^\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3}$"。.是正则表达式中的特殊含义,因此需要转义。 2、判断是否是合法的日期格式“2008-08-08”。四位数字-两位数字-两位数字。进一步严谨@"^\d{4}\-\d{2}\-\d{2}$" 3、判断是否是合法的url地址,http://www.test.com/a.htm、ftp://127.0.0.1/1.txt。字符串序列://字符串序列。@"^\w+://.+$"。//简化的识别,项目中你搜“w3c URL 正则表达式”。.+而不是\w,否则"?id=1"中的?就不能匹配了。 http://www.test.com/a.aspx?id=1
第五点:---------------字符串的提取 正则表达式还可以用来进行字符串提取 Match match = Regex.Match("age=30", @"^(. +)=(.+)$"); if (match.Success) { Console.WriteLine(match.Groups[1] .Value); Console.WriteLine(match.Groups[2] .Value); } match的Success属性表示是否匹配成功;
正则表达式中用()将要提取的内容括起来,然后就可以通过Match的Groups属性来得到所有的提取元素,注意Groups的序号是从1开始的,0 有特殊含义 案例:
1)从文件路径中提取出文件名(包含后缀) @"^.+/(.+)$"。比如从c:/a/b.txt中提取出b.txt这个文件名出来。
项目中用Path.GetFileName更好。
贪婪模式。
2)从“June 26, 1951”中提取出月份June来。@"([a-zA-Z]+)\s+\d{1,2},\s*\d{4}"进行匹配。月份和日之间是必须要有空格分割的,所以使用空白符号“\s”匹配所有的空白字符,此处的空格是必须有的,所以使用“+”标识为匹配1至多个空格。之后的“,”与年份之间的空格是可有可无的,所以使用“*”表示为匹配0至多个
3)从Email中提取出用户名和域名,比如从test@163.com中提取出test和163.com。 4)“192.168.10.5[port=21,type=ftp]”,这个字符串表示IP地址为192.168.10.5的服务器的21端口提供的是ftp服务,其中如果“,type=ftp”部分被省略,则默认为http服务。请用程序解析此字符串,然后打印出“IP地址为***的服务器的***端口提供的服务为***” ^(\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})\[port=(\d{1,5})(,type=(\w+))?\]$
第六点:---------------贪婪和非贪婪模式 从文本提取出名字: Match match = Regex.Match("大家好。我是S.H.E。我22岁了。我病了,呜呜。fffff", "我是(.+)。");//没有加^$。
看结果。+、*的匹配默认是贪婪(greedy)的:尽可能多的匹配,直到“再贪婪一点儿”其后的匹配模式就没法匹配为止。 在+、*后添加?就变成非贪婪模式
(? 的另外一个用途):让其后的匹配模式尽早的匹配。修改成"我是(.+?)。" 一般开发的时候不用刻意去修饰为非贪婪模式,只有遇到bug的时候发现是贪婪模式的问题再去解决。
第七点:--------------匹配组 正则表达式可以从一段文本中将所有符合匹配的内容都输出出来。Match获得的是匹配的第一个。 Regex.Matches方法可以获得所有的匹配项。
标签:src 电话 打印 type 文字 gre javascrip 身份证 单词
原文地址:http://www.cnblogs.com/fengli9998/p/6275464.html