标签:优点 http leave 信息 向量 war 模型选择 不同的 没有
继续上节内容介绍学习理论,介绍模型选择算法,大纲内容为:
回顾上节的偏差方差权衡现象,若选择过于简单的模型,偏差过高,可能会导致欠拟合;若选择过于复杂的模型,方差过高,可能会导致过拟合,同样模型的一般适用性不好。
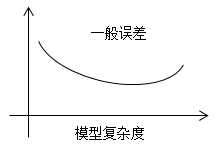
模型复杂度:多项式的次数或参数的个数。
(1)尝试选择多项式的次数
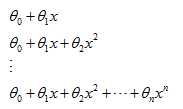
(2)尝试选择参数
τ:局部加权线性回归带宽参数
C:支持向量机中的权衡参数
----------------------------------------------------------------------------------------------------------------------------------------------------------------
一、模型选择方法:
模型选择问题是为了自动进行方差偏差平衡,常用交叉验证的方法。
交叉验证的基本思路:
这里只考虑到了经验风险最小化,往往会选择次数更高的多项式而造成高方差,因此仅仅如此是不够的。接下来介绍三种实用的交叉验证算法。
1. 保留交叉验证(Hold-out cross validation)
由于通常情况下可以采集到的数据量有限,而保留交叉验证子集的提出也只是为了模型选择,还有几种交叉验证的变种,可以有效地提高数据利用率。
2. k重交叉验证(k-fold cross validation)

之后还需要对模型利用100%的数据进行重新训练。
通常k=10,即选择90%的数据进行训练,10%进行测试;k=5同理。
缺点:计算量大
3. 留1交叉验证(Leave-one-out CV)

优点:数据的利用率可能比k重交叉验证的更高;
缺点:需要大量的计算,常在训练样本非常少的情形下才使用。
二、特征选择方法:
特征选择是模型选择的一种特例,在研究机器学习的问题时,通常会面临一个非常高维的特征空间,如之前谈到的垃圾邮件分类问题,特征向量可以达到30000-50000维,存在过拟合的风险,如果可以降低特征的数量,也就减小了学习算法的方差,从而降低过拟合的风险。
若有n个特征,那么有2n种可能的子集,这是一个相当大的特征空间,通常在做特征选择时采用启发式规则对特征空间进行搜索。
1. 封装特征选择(Wrapper feature selection)
(1)前向搜索方法(Forward search)
(1)i=1,...,n,尝试加入特征i到特征子集F中,对模型进行交叉验证,估计一般误差;
(2)设置F=F∪(上步骤中得到的最好特征,即一般误差最小的特征);
大致思路是:从空集开始,每次迭代考虑那些还没有被加到F中的特征,尝试将新的特征加入到F中,并对训练集进行训练,用交叉验证集进行评估,找到一个最好的特征加入F中,也就是说保留具有最小保留交叉验证误差的特征。前向搜索方法也是一种最常用的封装特征选择(Wraper feature selection)。
(2)后向搜索方法(Backward search)
后向搜索方法最开始需要训练整个特征集合,结果可能有意义也可能没有意义,且计算量较大,故前向搜索方法更为常用。以上两种方法均属于启发式搜索(searcheristics),它的缺点是计算量大,且不能保证找到最好的特征子集。
接下来再介绍一种特征选择方法,它的计算量相对要小,虽然效果有时不如上述两种方法。
2. 过滤特征选择(Filter feature selection)
对每个特征都计算一些衡量标准来衡量输入Xi对于输出y的影响度,并用分数S(i)来表示,常用的分数有两种:相关度或相互信息。
(1)相关度(correlation)Corr(xi,y)
(2)相互信息MI(Mutual information)
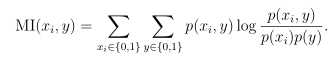
在信息论中也可以表示为:
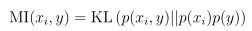
用于衡量两个概率分布之间的差异,也叫作KL距离。当x与y是相互独立的,那么p(xi,y)与p(xi)p(y)是相等的,那么KL距离为0,即相互信息为0;当x与y相互影响时,特别地,影响越大,则KL距离越大,相互信息值也越大。
最后需要选取具有最大相关度或相互信息的前k个特征,可以采用交叉验证的方法或手动获取的方法。
三、贝叶斯统计与规范化
特征选择用于简化模型,实际上是利用减少特征数量来降低模型需要拟合的参数数目,来防止过拟合现象。而另一种防止过拟合的方法可以保留所有的参数,它是规范化(regularization)。
以线性回归为例,两个学派有两种不同的理解。
1. 频率学派
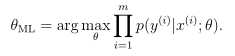
利用最大似然估计来评估参数θ,频率学派认为这些参数是未知的常量,而我们的工作就是利用各种数理统计的方法去估计这些参数的值。
2. 贝叶斯学派
贝叶斯学派认为参数θ为一个随机变量,需要赋予一个先验概率来表示θ取值的不确定性。
给定一个训练样本集合S={(x(i),y(i))}i=1~m,计算参数的后验概率:
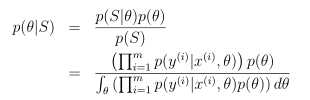
对于新输入x进行预测,得到
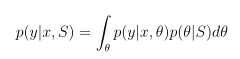
预测y的期望值:
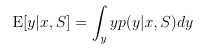
由于参数θ为n+1维的向量,当维度很高时,直接计算后验概率会很难,所以通常我们不直接计算,而是设法取后验概率的最大值,称作最大化估计MAP(maximum a posteriori)。
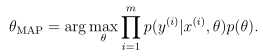
通常θ服从高斯分布,θ~N(0,τ2I),贝叶斯规范化每次拟合会越来越光滑,因为减小了τ的值,使得参数越来越接近于0,从而使得过拟合几率下降。
总结:对比两种学派的不同看法,其实贝叶斯学派只比频率学派多乘以一个参数的先验概率,而其效果就是使得拟合效果平滑化,可以有效降低模型的过拟合现象。
标签:优点 http leave 信息 向量 war 模型选择 不同的 没有
原文地址:http://www.cnblogs.com/wallacup/p/6274499.html