标签:心跳机制 val 日志 alt 内存 put hadoop 数据保存 分布式存储
1.今天,我们来介绍spark以及dataframe的相关的知识点,但是在此之前先说一下对以前的hadoop的一些理解
当我启动hadoop的时候,上面有hdfs的存储结构,由于这个是分布式存储,所以当一个节点挂了之后,此后由于
还有别的机器上存储这些block块(这里面你肯定要问了,我们怎么知道它挂了,其实我前面关于akaka的时候rpc
通信的机制,心跳机制),所以这个是我们选择它的理由之一,还有一个原因我们可以进行无限扩容,是因为当我们
使用zookeeper进行管理这些datanode的时候,所以当我们的存储的容量不够的时候,这个时候我们只需要往里
面加机器就可以了,至于存储到哪里,怎么存储,这个就不需要我们管理,这个时候,我们完全可以依赖zookeeper
进行管理即可,在我们启动这个hadoop的环境的时候,分为namenode以及datanode,这个时候我们知道namenode
上面记录着一些block存放入datanode的路径,(其实datanode完全就相当于记录这些block这些的载体),这个时候
我们看到里面有一个yarn启动了,此时这个yarn的流程就是根据namenode判断这些datanode的总资源情况,消耗资源,
还剩资源情况,来决定把当前的这个任务分配到那个datanode上面执行,总的来说,namenode管的是物理地址上面的分配,
以及查找,而yarn则负责的是以何种方式进行分配,从而达到整个资源的最优处理性
其实,一般公司(我司也一样),就是通过日志文件落盘到hdfs上面,我们通过spark来获取这些数据,然后在work上面处理
,然后在把处理后的数据数据放到hdfs的这样的一个流程,好了,大体不详细说明,下面介绍spark的dataframe的相关知识
2.dataframe
1.加载数据,使其变为dataframe
val df = sqlContext.load("hdfs://192.168.109.136/person/output",json)
这个样子读出来就直接变成了DataFrame了(如果上面的命令出错,极大的情况可能是内存不足)

df.select("id","name").save("hdfs://192.168.109.136:9000/output1")此时这个df是
dataframes,把查询到的数据保存到hdfs上面,那么当我们读出来的时候,就是乱码,因为我们明确
的指定要保存的格式

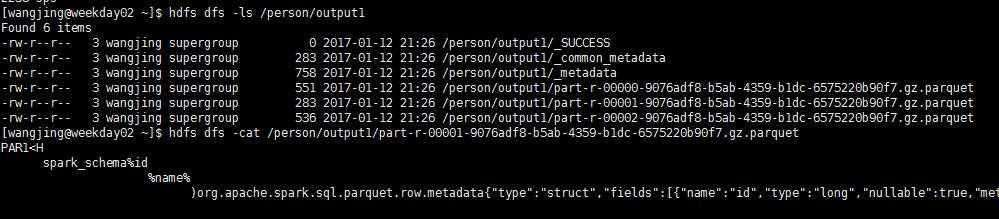
此时这个文件被压缩
则我们如果写成
df.select("id","name").save("192.168.109.136:9000/person/output1","json"),这个里面
存储的就是json格式
3.Parquet File
Apache Parquet最初的设计动机是存储嵌套式的数据,比如Protocolbuffer,thrift,json等,将这类
数据存储成为列式格式,以方便对其高效压缩和编码,这也是Parquet相比于ORC(优化的)优势,他能
够透明的将Protobuf和thrif类型的数据进行列式存储(其中,ORC(OptimizedRC File))存储源自于
RC(RecordColumnar File)这种存储格式,RC是一种列式存储引擎)
标签:心跳机制 val 日志 alt 内存 put hadoop 数据保存 分布式存储
原文地址:http://www.cnblogs.com/wnbahmbb/p/6280476.html