标签:重复 访问 单行 oat 数据类型 glob 自动 数据 span
一、python是什么样的语言
1、编译型语言和解释型语言,python是解释型语言
1.1、编译型语言就是把源程序代码一次性翻译成机器码(计算机可识别的代码),然后交给计算机去运行,一般需经过编译(compile)、链接(linker)这两个步骤。编译是把源代码编译成机器码,链接是把各个模块的机器码和依赖库串连起来生成可 执行文件。
优点:编译器一般会有预编译的过程对代码进行优化。 因为编译只做一次,运行时不需要编译,所以编译型语言的程序执行效率高 。可以脱离语言环境独立运行。
缺点:编译之后如果需要修改就需要整个模块重新编译。编译的时候根据对应的运行环境生成机器码,不同的操作系统之间移植就会有问题,需要根据运行的操作系统环境编译不同的可执行文件。
代表语言:C、C++、 Pascal、Object-C以及swift等

1.2、解释型语言就是在程序执行到某个指令的时候在翻译这段代码,等于是一直在做翻译代码、执行代码、翻译代码、执行代码,直到代码结束
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。
代表语言:JavaScript、Python、Erlang、PHP、Perl、Ruby等
1.3、混合型语言
混合语言就是综合以上两种的有点,先源代码翻译成字节码文件(可以看成是中间码,介于源码和机器码之间),然后交给虚拟机(如java的jvm),直接可以把编译好的字节码文件放在各个平台上去运行,而不需要去改动,每个平台 (windows、linux、unix等)都有已经写好的虚拟机,每个平台的虚拟机会自动翻译成对应平台的机器码文件,可以达到一次编译,多次运行的目的
代表语言:Java等
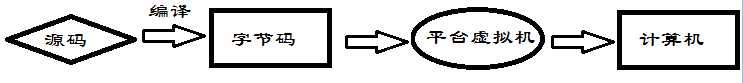
2、静态语言和动态语言
2.1、静态语言
静态语言就是在编译之前必须要确定语言的类型,多数静态语言在声明时必须写变量类型
2.2、动态语言
动态语言通常是在运行时才确定语言的类型,多数动态语言是不需要声明类型的,变量的类型通常是赋值的值的类型,如:var = ‘a‘,var就是字符型
3、强类型语言和弱类型语言
3.1、强类型语言
强类型语言不能随着环境改变而改变,只有同类型的才可以操作,需要使用函数或方法进行强制转换类型,python就是强类型语言,如:a = 1 b = ‘2‘,str(a)+b或a+int(b)才可以进行操作,否则就会报错必须要强制转换一下
3.2、弱类型语言
弱类型语言是可以随时进行操作的,而不需要强制转换类型后在进行操作,vbs就是弱类型语言,如:a = 1,b = ‘2‘,a+b,计算结果是12,a + 1,计算结果是2
4、python语言的优缺点
4.1、python语言的优点
4.1.1、python语言被定位为“优雅”、“明确”、“简单”,python入门很容易
4.1.2、开发效率高,python会提供非常多的三方类库,也可以对基础类库进行二次开发,达到自己想要的效果 4.1.3、python被称为胶水语言,会很容易和其他语言结合,调用其他语言已经写好的代码,或是直接嵌入到其他语言中
4.1.3、python拥有较好的可移植性(不同平台)和可扩展性
4.2、python语言的缺点
4.2.1、python语言运行速度慢,比c语言要慢很多,比java也要慢一些,但是一般感觉不出来,需要借助工具才能看到
4.2.2、python不支持多cpu处理,就是说多核cpu也起不到作用,同一时间只有一个线程在运行
4.2.3、python由于是解释性语言,所以代码不能加密
二、变量部分
变量概念:变量主要是提供为了其他代码以后调用数据而存储数据使用的
1、变量规则
1.1、变量由数字、字母下划线组成,不能以数字开头
1.2、如果变量是有多个单词组成的,使用驼峰式,如:myFristVar,就是从第二个单词开始首字符是大写,其余字母小写;
1.3、也可以是用全部都是首字母大写,如:MyFristVar
1.4、或是使用下划线分隔,如:my_frist_var
1.5、如果所有字符都是大写,则代表是常量,不过这只是开发人员的规范,多个单词用下划线分隔,并不是python的规则,也是可以改变的,其他有的语言中有的可以用关键字明确声明,如:c语言中的const
1.6、有一些单词是被python作为关键字占用了,有and, as, assert, break, class, continue, def, del, elif, else, except, exec, finally, for, from, global, if,import,in, is, lambda, not, or, pass, print, raise, return, try, while, with, yield
1.7、扩展
1.7.1、实例变量用单下划线开头,其他和普通变量一样,如:_myvar,类变量(就是上面1.3中的全部大写的变量)是指一个类的变量,通常为静态变量(类似于java的static),而实例变量通常是动态的类变量,和实例变量的区别在于:类变量是所有对象共有,其中一个对象将它值改变,其他对象得到的就是改变后的结果;而实例变量则属对象私有,某一个对象将其值改变,不影响其他对象。类变量是公共变量
#!/usr/bin/env python class Test(object): num_of_instance = 0 # 类变量 def __init__(self, name): self.name = name # 实例变量 Test.num_of_instance += 1 if __name__ == ‘__main__‘: print Test.num_of_instance # 此时是0 t1 = Test(‘jack‘) # 调用了一次__init__,此时是1 print Test.num_of_instance t2 = Test(‘lucy‘) # 再调用了一次,此时是2 print t1.name , t1.num_of_instance print t2.name , t2.num_of_instance
1.7.2、私有实例变量以双下划线开头,其他和普通变量一样,外部访问会报错,如__myvar
1.7.3、专有变量,以双下划线开头,以双下划线结尾,是python的自有变量,不要使用这种变量,如__myvar__
2、数据类型
2.1、数字类型
2.1.1、整型(int):在32为的机器上显示的数值范围是-231~231-1,即-2147483648~2147483647,就是32位二进制数能表示的范围,在64位机器上显示的数值是-263~263-1,即-9223372036854775808~9223372036854775807,就是32位二进制数能表示的范围,可以使用int函数进行转换,如:a=‘1‘,int(a),也可以int(a, base=10),这里的base虽然是转为十进制,但是前提是a是10进制数,比如int(‘0b1010‘, base=2),0b开头的是二进制数,这样才可以转换成二进制数,整型在内存中产生是通过int类,比如a=15,是a=15--->调用int类int(10)--->调用int类下的__init__方法
2.1.2、长整型(long):c语言中的长整型有位宽限制,而python没有位宽限制,但是由于内存的原因,数值不能无限放大,从2.2版本起,如果发生溢出,将自动转换为长整型,不加L也没有关系
2.1.3、浮点型(float):主要是用来处理实数的,就是有小数点的数,在python中占64位,实数是有限小数和无限循环小数的集合(不包括无限不循环小数)
2.1.4、复数(complex):是由实数和虚数组成的,虚数就是一些不是实际存在的数,虚数的单位是i,规定i2=-1
2.2、布尔型
布尔型只有两个值,就是真和假,0和1,0是假,1是真,在python中返回true为真,false为假,内置函数为bool()
2.3、字符串
2.3.1、字符串用单引号或双引号,这两种方式没有任何区别,使用时如果字符串中有单引号,则需要使用双引号括起字符串,反之亦然,也可以用三引号来扩起来多行字符串,打印是也按照多行来打印
2.3.2、字符串的拼接可以使用加号或是格式化方式,建议使用格式化方式,如果使用加号美每加一次,就会在内存中多开辟一块空间,格式化中%s是字符串,%d是整数%f是浮点型
2.3.3、字符串常用的方法有移除空白(strip)、分割(split)、长度(len)、索引(index)、切片
2.4、列表
2.4.1、创建列表,一下两种都可以创建列表
l = [‘a1‘,‘b2‘,‘c3‘,‘d4‘] l = list([‘a1‘,‘b2‘,‘c3‘,‘d4‘])
2.4.2、索引,l.index(‘b2‘),返回b2所在的位置
2.4.3、切片,l[1:3],返回[‘b2‘,‘c3‘],如果只写开始位置,比如l[3:],就是从3的位置返回到最后,只写结束,就是从开头返回到结束的位置,都不写,返回整个列表,负数是从有到左数,如l[0:-2],返回[‘a1‘,‘b2‘],也可以加步长,比如只输出偶数的索引所对应的值,l[0:3:2],2就是步长
2.4.4、追加,使用l.append(value),可追加到列表的最后
2.4.5、插入,使用l.insert(索引,字符串),索引指的是要插入的位置,插入位置的原字符串及之后的位置全都加1
2.4.6、删除,可以使用del l[索引],可以使用l.remove[字符串],也可以使用l.pop()可以删除最后一个值,并返回该值
2.4.7、查找字符串,l.index[要查找的字符串,开始位置,结束位置],开始位置和结束位置不是必填,意思就是比如列表中有10个值,要查找a1这个字符串,开始位置是3,结束位置是8,就是在3到8的位置内查找a1,其他位置有a1也不会查找,如果列表中有重复的字符串,则显示第一个查找到的位置
2.4.8、统计字符串在一个列表中的个数,l.count()
2.4.9、排序,l.sort(),按照字符集中的顺序进行排序
2.4.10、反转,l.reverse()
2.5元组、
2.6字典、
三、字符集
1、二进制和ascll的由来
计算机只识别二进制数据,就是0和1,只有一位时只能表示0和1,所以要使用更多位数表示,规定8个二进制位是一个字节(共可以表示256种字符),最开始字符集合是ascll码,ascll码分为两部分,由于计算机是美国人发明的,所以他们在计算机中一共定义了128个字符,就是ascll的前半张表,后半张表是空的,留给其他国家使用
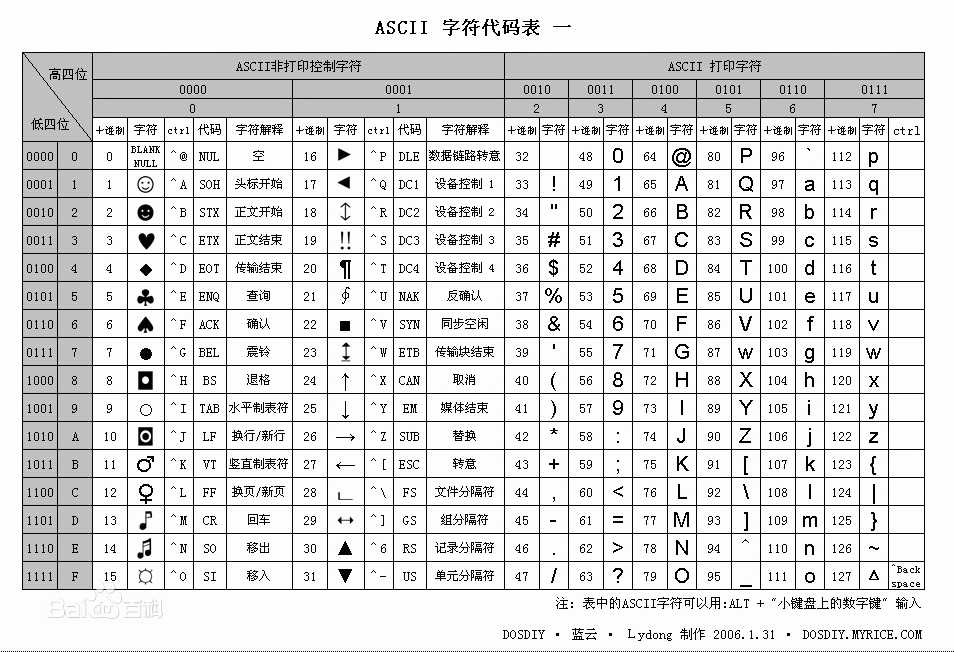
2、中文字符集的演变
剩下的128个字符空间根本不够汉字的使用,之后用了一个办法,就是如果读到了一个字节是表示汉字的(并不是实际存储汉字,只是一个空间),就把这个空间映射出一张表,这张表才是存储的真正的汉字,这样就可以用很少的空间来表示很多的字符,而这个首先产生的就是GB2312和表示繁体中的big5,GB2312一共收录了7445个字符,包括6763个汉字和682个其它符号,之后又完善了字符集,出现了GBK,收录了21886个符号,它分为汉字区和图形符号区,汉字区包括21003个字符,最后出现了GB18030,收录了27484个汉字
3、万国码
很多国家都是用的自己的字符集,这样对于程序的移植性不是很好,就需要把这些字符全部收集起来,组成了万国码,就是unicode,但是unicode太占用存储空间,因为ascll只要1个字节,就是8个二进制位就是可以存储,而unicode最少的字符都需要2个字节,所以有的国家就不同意了,然后就演变成了UTF-16,虽然比unicode要节省一些空间,但还是有国家不满意,最后演变成了UTF-8,所有的字符和符号进行分类:ascii码中的内容用1个字节保存、欧洲的字符用2个字节保存,东亚的字符用3个字节保存
4、python2和python所使用的字符集
python2默认的是使用ascll码,使用中文时需要指定字符集,而python3默认的编码是UTF-8,在使用中文的可以直接使用,不用去指定字符集
四、注释
1、单行注释可以使用#号写在要注释的行开头
2、多行注释可以使用三引号来注释,其实就是上面提到过的字符串多行的表示,只是没有赋给变量而已,在pycharm中选中要注释的行,使用ctrl+/也可以进行多行注释,就是在每一行前面加上#号
五、运算符
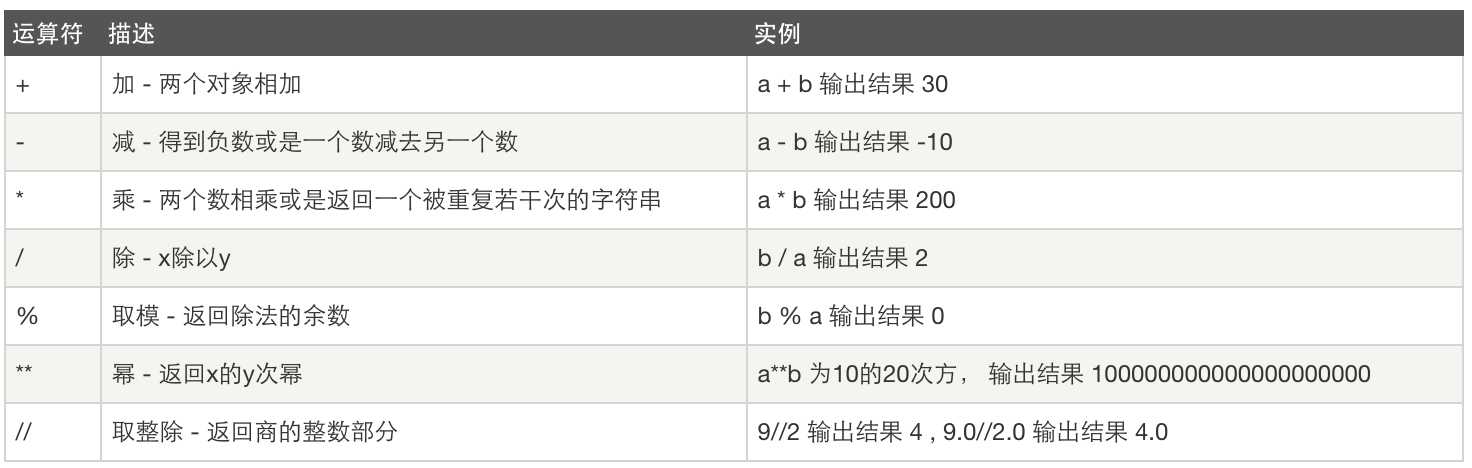
2、比较运算:

3、赋值运算:
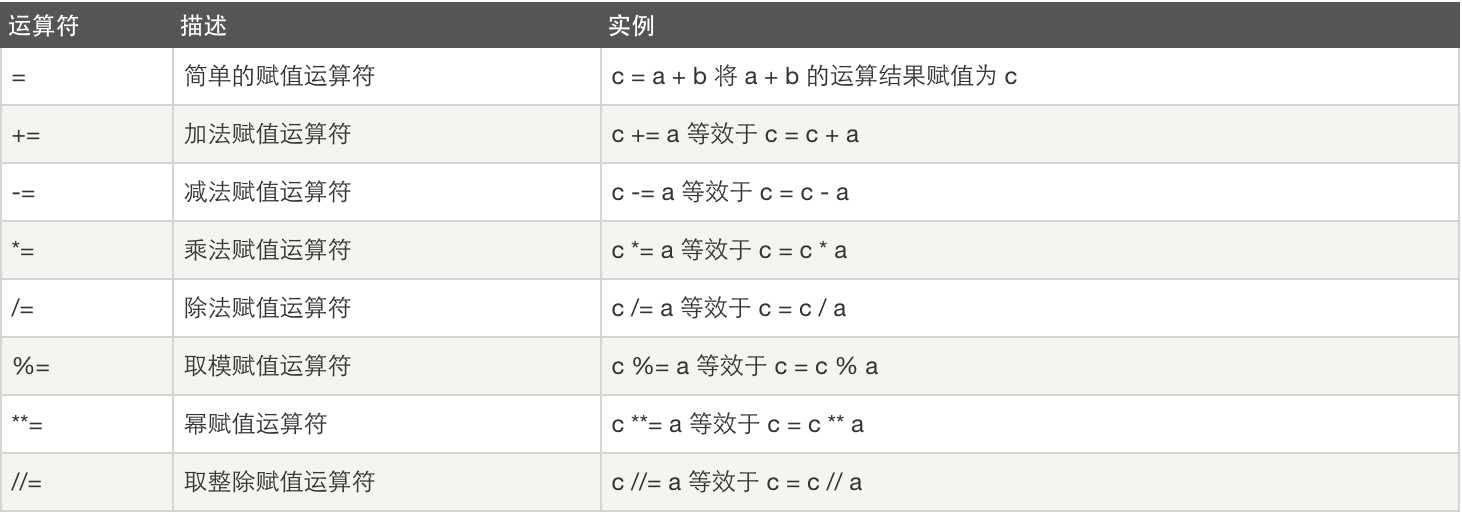
4、逻辑运算:

5、成员运算:

6、身份运算:

7、位运算:
a = 60 60 = 0011 1100
b = 13 13 = 0000 1101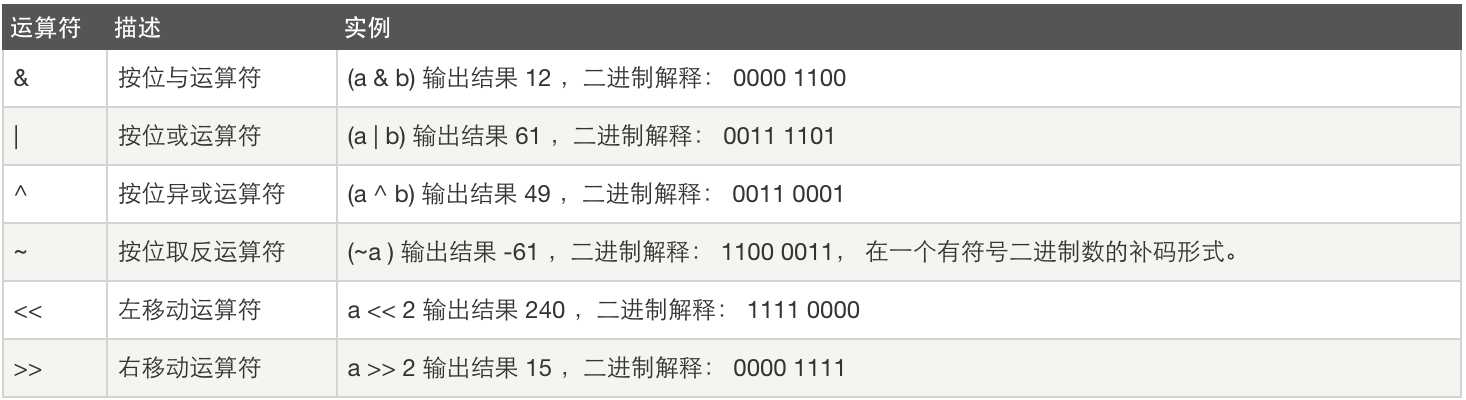
7.1、按位与运算就是两个数的二进制的同一位都为1时则为1,比如149(10010101)和201(11001001),运算后就是129(10000001)
7.2、按位或运算就是两个数的二进制的同一位有一位为1就是1
7.3、按位异或运算,两个数的二进制的同一位均为0或1则结果中该位为0,不一致则为1
7.4、按位取反运算,是针对一个数的运算,有符号采用补码形式,是针对一个数的运算,即把该数的二进制形式,是0的位为1,是1的位为0
7.5、左移动运算符,每一个二进制位都向左移动,右面补0
7.6、右移动运算符,每一个二进制位都向右移动
标签:重复 访问 单行 oat 数据类型 glob 自动 数据 span
原文地址:http://www.cnblogs.com/zcjblog/p/6262055.html